本文是个人对 word2vec 的理解,绝大部分翻译自 Xin Rong 博士的 paper,同时参考了网上很多blogs,都列在References中了。
注:文中数学公式,不加粗小写代表标量值,加粗小写代表向量,加粗大写代表矩阵。
1. word2vec 简介
Word2Vec是Google在2013 年开源的一个词向量(Word Embedding)计算工具,其用来解决单词的分布编码问题。它通过从大量文本预料中以无监督方式学习语义知识型,被广泛地应用于自然语言处理中。
2. 什么是 word embedding(词嵌入)
我们知道,文本是一种非结构化的数据信息,如汉字是一种方块字,是不可以直接被计算的。因此需要将这种非结构化的信息转换为结构化的信息,从而实现针对文本信息进行计算。简单来说,就是把文字转换成数学向量。
这种表示方法很多,常见的有如下三种:
- 独热编码 | one-hot representation
- 整数编码
- 词嵌入 | word embedding
所谓独热码就是开一个和词汇表大小相同的向量,向量的一个位置就代表了一个单词,例如,假设单词表中只有四个单词,我、爱、中、国,那么一个可能的编码为:
我:[1 0 0 0]
爱:[0 1 0 0]
中:[0 0 1 0]
国:[0 0 0 1]
但是在实际情况中,文本中很可能出现成千上万个不同的词,这时候向量就会非常长。其中99%以上都是 0,导致所谓的维度灾难。
整数编码更简单,就是用一个整数代表一个词,如1代表我,2代表爱,等等。
整数编码的缺点如下:
- 无法表达词语之间的关系
- 对于模型解释而言,整数编码可能具有挑战性。
word embedding 则是文本表示的一类方法。他可以将文本通过一个低维向量来表达,不像 one-hot 那么长。并且语意相似的词在向量空间上也会比较相近。而Word2vec则是一种基于统计方法来获得词嵌入的方法,2013年由谷歌的 Mikolov 提出。
Word2vec 算法有2种训练模式(2 种网络结构,CBOW和Skip-Gram):
- CBOW(Continuous Bag-of-Word Model):用单词的上下文预测当前单词
- Skip-gram:当前词预测其上下文
首先要说明,word2vec 本质上是一个神经网络,其输入是 单词的 one-hot 向量,输出是待预测单词的 one-hot 向量(并不是所谓的word embedding),而单词的真正的词嵌入表示是蕴含在在网络的参数中的。
下面分别写一下自己的理解,其中大部分都是来自 Xin Rong 博士在论文 word2vec Parameter Learning Explained 中所解释的。
3. CBOW
CBOW 是用上下文预测当前的单词,也就是输入是多个上下文的单词,输出为待预测的一个单词。首先,为了简便,我们将输入的上下文单词设置为一个。
3. 1 One-word context
此时模型输入一个单词,预测一个单词。下图显示了网络的结构:
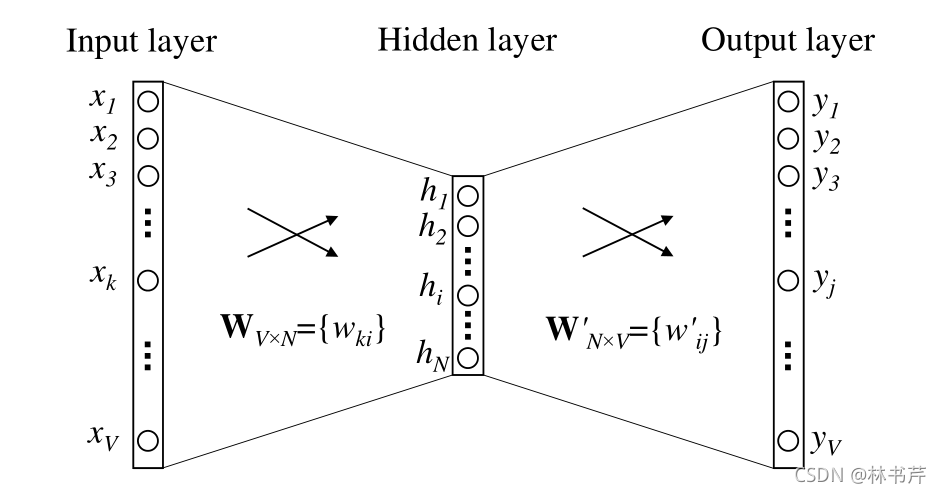
其实网络结构很简单,图中就只有一个隐藏层,且隐藏层没有激活函数,输出层有Softmax函数,即输出预测单词的概率分布,概率大的就被预测出来了。我们假设,单词表的长度为 V V V,即一共有 V V V 个单词。隐藏层的节点数为 N N N,输出层的节点数和输入层一样也是 V V V,因为就是要输出每个单词出现的概率,而真值就是该被预测的单词的one-hot,那么整个网络就是要训练成,输出尽可能接近待预测单词的one-hot。
输入层和隐藏层之间为全连接网络,由于没有激活函数,其输入输出关系很简单:
h = W T x = v I T \mathbf{h}=\mathbf{W}^{T} \mathbf{x}=\mathbf{v}_I^T h=WTx=vIT
其中, x \mathbf{x} x 是一个 V × 1 V \times 1 V×1 的列向量。 W \mathbf{W} W 是一个 V × N V \times N V×N 矩阵,那么 h \mathbf{h} h 就是一个 N × 1 N \times 1 N×1 的列向量。由于 x \mathbf{x} x 只有一个元素为 1 1 1 ,假设是第 k k k 维为1,其他都为 0 0 0,那么这个操作的本质是把 W \mathbf{W} W 的第 k k k 行转置之后复制给 h \mathbf{h} h,即 v I T \mathbf{ v}_I^T vIT,下标 I I I 代表 input。
同理,隐藏层和输出层之间通过一个大小为 N × V N \times V N×V 的矩阵 W ′ \mathbf{W}^\prime W′ 全连接( W ′ \mathbf{W}^\prime W′ 和 W \mathbf{W} W 没有任何关系!),设其输出为 u \mathbf{u} u,那么输出的第 j j j 个元素为:
u j = v j ′ T h u_{j}={\mathbf{v}_{j}^{\prime}}^T \mathbf{h} uj=vj′Th
其中, v j ′ T {\mathbf{v}_{j}^{\prime}}^T vj′T 代表矩阵 W ′ T {\mathbf{W}^\prime}^T W′T 的第 j j j 行(或者说,矩阵 W ′ {\mathbf{W}^\prime} W′ 的第 j j j 列 )。最后使用 Softmax 获得单词的后验概率(这里所有的概率之和加起来就等于 1 1 1 了):
p ( w j ∣ w I ) = y j = exp ( u j ) ∑ j ′ = 1 V exp ( u j ′ ) p\left(w_{j} \mid w_{I}\right)=y_{j}=\frac{\exp \left(u_{j}\right)}{\sum_{j^{\prime}=1}^{V} \exp \left(u_{j^{\prime}}\right)} p(wj∣wI)=yj=∑j′=1Vexp(uj′)exp(uj)
p ( w j ∣ w I ) p\left(w_{j} \mid w_{I}\right) p(wj∣wI) 代表给定输入单词,预测输出第 j j j 个单词的概率。代入 u j u_j uj,有,
p ( w j ∣ w I ) = exp ( v j ′ v I ) ∑ j ′ = 1 V exp ( v j ′ ′ T v I ) p\left(w_{j} \mid w_{I}\right)=\frac{\exp \left(\mathbf{v}_{
{j}}^{\prime} \mathbf{v}_{
{I}}\right)}{\sum_{j^{\prime}=1}^{V} \exp \left(\mathbf{v}_{
{j^{\prime}}}^{\prime}{ }^{T} \mathbf{v}_{
{I}}\right)} p(wj∣wI)=∑j′=1Vexp(vj′′TvI)exp(vj′vI)
我们假设预测真值出现在第 j ∗ j^* j∗ 个位置,则预测输出应该是 t j ∗ \mathbf{t}_{j^*} tj∗ 是一个 one-hot向量,并且只在第 j ∗ j^* j∗ 个位置有一个 1 1 1,其他位置都是 0 0 0,那么,我们目的是想让 输出 y \mathbf{y} y 的第 j ∗ j^* j∗ 个位置的值越大越好(尽可能接近 t j ∗ \mathbf{t}_{j^*} tj∗ ),其他位置的值越小越好,
max p ( w O ∣ w I ) = max y j ∗ = max log y j ∗ = u j ∗ − log ∑ j ′ = 1 V exp ( u j ′ ) : = − E , \begin{aligned} \max p\left(w_{O} \mid w_{I}\right) &=\max y_{j^{*}} \\ &=\max \log y_{j^{*}} \\ &=u_{j^{*}}-\log \sum_{j^{\prime}=1}^{V} \exp \left(u_{j^{\prime}}\right):=-E, \end{aligned} maxp(wO∣wI)=maxyj∗=maxlogyj∗=uj∗−logj′=1∑Vexp(uj′):=−E,
其中, E = − log p ( w O ∣ w I ) E=-\log p\left(w_{O} \mid w_{I}\right) E=−logp(wO∣wI) 是损失函数,要使得上述的概率最大,那就是最小化 E E E。
因此,对上式进行反向传播即可更新参数如下,
∂ E ∂ w i j ′ = ∂ E ∂ u j ⋅ ∂ u j ∂ w i j ′ = ( y j − t j ) ⋅ h i v j ′ (new) = v j ′ (old) − η ⋅ ( y j − t j ) ⋅ h for j = 1 , 2 , ⋯ , V \frac{\partial E}{\partial w_{i j}^{\prime}}=\frac{\partial E}{\partial u_{j}} \cdot \frac{\partial u_{j}}{\partial w_{i j}^{\prime}} =(y_{j}-t_{j})\cdot h_{i} \\ {\mathbf{v}_{
{j}}^{\prime}}^\text {(new)}={\mathbf{v}_{
{j}}^{\prime}} ^\text { (old)}-\eta \cdot (y_{j}-t_{j}) \cdot \mathbf{h} \quad \text { for } j=1,2, \cdots, V ∂wij′∂E=∂uj∂E⋅∂wij′∂uj=(yj−tj)⋅hivj′(new)=vj′ (old)−η⋅(yj−tj)⋅h for j=1,2,⋯,V
y j , t j , h i y_{j}, t_{j},h_{i} yj,tj,hi 分别代表向量 y , t , h \mathbf{y,t,h} y,t,h 的第 j , j , i j,j,i j,j,i 个元素, w i j w_{i j} wij 代表矩阵 W ′ {\mathbf{W}^\prime} W′ 第 i i i 行第 j j j 列元素, η \eta η 是学习率。
同理,更新 W \mathbf{W} W 过程如下,我们首先求 E E E 对 h i h_i hi 的导数如下:
∂ E ∂ h i = ∑ j = 1 V ∂ E ∂ u j ⋅ ∂ u j ∂ h i = ∑ j = 1 V ( y j − t j ) ⋅ w i j ′ : = E H i \frac{\partial E}{\partial h_{i}}=\sum_{j=1}^{V} \frac{\partial E}{\partial u_{j}} \cdot \frac{\partial u_{j}}{\partial h_{i}}=\sum_{j=1}^{V} (y_{j}-t_{j}) \cdot w_{i j}^{\prime} :=\mathrm{EH}_{i} ∂hi∂E=j=1∑V∂uj∂E⋅∂hi∂uj=j=1∑V(yj−tj)⋅wij′:=EHi
: = := := 表示记为。
参数定义同上。下一步就可以算出 E E E 对 W W W 的偏导数,这里要注意,因为input layer的操作是, W \mathbf{W} W 的第 k k k 行转置之后复制给 h \mathbf{h} h,也就是说, h i = w k i h_i = w_{ki} hi=wki,其中的 k k k 代表输入 one-hot 向量的第 k k k 个元素是 1 1 1,其他都是 0 0 0,因此我们更新 W \mathbf{W} W 的时候只要更新第 k k k 行,其他的值由于梯度是 0 0 0,保持不变:
∂ E ∂ w k i = ∂ E ∂ h i ⋅ ∂ h i ∂ w k i = ∑ j = 1 V ( y j − t j ) ⋅ w i j ′ = E H i ⋅ x k for w is a constant, i = 1 , 2 , ⋯ , N \frac{\partial E}{\partial w_{k i}}=\frac{\partial E}{\partial h_{i}} \cdot \frac{\partial h_{i}}{\partial w_{k i}} = \sum_{j=1}^{V} (y_{j}-t_{j}) \cdot w_{i j}^{\prime}=\mathrm{EH}_{i} \cdot x_{k} \quad \text{for } w \text{ is a constant, } i=1,2, \cdots,N ∂wki∂E=∂hi∂E⋅∂wki∂hi=j=1∑V(yj−tj)⋅wij′=EHi⋅xkfor w is a constant, i=1,2,⋯,N
向量形式表示更新如下:
v I ( new ) = v I (old) − η E H T \mathbf{v}_{
{I}}^{(\text {new })}=\mathbf{v}_{
{I}}^{\text {(old) }}-\eta \mathrm{EH}^{T} vI(new )=vI(old) −ηEHT
同样也是只更新 W \mathbf{W} W 的第 k k k 行,其他行保持不变。
3.2 Multi-word context
现在我们把模型拓展到有多个上下文单词输入的情况,下图显示了一个 Multi-word context 的 CBOW 模型,

此时,在计算隐藏层输出时,CBOW 模型不直接复制输入上下文的输入向量,而是取输入上下文向量的平均值,并使用输入到隐藏层权值矩阵的乘积的平均向量作为输出:
h = 1 C W T ( x 1 + x 2 + ⋯ + x C ) = 1 C ( v w 1 + v w 2 + ⋯ + v w C ) T \begin{aligned} \mathbf{h} &=\frac{1}{C} \mathbf{W}^{T}\left(\mathbf{x}_{1}+\mathbf{x}_{2}+\cdots+\mathbf{x}_{C}\right) \\ &=\frac{1}{C}\left(\mathbf{v}_{w_{1}}+\mathbf{v}_{w_{2}}+\cdots+\mathbf{v}_{w_{C}}\right)^{T} \end{aligned} h=C1WT(x1+x2+⋯+xC)=C1(vw1+vw2+⋯+vwC)T
其中, C C C 是上下文单词的数量(在 One-word context 中, C = 1 C=1 C=1), w 1 , ⋯ , w C w_{1}, \cdots, w_{C} w1,⋯,wC 是上下文的单词向量, v 1 , ⋯ , v C \mathbf{v}_1,\cdots, \mathbf{v}_C v1,⋯,vC 同上。损失函数定义如下:
E = − log p ( w O ∣ w I , 1 , ⋯ , w I , C ) = − u j ∗ + log ∑ j ′ = 1 V exp ( u j ′ ) = − v O ′ ⋅ h + log ∑ j ′ = 1 V exp ( v j ′ T ⋅ h ) \begin{aligned} E &=-\log p\left(w_{O} \mid w_{I, 1}, \cdots, w_{I, C}\right) \\ &=-u_{j^{*}}+\log \sum_{j^{\prime}=1}^{V} \exp \left(u_{j^{\prime}}\right) \\ &=-\mathbf{v}_{
{O}}^{\prime} \cdot \mathbf{h}+\log \sum_{j^{\prime}=1}^{V} \exp \left(\mathbf{v}_{
{j}}^{\prime}{ }^{T} \cdot \mathbf{h}\right) \end{aligned} E=−logp(wO∣wI,1,⋯,wI,C)=−uj∗+logj′=1∑Vexp(uj′)=−vO′⋅h+logj′=1∑Vexp(vj′T⋅h)
由于隐藏层到输出向量部分没有改变,因此 W ′ {\mathbf{W}}^\prime W′ 的更新和之前一样:
v j ′ (new) = v j ′ (old) − η ⋅ ( y j − t j ) ⋅ h for j = 1 , 2 , ⋯ , V {\mathbf{v}_{
{j}}^{\prime}}^\text {(new)}={\mathbf{v}_{
{j}}^{\prime}} ^\text { (old)}-\eta \cdot (y_{j}-t_{j}) \cdot \mathbf{h} \quad \text { for } j=1,2, \cdots, V vj′(new)=vj′ (old)−η⋅(yj−tj)⋅h for j=1,2,⋯,V
W \mathbf{W} W 的更新其实也差不多,只不过我们需要对上下文中的每个单词 w I , c w_{I,c} wI,c 应用以下等式:
v I , c ( n e w ) = v I , c ( old ) − 1 C ⋅ η ⋅ E H T for c = 1 , 2 , ⋯ , C \mathbf{v}_{
{I, c}}^{(\mathrm{new})}=\mathbf{v}_{
{I, c}}^{(\text {old })}-\frac{1}{C} \cdot \eta \cdot \mathrm{EH}^{T} \quad \text { for } c=1,2, \cdots, C vI,c(new)=vI,c(old )−C1⋅η⋅EHT for c=1,2,⋯,C
其中, v I , c \mathbf{v}_{
{I, c}} vI,c 是输入上下文中第 c c c 个单词的输入向量,或者说,对应矩阵 W \mathbf{W} W 的第 k c k_c kc 行,其中 k c k_c kc 为输入第 c c c 个单词在 one-hot 编码中不为 0 0 0 的那一维。
如,上下文单词中,第一个单词 c = 1 c=1 c=1 为"我", V = 4 V=4 V=4,编码为 [ 1 0 0 0 ] [1 \ 0 \ 0 \ 0] [1 0 0 0],那么, k 1 = 0 k_1 = 0 k1=0;上下文单词中,第二个单词 c = 2 c=2 c=2 为"国", V = 4 V=4 V=4,编码为 [ 0 0 0 1 ] [0 \ 0 \ 0 \ 1] [0 0 0 1],那么, k 2 = 3 k_2 = 3 k2=3。
4. Skip-Gram Model
下图显示了 Skip-Gram Model 结构:
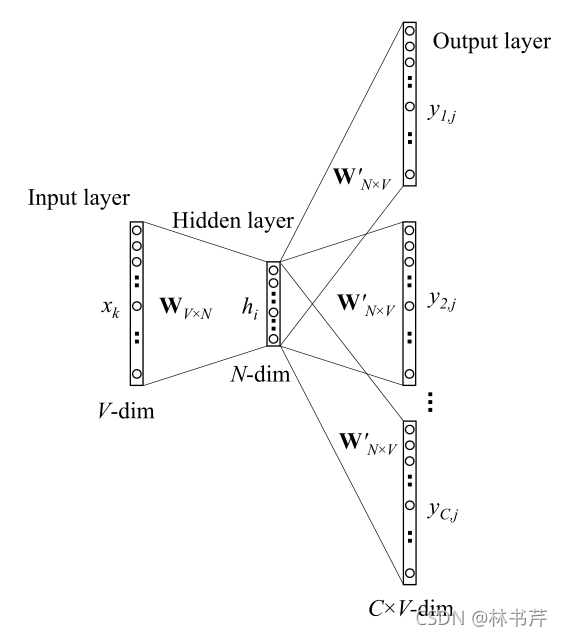
Skip-Gram Model 的参数更新方程的推导与one-word-context model 没有太大区别。损失函数变成了:
E = − log p ( w O , 1 , w O , 2 , ⋯ , w O , C ∣ w I ) = − log ∏ c = 1 C exp ( u c , j c ∗ ) ∑ j ′ = 1 V exp ( u j ′ ) = − ∑ c = 1 C u j c ∗ + C ⋅ log ∑ j ′ = 1 V exp ( u j ′ ) \begin{aligned} E &=-\log p\left(w_{O, 1}, w_{O, 2}, \cdots, w_{O, C} \mid w_{I}\right) \\ &=-\log \prod_{c=1}^{C} \frac{\exp \left(u_{c, j_{c}^{*}}\right)}{\sum_{j^{\prime}=1}^{V} \exp \left(u_{j^{\prime}}\right)} \\ &=-\sum_{c=1}^{C} u_{j_{c}^{*}}+C \cdot \log \sum_{j^{\prime}=1}^{V} \exp \left(u_{j^{\prime}}\right) \end{aligned} E=−logp(wO,1,wO,2,⋯,wO,C∣wI)=−logc=1∏C∑j′=1Vexp(uj′)exp(uc,jc∗)=−c=1∑Cujc∗+C⋅logj′=1∑Vexp(uj′)
由于 Skip-Gram Model 是给定一个输入单词,预测其上下文多个单词的概率,所以损失函数变成 p ( w O , 1 , w O , 2 , ⋯ , w O , C ∣ w I ) p\left(w_{O, 1}, w_{O, 2}, \cdots, w_{O, C} \mid w_{I}\right) p(wO,1,wO,2,⋯,wO,C∣wI) 的负对数。其中, j c ∗ j_{c}^{*} jc∗ 是词汇表中第 c c c 个上下文输出单词在 one-hot 编码中不为 0 0 0 的那一维(解释同上)。
由于有多个输出,我们求损失 E E E 对每个输出向量的每个维度的偏导如下:
∂ E ∂ u c , j = y c , j − t c , j : = e c , j \frac{\partial E}{\partial u_{c, j}}=y_{c, j}-t_{c, j}:=e_{c, j} ∂uc,j∂E=yc,j−tc,j:=ec,j
: = := := 是将 y c , j − t c , j y_{c, j}-t_{c, j} yc,j−tc,j 记为 e c , j e_{c, j} ec,j
为了表示简便,我们再记:
E I j = ∑ c = 1 C e c , j \mathrm{EI}_{j}=\sum_{c=1}^{C} e_{c, j} EIj=c=1∑Cec,j
和前面一样, c c c 代表输出上下文的个数。下一步求 E E E 对 W ′ {\mathbf{W}}^\prime W′ 中元素的偏导数,并更新:
∂ E ∂ w i j ′ = ∑ c = 1 C ∂ E ∂ u c , j ⋅ ∂ u c , j ∂ w i j ′ = E I j ⋅ h i \frac{\partial E}{\partial w_{i j}^{\prime}}=\sum_{c=1}^{C} \frac{\partial E}{\partial u_{c, j}} \cdot \frac{\partial u_{c, j}}{\partial w_{i j}^{\prime}}=\mathrm{EI}_{j} \cdot h_{i} ∂wij′∂E=c=1∑C∂uc,j∂E⋅∂wij′∂uc,j=EIj⋅hi
则更新如下:
w i j ′ ( new ) = w i j ′ (old) − η ⋅ E I j ⋅ h i w_{i j}^{\prime}(\text { new })=w_{i j}^{\prime} \text { (old) }-\eta \cdot \mathrm{EI}_{j} \cdot h_{i} wij′( new )=wij′ (old) −η⋅EIj⋅hi
或者向量形式表示:
v j ′ (new) = v j ′ (old) − η ⋅ E I j ⋅ h for j = 1 , 2 , ⋯ , V \mathbf{v}_{
{j}}^{\prime} \text { (new) }=\mathbf{v}_{
{j}}^{\prime} \text { (old) }-\eta \cdot \mathrm{EI}_{j} \cdot \mathbf{h} \quad \text { for } j=1,2, \cdots, V vj′ (new) =vj′ (old) −η⋅EIj⋅h for j=1,2,⋯,V
可以看出,除了损失函数,其他的和 one-word-context model 几乎没有区别。
最后求输入层到隐藏层的权值矩阵的更新方程。由于从结构上可以看出,他和 one-word-context model 完全一样,所以我们直接给出更新方程如下:
v I ( new ) = v I ( old ) − η ⋅ E H T \mathbf{v}_{
{I}}^{(\text {new })}=\mathbf{v}_{
{I}}^{(\text {old })}-\eta \cdot \mathrm{EH}^{T} vI(new )=vI(old )−η⋅EHT
其中, E H EH EH 是一个 n n n 维向量,向量中的每一个元素为:
E H i = ∑ j = 1 V E I j ⋅ w i j ′ \mathrm{EH}_{i}=\sum_{j=1}^{V} \mathrm{EI}_{j} \cdot w_{i j}^{\prime} EHi=j=1∑VEIj⋅wij′
5. 最后
我们观察公式:
v j ′ (new) = v j ′ (old) − η ⋅ ( y j − t j ) ⋅ h for j = 1 , 2 , ⋯ , V {\mathbf{v}_{
{j}}^{\prime}}^\text {(new)}={\mathbf{v}_{
{j}}^{\prime}} ^\text { (old)}-\eta \cdot (y_{j}-t_{j}) \cdot \mathbf{h} \quad \text { for } j=1,2, \cdots, V vj′(new)=vj′ (old)−η⋅(yj−tj)⋅h for j=1,2,⋯,V
word2vec 在更新过程中需要变量一边词汇表中的所有的单词,对于每一步的更新,我们还要计算 w j , u j , y j , e j w_j,u_j, y_j, e_j wj,uj,yj,ej 最终才能更新一个 v j ′ {\mathbf{v}_{
{j}}^{\prime}} vj′,计算量可想而知。所有在实际的 word2vec 中,使用了很多 tricks 优化计算效率,具体不再展开,推荐 References 中的博客和这一篇博客。