前言
近两年来由Mikolov等人提出的word2vec模型和应用引起了社会的极大的关注。使用word2vec模型学习的单词的向量表示已经被证明能够携带语义信息,且在各种NLP任务中都是有用的。越来越多的研究人员希望尝试使用word2vec,但我注意到对于word2vec参数学习过程目前还缺乏一个全面解释的资料,因此限制了许多神经网络方面了解不深的人去理解word2vec的工作原理。
本文提供了word2vec模型的参数更新方程的详细推导和解释,包括原始的连续词袋(CBOW)模型和skip-gram模型,以及一些高级技巧--分层的soft-max和负抽样。
在阅读前你需要一些基础知识:
1 Continuous Bag-of-Word Model(CBOW)
1.1 One-word context (只考虑目标单词前面一个单词的情况)
我们从Mikolov等人最简单版本的连续词袋模型(CBOW)开始介绍。连续词袋模型做出这样的假设一个单词出现的可能性与其上下文的单词组成有关,这意味着对于CBOW模型我们可以通过给定的上下文单词环境来预测一个目标单词,就像一个二元模型。
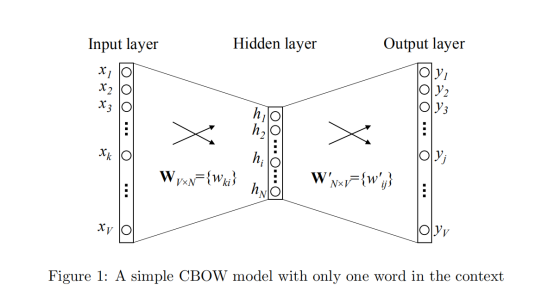
图一为简化的通过上下文来定义词向量的网络模型,我们设置词汇量的大小为V,隐藏层的大小为N,相邻层上的节点完全连接。输入向量是一个one-hot编码的向量,对于给定的输入上下文单词,one-hot编码中每个单词的向量表示为,其中只有一个节点
为1,而所有其他节点为0。
输入层和输出层之间的权重可以由的矩阵
表示。
其中矩阵的每一行代表的是一个与输入层相关的单词的
维向量表示形式
。那么假设我们给定了一个输入单词,其单词向量的第
个元素
,其余
,则有:
(1)

向量完全是由
矩阵第
行计算出来的 (因为除
外,其余
都为0),
是输入字
的向量表示。
分析完输入层到隐藏层之后,我们再看隐藏层到输出层,有一个新的的权重矩阵,它也是一个
矩阵。使用这些权重
,我们可以计算词汇表中每个单词的分数
:
(2)
其中是矩阵
的第
列,然后我们使用一个满足多项式分布的对数线性分类模型soft-max来获取单词的后验概率。
(3)
其中是输出层中
节点的输出,我们将式子(1)和(2)代入式子(3),得到:
(4)
注意和
是单词
的两种表示方式,
是矩阵
的一行,是由输入层→隐藏层的权值矩阵。
是矩阵
的一列,是由隐藏层→输出层的权值矩阵。在之后的分析中,我们默认将
称为单词
的“input vector”,将
称为单词
的“output vector”。
更新隐藏层→输出层权重的等式
现在我们开始推到CBOW模型的权值更新方程。虽然实际的计算方式有点不切实际(之后解释),但是这不妨碍我们推到这个方程来增加我们对这个原始模型的理解。推到过程需要一些神经网络的知识基础:有关反向传播基础知识的综述,请参阅神经元网络模型和反向传播的基础知识
由上一阶段的描述可知,现在训练的目标(这节只针对一个单词)就是求公式(4)的最大值。其意在当我们给定了上下文信息以及其权值矩阵的情况下,在词汇表中计算每个词成为中心单词的概率,从而预测目标单词。
(7)
这里我们设置一个为我们的损失函数(一个最小化的目标),
是目标单词在输出层的索引。可以发现,对于这个损失函数的计算,我们可以将其理解为一种特殊情况下对2个概率分布的交叉熵测量。
现在我们来推到一下隐藏层到输出层之前的权重更新方程,首选我们对损失函数求关于
的偏导,这样得:
(8)
其中,即当且仅当输出层的第
个单词为目标单词时,
的值为1,其余情况都为0。可以看出这个导数实质上是输出层的预测误差
。
接下来我们通过链式法则来求出损失函数在上的偏导, 并通过此来计算隐藏层到输出层的梯度。
之后我们使用随机梯度下降方法,得到最终的隐藏层→输出层的权重更新方程
或者说:
(11)
其中为梯度下降算法的学习率(
) ,
,其中
是隐藏层的第
个神经元,
是输出单词
的向量表示。可以看出,通过对比输出的可能性
和期望的输出
(取值只能为0或者1)来更新权重意味着我们需要遍历词汇表中所有单词。
这个过程中:
- 当
('高估')的时候,
,那么会从
上减去隐藏向量
的一部分,这样向量
相差更远;
- 当
('低估')的时候,
,那么会从
- 当
('相近')的时候,
,那么会从
更新隐藏层→输出层权重的等式
在介绍完hidden→output的权重矩阵更新公式之后,我们接着介绍input→hidden的权重矩阵
的更新过程。在上面小节中我们解释了损失函数
,现在我们对
在
上求偏导:
(12)
其中为隐藏层上第
个神经元的输出;
,表示输出层第j个神经单元的输入;
为输出层第j个单词的预测误差。所以我们设定一个
维的向量
,它的每一个元素代表的是词汇表中的每个单词的预测误差
与词汇表中每个输出单词的向量的乘积之和。
接下来,我们需要求出损失函数关于权重矩阵
的偏导数。首先,我们知道隐藏层激活单元的输出
是输入层的值
与其权重
的线性组合,由此分解式子(1)我们可以得到:
(13)
对于权重矩阵的每一个元素
,通过式(12)和式(13),我们可以求得其在损失函数
上的偏导:
(14)
以线性代数的角度来说:
(15)
通过式(15)我们得到一个的矩阵,由于
只有一个非零值(one-hot),所以
的结果也只有一行是非零的,非零N维向量就是那一行
的值,由此我们得到权重矩阵
的更新方程:
(16)
其中是矩阵
中输入单词
(即one-hot编码中非零的哪行对应的单词)的输入向量。我们不用去关心除
外的其他行向量,因为其
的值为0,由式(14)可以看出其偏导
也为0。
经过多次迭代反向传播后,误差等于
等于
,通过式子(12)中我们知道:
由此式子(16)我们可以这样理解我们将词汇表中的每个输出向量的一部分添加到输入单词的词向量上。这样就和权值矩阵的更新类似了:
- 如果过高地估计了某个单词
作为最终输出单词的概率(即:
),则上下文单词
(context word )的输入向量与单词
- 与之相反,如果某个单词
),则单词
- 如果对于单词
由此可以发现输入单词词向量的更新取决与其与词汇表中所有单词的预测误差。预测误差越大,则目标单词(预测的单词)对于输入单词词向量的更新过程影响越大。这就是为什么word2vec可以得出‘国王’-'皇后'='男人'-'女人'的结论的原因。国王和皇后是经常一起组合出现的,男人和女人也是组合出现的,属于联想词,所以说,一个词的常规稳定的位置通常会由他的组合词,也就是经常一起出现的词决定的。所以这些最常出现的组合词就决定了目标词的更新规律
1.2 Multi-word context (考虑上下文多个单词的情况)
考虑上下文多个单词的CBOW模型如图2所示,可以发现与上一节(one-word context)不同的是, Multi-word context 会去考虑目标单词上下文的多个单词,通过这些个单词来确定目标单词出现的可能性。
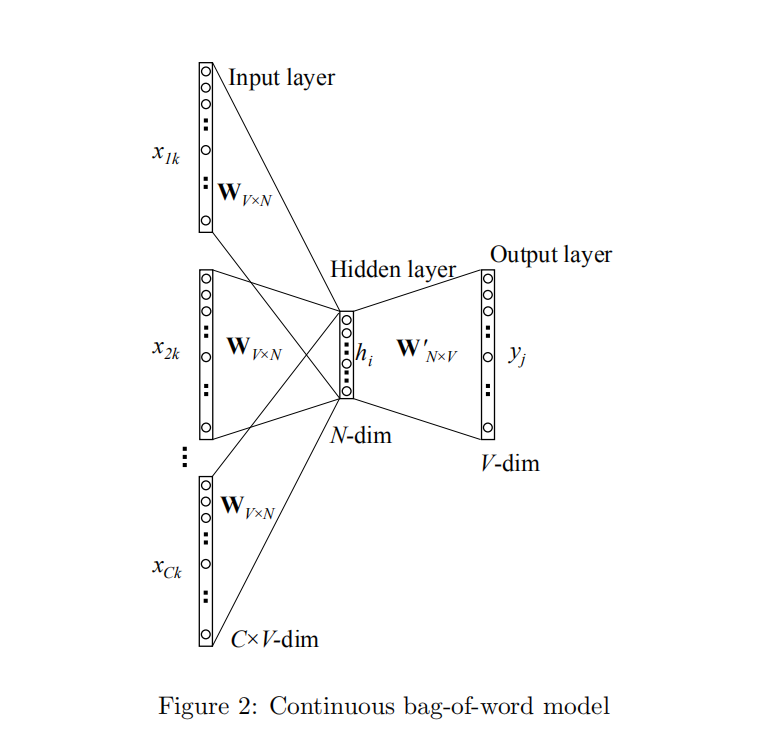
不同与之前方式,在计算Multi-word context 隐藏层的输出值的过程中,会将输入的上下文单词的向量累加起来求均值,接着使用这个均值与input→hidden的权值矩阵相乘,作为最终的结果。公式如下:
(18)
其中是上下文的单词个数,
指的是上下文的具体的单词,
是单词
的输入向量。而损失函数就转化为:
Multi-word context 的损失函数与one-word context的目的一样,公式也与(7)相同,除了用公式(18)的方式来替代了one-word context公式(1)的。
同时,Multi-word context 由隐藏层→输出层的权值矩阵的更新的过程与one-word context也是一样的。我们直接把之前的公式(11)写在下面:
(22)
通过迭代我们将遍历整个语料库,以此来更新
(隐藏层→输出层的矩阵)。
更新输入层→隐藏层权值矩阵的方程也与之前的公式(16)类似,只不过现在我们需要对上下文的每一个单词
都执行如下更新公式:
(23)
其中是输入上下文单词的第
个单词的输入向量;
表示大于零的学习率;
由公式(12)确定。
2 Skip-Gram Model
skip-gram与上一章介绍的CBOW正好相反,skip-gram是通过中心单词(target word)来预测其上下文的单词(context words)。如图3所示:
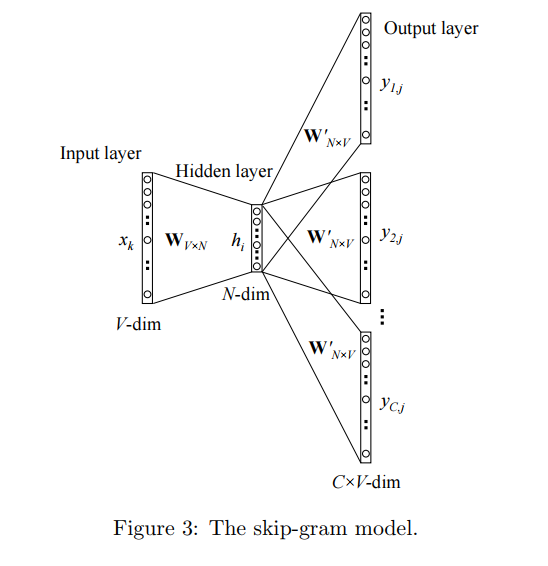
这里我们依然用来表示输入层上唯一的输入单词的向量,这样我们对于隐藏层的输出值
的计算就可以照搬使用公式(1):
这意味着只是矩阵
的其中一行。[输入
为一个one-hot向量,
转置与权值矩阵的点积,结果就为
矩阵的其中一行]。在输出层上,不同于CBOW模型输出单个多项式分布,Skip-garm模型的输出层输出多个多项式分布。每个输出都使用相同的隐藏层->输出层矩阵计算:
其中表示输出层的第c个panel的第j个单词;
实际上是输出上下文的第c的单词;
是唯一的输入单词;
是输出层第c个panel上第j个神经元节点的输出值(概率);
输出层在第c个panel上第j个节点的输出值。但由于输出层的所有panels共享同一权值矩阵
,所以:
,
*panel:输出层的表示每个上下文单词的神经元的组合
其中是词汇表中第j个单词
的输出向量, 同样,它也取自于隐藏层→输出层权值矩阵
的其中一列。
skip-gram模型参数更新的方法实际上与one-word-context模型的差别并不是很大。这里我们将损失函数变为:
其中实际上是第c个输出层输出的上下文单词在语料库中的索引。接下来,我们对输出层的每一个panel上的所有激活单元的输入值
均求其关于
的偏导数得:
和式子(8)一样,代表着输出层上每个神经元节点的预测误差。为了书写方便,我们假设一个V维度的向量
来表示所有上下文单词的预测误差之和,公式表示为:
然后我们通过链式法则来求得隐藏层→输出层的权值矩阵关于
的偏导,得:
再由此推导出隐藏层→输出层的权值矩阵的更新方程:
或者这样表示:
这个公式的直观理解与公式(11)的概念相同,除了一点:输出层的预测误差的计算是基于多个上下文单词context words,而不是单个目标单词 target word;需注意的是对于每一个训练样本,我们都要利用该参数更新公式来更新隐藏层→输出层的权重矩阵的每个元素。
而对于输入层→隐藏层的权值矩阵的更新过程,与公式(12)到公式(16)类似:
但需要注意的是,这里的中累加的
要用
替代:
3.优化计算效率
到目前为止,我们都在讨论bigram,CBOW和skip-gram模型的原始形式,现在我们将介绍一些高级的tricks来优化运行的效率。
首先总结一下之前介绍的所有模型,词汇表中的每个单词都存在2种向量表示的方法:
输入向量
输出向量
对于输入向量的学习成本并不高,而对于输出向量的学习代价却是昂贵的。 从参数更新方程(22)和(33)我们可以看出,为了更新每一例输出向量,我们需要迭代词汇表里面的每一个词,计算他们的输入值
;预测值
(skip-gram中是
)的可能性;预测误差
(skip-gram中是
);最后使用预测误差来更新他们的输出向量
。
显然对于训练样本的每个单词做这样的计算开销太大,尤其是在语料库很大的时候,这样的计算方式显得有些不切实际。解决这个问题,直观的方式是限制必须要更新的训练样例的输出向量的数目。一种有效的方式就是实现一个分层的soft-max;另一种方法也同样简单,通过采样来解决,这个内容将会放在下一章讨论。
这2中技巧都只是在优化更新输出向量的计算量,在我们的推到过程中,我们主要关注3个数值:
,新的目标函数;
,输出向量新的更新方程;
,更新输入向量的反向传播算法 的 预测误差 之和。
3.1 Hierarchical Softm
分层soft-max是计算soft-max的有效方法,该模型使用二叉树来表示词汇表中的所有单词,假设词汇表有个单词,那么用二叉树来表示这
个单词时,这些单词都只能在叶子节点上。而由于二叉树的性质,那些非叶子的节点为
个。对于每个叶子节点,存在也只存在一条从根节点出发到达此节点的绝对路径。通过这条路径,我们就能预估这个叶子节点表示的单词的可能性。下面是一个二叉树的示例:

上图是一个分词soft-max模型的二叉树示例, 白色的节点代表的是词汇表中的单词,黑色的节点代表的是非叶子节点。其中加粗显示的部分是从跟节点到单词节点的路径。该路径长度为
,
表示从跟节点到单词
的路径中的第
个节点。
在分层的soft-max模型中,单词没有了输出向量的表示形式,取而代之的是,个非叶子节点中的每个节点都有一个输出向量
,这样定义一个单词成为输出单词的可能性的公式就可以表示为:
(37)
其中:
是
节点的左孩子节点;
是
,在CBOW模型中
)
是一个特殊的函数,定义为:
下面,用一个例子来加深对公式(37)的理解:
回顾一下二叉树示例的图,假设我们要计算单词成为输出单词的可能性,我们将求解这个概率的问题定义为求解从根节点随机游走到叶子节点
的概率,在其路径上的每个非叶子节点(包括跟节点),我们都要分析他走向左孩子节点和右孩子节点的概率。
这里我们定义走向左孩子节点的概率为:
(39)
从公式可以发现的值取决于非叶子节点的向量表示
和隐藏层的输出值(隐藏层的输出值取决与输入单词的向量表示)。
显然走向右孩子节点的概率我们就可以这样定义:
根据二叉树示例图中从跟节点到的路径,我们能计算出单词
成为输出单词的可能性:
再回头看看公式(37),用上面的例子来理解,是不难的。而且可以发现:
现在我们开始推导非叶子节点的向量表示形式的参数更新公式,为了方便理解,我们还是先以one-word context(即只考虑上下文一个单词的情况)示例,之后我们拓展到CBOW或者skip-gram都会很方便。
为了简化公式,方便理解,令:
则对于训练样本来说,其损失函数可以定义为:
然后我们对去关于
的偏导数,得:
当时
,其余
.
接着我们计算内部节点的向量表示
关于函数
的偏导,得:
因此得到更新函数的公式为:
可以将理解为节点
的预测误差;并且这个公式需要循环迭代
。每一个内部节点的“任务”就是预测其随机游走路径是指向左孩子节点还是指向右孩子节点。
在
等于时意味着
在
等于时意味着
是预测的结果
对于一个训练实例 , 如果内部节点的预测值非常接近于真实值,则它的向量表示的更新变化很小;否则
向量指向一个适当的方向使得该实例的预测误差逐渐减小。这种更新方式同样可以应用与CBOW和skip-gram模型,只不过应用在skip-gram我们需要在输出单词上循环迭代C个输出上下文中的每一个单词。
为了使用反向传播算法来更新输出层→隐藏层的权值矩阵,我们对隐藏层的输出
计算其关于损失函数
的导数,得:
接下来我们根据公式(23)便可以获得CBOW模型输入向量的更新公式;对于skip-gram模型,我们需要计算上下文信息中的每个单词的,并将
带入公式(35),就能够得到输入向量的更新公式。
从以上更新公式我们可以看出:经过改进的模型Hierarchical soft-max的每个训练样例的每个上下文单词的计算复杂度从降为
。但是模型的参数几乎没有什么改变(内部节点对应
维向量,而原始模型的单词的输出向量维数为
)
3.2 Negative Sampling
Negative Sampling(负抽样)的方法比分层soft-max来得更为直截了当:在每次循环迭代过程中需要处理大量的节点上的计算,为了解决这个问题,Negative Sampling提出了只更新其中一部分输出向量的解决方案。
显然,负抽样的目的是为了最终输出的上下文单词(正样本)[基于训练样本的半监督学习]在采样过程中应该保留下来并更新,同时也需要采集一些反面例子[与训练样本结果不符](也可以称之为“负样本”)
那么怎么采集这些例子呢?这里我们引入一个概念“噪声分布”,通过噪声分布函数来采集例子。噪声分布函数并是特指某一函数,而是任意能够起到采样的函数。当然,当你有足够的经验后,你会知道在什么情况下应用什么噪声分布函数会更为合适。
那么把Negative Sampling(负抽样)应用到Word2vec上时,我们不用再使用那种能够产生很好的后验概率的多项式分布的负采样形式。Word2vec的作者们发现使用下面这种目标函数就能产生高质量且可靠的word embeddings:
其中:
是通过噪声分布
函数采集的一系列样本;
,在CBOW中
]
向量
代表输入层上单词
的向量,它实际上是输入矩阵
的其中一行;
向量
代表输出层上单词
的其中一列;(说了N遍了,emmmm.....)
(每个单词都有2中向量表示形式
我们对目标函数求其关于标量
的偏导,得:
其中表示单词
的“类型”,当
是正样本时,及预测值与真实值相同时
,反之
。然后通过链式法则可以得到目标函数
关于单个单词输出向量
的导数,得:
所以我们的更新函数就可以表示为:
(59)
negative sampling的关键就是公式(59)的更新过程只应用于词汇表的子集,而并非应用于整个词汇表,从而大大的减轻的计算量。除词汇量的大小变了之外,其余更新的方式是与式子(11)一样的。公式(59)适用于CBOW和skip-gram模型,在skip-gram模型中,我们每次更新一个单词。
接着利用反向传播算法来计算目标函数关于隐藏层输出值
的偏导,得:
在CBOW模型中,我们将上面公式代入(23)即可完成对模型输入向量矩阵的更新;
在skip-gram模型输入向量矩阵的更新中,我们需要计算每个上下文单词值的和然后再将其代入公式(35)。
关于word2vec的参数解释到此结束了,对文章有疑问或者其他方面问题的可以通过下面方式联系作者:
QQ:470581985
微信:lsq960124
打赏一下作者:
