一旦提到自然语言处理,想必大家都会接触到经典模型Word2vec,他是根据词语的上下文位置用来将单词矢量化的一个模型,已经被证明所转换的单词具有语义话意义,平时我们在处理文本数据时,经常会遇到数据稀疏导致训练困难的问题,举个例子,有三个单词,dog,cat,bird,如果按找平常one-hot的思维,那么会被转换成如下形式
| dog | cat | bird | |
| 1 | 0 | 0 | |
| 0 | 1 | 0 | |
| 0 | 0 | 1 |
试想一下,若语料库有几十万个单词,那么按如上转换方法矩阵的维度会有多大,并且矩阵中大部分数据都是0,这种情况我们称为稀疏矩阵,在训练上处理起来非常困难(你的内存会爆[微笑]),接着我们的google工程师出马了,怎么办呢,压缩呀!把矩阵维度要给搞下来啊,这个过程官方称为Distributed representation(分布式表达),它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。在上面的基础上稍微解释一样,所谓分布式表达就是找到一列通俗的向量去衡量这些词,例如用腿的数量去衡量dog,cat,bird,数字越大代表腿越多,这个是我随便举的一个,意会一下就行。
| dog | cat | bird | |
| 腿的数量 | 0.8 | 0.8 | 0.5 |
| 行走的速度 | 0.5 | 0.6 | 0.7 |
接下来进入正题了,word2vec分为CBOW和SG模型,先从CBOW开始说
1.CBOW
1.1 一个单词的文本

如图上为最简单的通过一个单词通过one-hot(形式为{x1,x2,...xv})作为输入,有
![]()
Vwi即是输入单词Wi的向量表示。
隐藏层---->输出层
有另一个N*V的权重矩阵W'={W'ij},通过这个权重矩阵,我们可以计算词汇表中每个单词的得分Uj
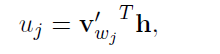
接着就可以使用softmax来得到单词的后验分布

基于上述公式可得到

Vw和V‘w都是单词w的两种表示,Vw来自w矩阵的行,V’w来自矩阵W’的列,在随后分析中我们将 Vw称为单词w的输入向量,V’w为单词w的输出向量。
隐藏层---->输出层的权重更新公式

其中j*是输出层中实际单词的索引,uj是词汇中第j个单词的得分
所以损失函数是
![]()

其中tj=1(j=j*),当且仅当第j个单元是真实输入单词时tj=1,否则tj=0,这个导数ej表示输出层第j个单词的预测误差。
接下来,我们利用w'ij的导数求出隐藏层--->输出层的梯度

再通过随机梯度下降,我们得到输出权重的更新公式

输入层---->隐藏层的权重更新公式

接下来,计算E对w的导数,回想起隐藏层对输入层的值进行线性计算


我们得到V*N矩阵,X中只有一个元素是非零的,E对W的偏导中只有一列是非零的,那一列的值为EH^T,N维向量得到W的更新等式

Vwi是W中一行,唯一单词的输入向量,并且是W的导数中唯一一行非0的,W中其它行在接下来迭代中都不会改变,因为他们的的导数都是0.
1.2 多词文本(Multi-word Context)
CBOW的核心即是输入某个特定单词的上下文单词向量,输出这个特定单词的向量

根据上述说的输入一个单词情况理论,我们容易推出多词向量情况,隐藏层为权重乘向量相加取平均

C为文本中单词数量,其损失函数为

2.Skip-Gram Model
skip-gram模型和CBOW模型刚好相反,其输入为特定单词向量,输出为其单词的上下文单词向量


在输出层,不止输出一个多项式分布,输出C个多项式分布,每一个输出通过同一个隐藏-输出矩阵计算

Wc,j是输出层的C块的第j个单词,Wo,c是输出上下文中第C个词,Wi是唯一的输入单词,Yc,j是输出层中第C块的第j个单元的输出,Uc,j是输出层中第C块j单元的净输入,由于输出块使用同样的权重,那么
![]()
其中V’wj是词汇表中第j个单词的输出向量,并且V'wj是W‘权重矩阵的一列 。
其损失函数为

3.写在最后
平时在使用gensim等工具训练词向量的时候,我们关心的并不是训练网络的输出,而是训练过程中的副产物权重作为我们的词向量embedding,即上面所提的输入向量和输出向量,一般我们都是采用输入向量,有些人也会取输入向量和输出向量的平均作为词向量。
参考论文:word2vec Parameter Learning Explained
