最近在面试的时候被问到了word2vec相关的问题,答得不好,所以结束后回顾了一下word2vec的内容,现在把回顾梳理的内容记录一下。有些是自己的想法,可能会有一些谬误。下面进入正题。
先来介绍相关的Notation
我们定义两个矩阵
其中,\(n\) 是词向量的大小(embedding size,可以人为指定),\(|{\mathcal V}|\) 是词表的大小。这两个矩阵既是词的向量表示,也是模型的参数。\(V\) 是输入词矩阵(input word matrix),其第 \(i\) 列就是单词\(w_i\)为输入词时的n维词向量表示,记作 \(v_i\);而 \(U\) 是输出词矩阵(output word matrix),其第 \(j\) 行是词 \(w_j\) 为输出词时的n维向量表示,记作 \(u_j\)。也就是说,对于每个单词来说,我们要学习两套不同的向量表示,即输入词向量表示 \(v_i\) 和输出词向量 \(u_i\)。
下面分别介绍word2vec中包含的两个模型——CBOW(Continuous Bag of Words)和 Skip-gram。
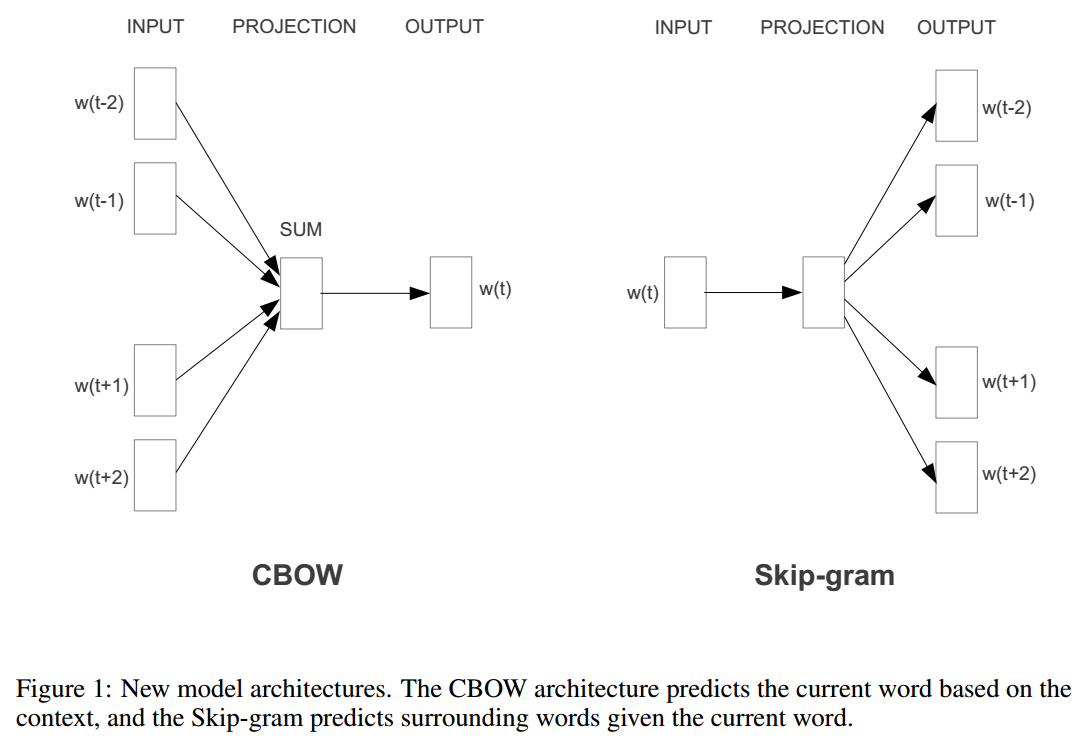
CBOW
CBOW用上下文词来预测中心词。其计算过程主要包括以下的步骤:
- 假设输入上下文(context)的长度为 \(2m\),我们把其中每个单词都映射为one-hot向量:\((x^{(c-m)},…,x^{(c-1)},x^{(c+1)},…,x^{(c+m)})\),以one-hot向量来指示单词在整个词表中的位置,也就是说,每个 \(x\) 都是长度为 \(|V|\) 的向量,并且其中只有一个位置的元素为1,其余元素为0。
- 通过embedding lookup来得到context中每个词的向量表示,即\((v_{c-m}=Vx^{(c-m)},v_{c-m+1}=Vx^{(c-m+1)},…,v_{c+m}=Vx^{(c+m)}∈{\mathbb R}^n)\)。
- 对这些上下文词取平均,得到 \({\hat v}=\frac{v_{c-m}+v_{c-m+1}+⋯+v_{c+m}}{2m}∈{\mathbb R}^n\)。
- 计算score vector,\(z=U{\hat v}\in {\mathbb R}^{|{\mathcal V}|}\)。
- 将score vector转化成概率分布 \({\hat y}=softmax(z)\in{\mathbb R}^{|{\mathcal V}|}\)。这个概率分布表示的就是模型预测出来的中心词的概率分布。
- 将模型输出的概率分布 \({\hat y}\) 与真实的分布 \(y\) 进行比较(真实的分布 \(y\) 其实就是实际中心词的 one-hot 向量表示 ),计算损失函数,并通过梯度下降来训练模型的参数(即 \(V\) 和 \(U\) )。
那么,我们怎么定义目标函数呢?通常,我们要借助信息论中的方法来衡量两个分布之间的距离。而用得最多的就是交叉熵了:
而 \(y\) 本身是一个 one-hot 向量,所以目标函数实际上可以写成:
\(c\) 就是实际的中心词所在的词表中的位置。We formulate our optimization objective as:
we use stochastic gradient descent to update all relevant word vectors \(u_c\) and \(v_j\).
Skip-Gram
与CBOW相反,skip-gram用中心词来预测(或产生)上下文词。
我们用 \(x\) 来代表输入的中心词,\(y^{(j)}\)代表输出的上下文词,同样将计算过程叙述如下:
- 得到中心词的one-hot向量 \(x\in {\mathbb R}^{|{\mathcal V}|}\)。
- 得到中心词对应的embedding,\(x_c=Vx \in {\mathbb R}^n\)。
- 计算score vector,\(z=Ux_c \in {\mathbb R}^{|{\mathcal V}|}\) 。
- 将score vector转换为概率分布,\({\hat y}=softmax(z)\)。其中 \({\hat y}^{c-m},...,{\hat y}^{c-1},{\hat y}^{c+1},...,{\hat y}^{c+m}\)是 \(2m\) 个上下文词对应的概率。
- 计算并最小化输出的概率分布 \({\hat y}\) 和真实的概率分布 \(y\) 之间的差距,也就是我们要优化的目标函数。
在计算objective function时,我们需要引入“Naïve Bayes Assumption”,也就是强条件独立(strong conditional independence assumption)。简单来说,就是在给定中心词的情况下,所有的输出词是相互独立的。
目标函数为negative log likelihood,其公式如下所示:
有了目标函数,我们就可以用SGD来更新参数了。不难看出,这里的 \(J\) 其实也和交叉熵是等价的:
至此,我们就定义好了word2vec两个模型的计算过程,但是,我们发现目标函数中“sum over 1 to \(|{\mathcal V}|\)”的操作在时间复杂度上是\(O(|{\mathcal V}|)\),而作为词表大小的 \(|{\mathcal V}|\) 又通常是非常大的(几十甚至上百万,there are an estimated 13 million tokens for the English language),这样就导致计算量很大。为了降低计算的复杂度,人们通常采用的的方法有两种——negative sampling 和 hierarchical softmax,下面分别对它们进行介绍。
Negative Sampling
我们考虑这样一个问题:给定一个词对 \((w,c)\) ,其中 \(w\) 表示中心词,\(c\) 表示context词,那么这个词对是否产生自我们的训练数据(training corpus)呢?我们用 \(P(D=1|w,c)\) 来表示 \((w,c)\) 来自corpus data的概率,而 \(P(D=0|w,c)\) 则表示 \((w,c)\) 不是从训练语料中产生的概率。这样,我们就把“ \((w,c)\) 是否来自训练语料”的问题表达成了一个二分类的问题,而解决二分类问题就可以用逻辑回归(参数为 \(\theta\))咯:
其中,\(\theta\) 既是模型的参数也是词向量 ( \(U\) 和 \(V\) )。现在我们用极大化似然的方法来构建一个目标函数如下:
最大化似然相当于最小化负的似然:
其中 \(D\) 是实际的训练语料,比如当中心词是“cat”时,从 \(D\) 中产生的上下文词可能是"fish""cute""feline""dog" "moew"等。而\(\tilde D\) 是“false”或者“negative corpus”,代表着其中的词不太可能出现在中心词的上下文中,比如"traffic""NLP""talk""swim""stock"等。我们可以通过实时地从词表中随机采样的方式来产生这些negative sample。采样所遵循的分布为:
即:Unigram model raised to the power of 3/4。这个3/4像是一个经验值,但也可以从下面的例子中窥见一些取这个值的原因:
"bombastic"原始的概率是0.01,但使用 \(P_n(w)\) 采样的概率变成了原始的约三倍,而 “is” 的采样概率相比初始概率只是略微上升了一点。这样相当于对频率低的词有“特殊照顾”,让它们的采样概率不至于过低。
Hierarchical Softmax
与negative sampling的“采样”思想不同,hierarchical softmax用一棵二叉树来表示整个词表,其中,每个叶结点都代表一个单词,每个内部节点上都有一个向量,这些向量构成了整个二叉树的参数。与原始softmax计算输出词的概率分布时要遍历整个词表不同,我们将“某个单词是输出单词的概率”定义为从根到该单词的叶子的随机游走(random walk)的概率。所以,我们只需要在二叉树中找到从根结点到输出词所在的叶子结点之间的path,然后根据输入词向量和path中包含的各个内部节点上的向量来计算该输出词的概率。
在这个模型中,没有输出词的向量表示,也就是没有 \(U\) 矩阵。要学习的参数包括两方面:一是输入词矩阵(即 \(V\)),二是整个树的内部结点上的向量。
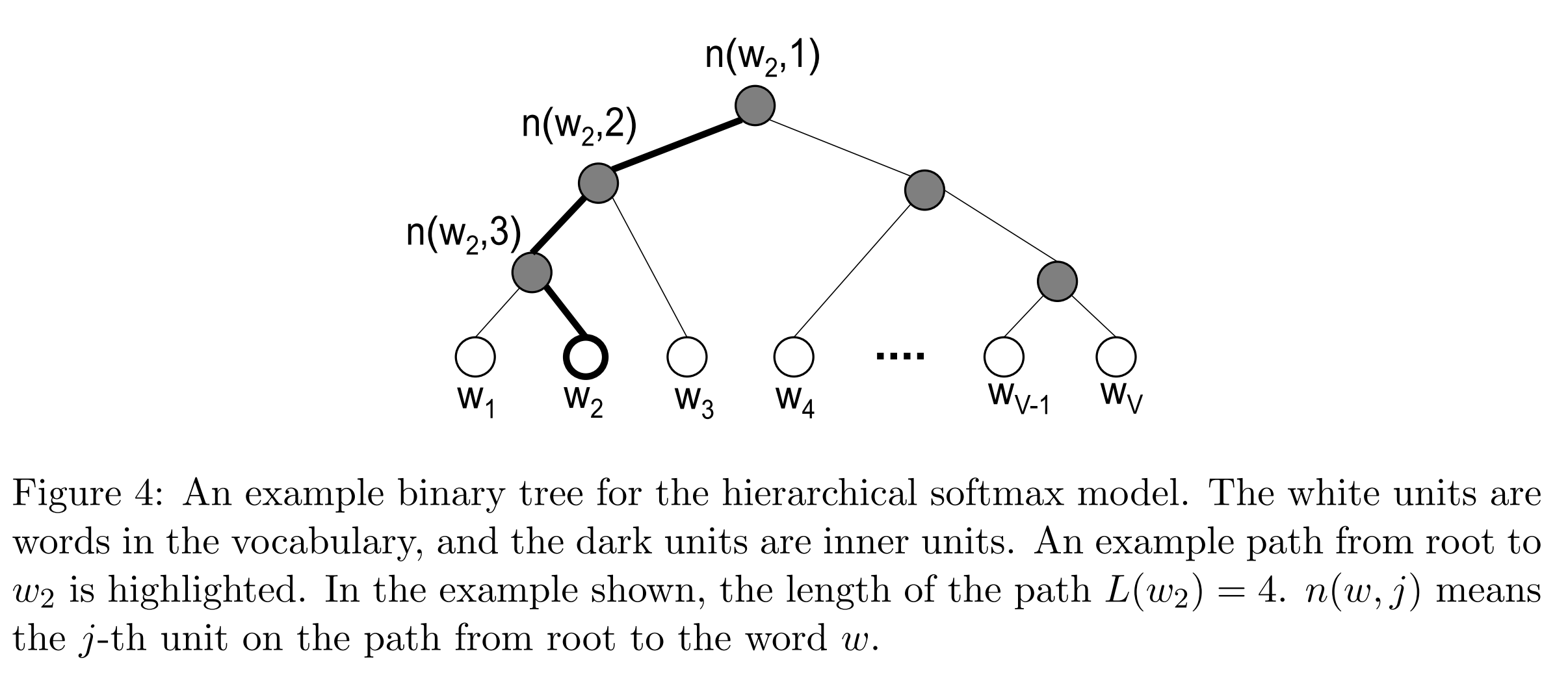
那么,怎么计算概率呢?我们以上图描述的情况为例,并假设我们的模型是CBOW。设输入了上下文词 ,并得到其对应的向量表示 \({\hat v}\) ,此时我们知道真实的输出词为 \(w_2\) ,于是从建好的二叉树中可以直接得到 \(w_2\) 对应的path 。设 \(n(w,i)\) 为 path 上的第 \(i\) 个节点,其上的向量为 \(h_{n(w,i)}\) ,则 path 为 \([n(w_2,1),n(w_2,2),n(w_2,3)]\) 。模型产生的输出词为 \(w_2\) 的概率为:
我们可以这样理解上式:将概率计算看作二叉树的深度搜索的过程,并用二元逻辑回归来表示“往左”和“往右”两种不同情况下产生的相应的概率,这里我们用“1 正类”来表示向左,用“0 负类”来表示向右。而 \({\hat v}\) 相当于逻辑回归的参数。
由此,我们也容易得到目标函数为:
由于我们在计算的时候是沿着二叉树一步步地向下深入的,时间复杂度从 \(O(|{\mathcal V}|)\) 降到了 \(O(log(|{mathcal V}|))\)。同时,二叉树这种“层次化”的结构也是其得名“hierarchical softmax”的原因。在实际构建二叉树的时候通常会使用霍夫曼树,并使高频的词更靠近根结点。
我觉得,其实无论是negative sampling还是hierarchical softmax,它们都是在对原始的softmax计算做简化近似,只是采取的角度和使用的方法不同而以。在实际使用中,对于低频词,hierarchical softmax的效果会略优于negative sampling,而negative sampling则在高频词和低维向量的情况下效果较好。
References
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111-3119).
Francois Chaubard, Michael Fang, Guillaume Genthial, Rohit Mundra, Richard Socher. CS224n: Natural Language Processing with Deep Learning. Lecture Notes Part1. Stanford University.