word2vec 是 Google 于 2013年开源的一个用于获取词向量的工具包,作者是 Tomas Mikolov,不过现在他已经从 Google Brain 跳槽到了 Facebook Research,后来还参与了 fasttext 项目的研究。下面是我读博客 word2vec 中的数学原理 的一些笔记和总结。
Language Model (语言模型)
统计语言模型(statistical language model)是自然语言处理里比较常见的一个概念,是建立在一段序列(比如一句话)上联合概率分布。比如 “我/特别/喜欢/跑步”这句话(’/’符号表示分词,假设我们序列的基本单位是词语),其概率可以分解(factorize)成
观察一下条件概率就可以发现,如果尝试对上面的每个概率建立概率分布,词表的大小将会非常大,要拟合的参数也非常大。因此上面只是理论分析,并不是实用,我们可以考虑一些近似的计算。考虑做 N-1 阶马尔可夫假设,即第 N 个词的概率,只依赖于其前面 N-1 个词的概率。这样就得到了 N-gram 模型。写成链式法则(chain rule)就是
如果词汇表的大小是
当然,除了 N-gram 模型,还有其他方法来做 language model,比如 Recurrent Neural Network Language Model 这篇论文。没错,作者也是 Tomas Mikolov,这个是他做 word2vec 之前的工作。
Word Vector (词向量)
词向量的概念由 Bengio 在 2003 年的经典论文《A Neural Probabilistic Language Model》提出。他尝试用神经网络来学一个语言模型。在表示一个词的时候,如果用词典的序号表示,词与词之间的距离是序号之差,这样很没道理;如果用 one-hot 编码,可以保证每个词语之间的距离都是相等的,每个词语的维度都是词典的大小。
但是这篇论文则首次尝试了词嵌入(word embedding)的工作,即用更小的维度来表示一个词语,每个词都是这个连续的空间的一个稠密(dense)向量,这样可以表达更丰富的语义。这种用低维向量表示词的方法叫做词向量的分布式表示(Distributed Representation),因为词的语义被分散地存储在了向量的各个维度中(像分布式系统一样),每个维度都包含部分语义信息。不同词之间的相似度,可以用余弦距离来计算。
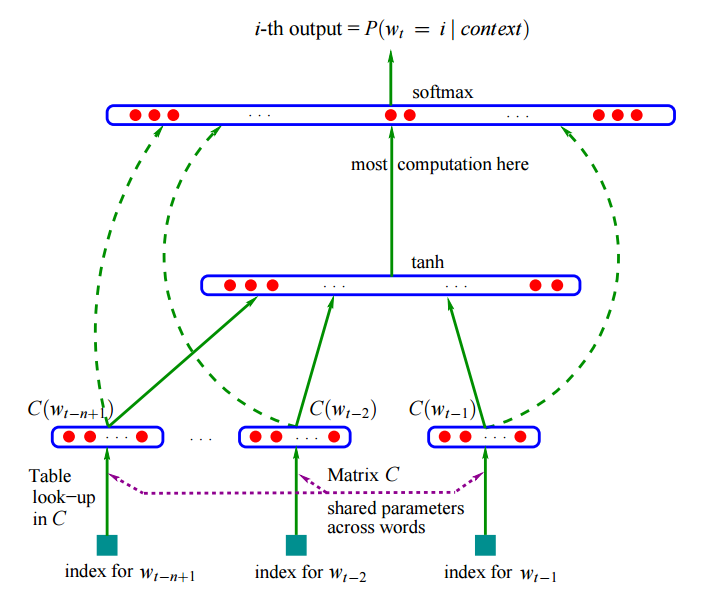
论文里的模型(见下图)也很简单,词嵌入使用一个矩阵 C 来表示,大小是词表大小乘以嵌入的维度,而前 n-1 个词在 C 中找到对应的词向量后,直接拼接到一起经过一个隐层神经元,再经过 Softmax 即可得到预测词的概率分布。模型的公式如下,
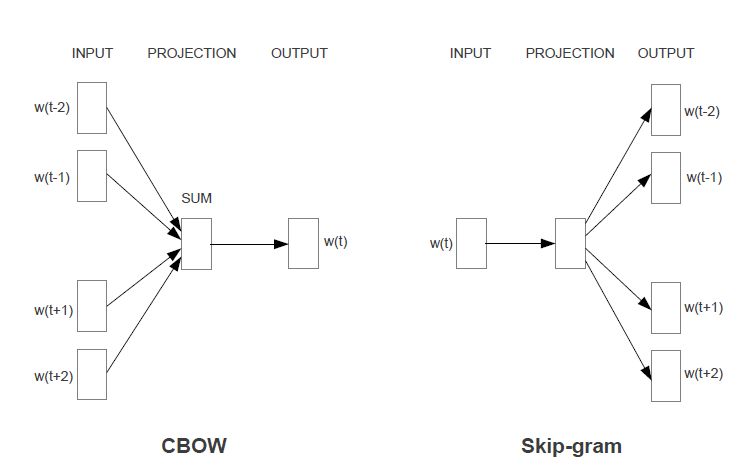
CBOW 和 Skip-gram 模型
我们设置一个大小为 t 的窗口,在语料库里随机抽取一个词
在 word2vec 的第一篇论文《Efficient Estimation of Word Representations in Vector Space, 2013a》中,设计了两个模型来训练词向量,分别是 CBOW(Continuous Bag-of-Words)和 Skip-gram 模型。下图是取窗口大小 c = 2 的例子,
- CBOW 模型
- 最大化概率
p(w|context(w)) ,用 context(w) 去预测 w
- 最大化概率
- Skip-gram 模型
- 最大化概率
p(context(w)|w) ,用 w 去预测 context(w)
- 最大化概率
然而这篇论文里没有提到模型具体是怎么构建的,但是在第二篇论文《Distributed Representation of Words and Phrases and their Compositionality, 2013c》中,本来是要讲层次 Softmax 和负采样,顺便提了一下 Skip-gram 模型的公式。
Skip-gram 模型是尝试用
由此可见,这两个模型的原始做法都是做内积,经过 Softmax 后得到概率,因此复杂度很高。【此处该有复杂度分析】所以才有了 2013c 中的两种改进方法,即层次 Softmax 和负采样。
Hierarchical Softmax
上面的 Softmax 每次和全部的词向量做内积,复杂度是
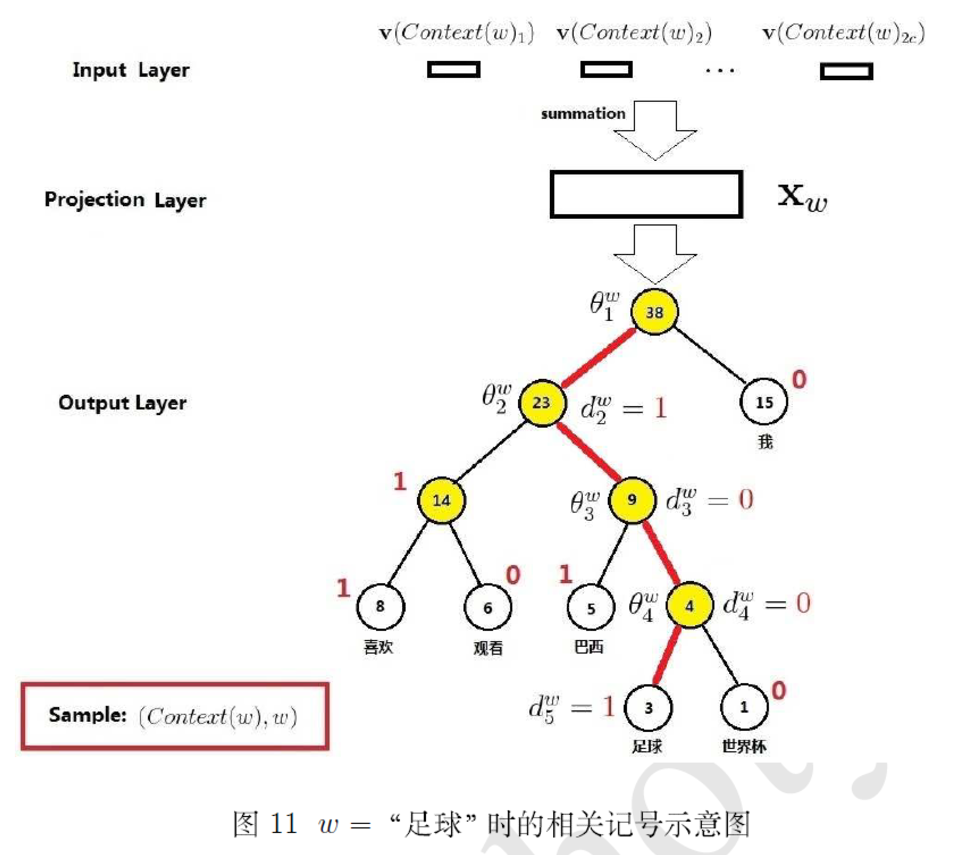
如上图所示,是 CBOW + Hierarchical Softmax 组合的模型,如果是要预测这个词,那么要沿着路径(图中红色的线)
哈夫曼树有个性质,叶节点的数量正好比非叶子结点多一个。这里的叶子节点个数就是词典大小,非叶子结点是 Hierarchical Softmax 的训练参数
Negative Sampling (负采样)
基于负采样的训练方法感觉有点暴力,相当于是直接用多个二分类来做多分类问题。比如 CBOW + Negative Sampling 的模型,是用
Skip-gram + Negative Sampling 的过程也类似,就不阐述了。
常见面试问题
问题 1,介绍一下 word2vec
- word2vec 的两个模型分别是 CBOW 和 Skip-gram,两个加快训练的 Loss 是 HS(Hierarchical Softmax )和负采样。
- 假设一个训练样本是又核心词
w 和其上下文context(w) 组成,那么 CBOW 就是用context(w) 去预测w ;而 Skip-gram 则反过来,是用w 去预测context(w) 里的所有词。 - HS 是试图用词频建立一棵哈夫曼树,那么经常出现的词路径会比较短。树的叶子节点表示词,共词典大小多个,而非叶子结点是模型的参数,比词典个数少一个。要预测的词,转化成预测从根节点到该词所在叶子节点的路径,是多个二分类问题。
- 对于负采样,则是把原来的 Softmax 多分类问题,直接转化成一个正例和多个负例的二分类问题。让正例预测 1,负例预测 0,这样子更新局部的参数。
问题 2,对比 Skip-gram 和 CBOW
- 训练速度上 CBOW 应该会更快一点,因为每次会更新
context(w) 的词向量,而 Skip-gram 只更新核心词的词向量。 - Skip-gram 对低频词效果比 CBOW,因为是尝试用当前词去预测上下文,当前词是低频词还是高频词没有区别。但是 CBOW 相当于是完形填空,会选择最常见或者说概率最大的词来补全,因此不太会选择低频词。
- Skip-gram 在大一点的数据集可以提取更多的信息。总体比 CBOW 要好一些。
问题 3,对比 HS 和 负采样
- 负采样更快一些,特别是词表很大的时候。
问题 4,负采样为什么要用词频来做采样概率?
- 因为这样可以让频率高的词先学习,然后带动其他词的学习。
问题 5,为什么训练完有两套词向量,为什么一般只用前一套?
- 对于 Hierarchical Softmax 来说,哈夫曼树中的参数是不能拿来做词向量的,因为没办法和词典里的词对应。负采样中的参数其实可以考虑做词向量,因为中间是和前一套词向量做内积,应该也是有意义的。但是考虑负样本采样是根据词频来的,可能有些词会采不到,也就学的不好。
问题 6,对比字向量和词向量
- 字向量其实可以解决一些问题,比如未登陆词,还有做一些任务的时候还可以避免分词带来的误差。
- 而词向量它的语义空间更大,更加丰富,语料足够的情况下,词向量是能够学到更多的语义的。
参考资料
- 训练文本
- 模型工具
- Google 开源的 wordvec
- gensim word2vec
- 是对上面的 Google C++ 版本的 python 接口封装
博客参考
论文