从自然语言模型谈起
1 词向量
1.1词向量
自然语言处理就是将自然语言交给机器的算法来处理,首要的任务就是把语言数字化,词向量就是将词语转换为向量的一种方法。词向量主要有以下两种表示方法。
- one-hot编码
- Distribted Representation
one-hot编码是用一整串0 1来表示某个词语,向量到的长度为词典的大小,某个词的词向量只有一个元素位置为1,其余均为0。缺点就是维度太大,而且任意两个向量之间没有任何关系。假设整个语料有两句话,++我爱中国人++和++赵鸿宁爱我++,那么分词之后可能一共有“我,爱,中国,人,赵洪宁”这个5个词,爱这个词的词向量大概是这种形式:
Distributed Representation方法是用一个普通的向量表示一个词,相对长度要短很多,”我“这个词向量大概长这样:
很明显这种词向量并不能直接由语料得到,必须经过相应的训练和学习得到。但是我们不能随便瞎训练,一个比较好的方式就是相似的词语它们的词向量在空间上也比较接近,这里的接近体现在几何意义上就是向量的欧式距离较小。以二维向量为例,就是他们的夹角越小越好。代表的方法有Bingo发表的NNLM模型和Google的word2Vec模型。
1.2 词袋(bag of words)
词袋是词语的另外一种表示方法,核心思想就是给每个词语一个索引,比如刚刚那个例子,可能会有一个索引{0,1,2,3,4}来表示语料中的5个词语。一般来说可以用hash散列的方式得到某个词的索引,比如可以定义我的索引:index(我) = hashcode(我),当然这种哈希方式会存在冲突,冲突的解决方法就是哈希中的方法了。
2 自然语言模型
上面提到了词向量的Distributed Representation,那么我们怎么能够得到这种向量呢?怎么通过模型的训练得到这种向量呢?这就不得不提到自然语言模型了。首先要明确一点,不管是word2vec还是其他模型得到的词向量,这些==词向量不是模型训练的任务,只是模型训练的附属品。==
2.1 基本概念
在实际的应用中,我们通常需要解决这样的一类问题:如何计算一个句子的概率?比如:
- 机器翻译:P(high winds tonite)>P(large winds tonite)
- 语音识别:P(I saw a van)>P(eyes awe of an)
所有的这些问题都可以归结于计算一个由T个单词组成的完整的句子的概率:
最原始的做法是基于统计的方式,用现有的语料库去估计给我们的一句话出现的概率。
但是语料库太大,统计起来太麻烦,所以也就有了N-gram模型,它是基于马尔可夫假设,即每个词出现的概率并不是跟它前面的所有词有关,我们只取离它最近的N个词语,也就是:
但是这也带来了问题,因为它是从语料库中数出相应的个数,用count(wi)/count(wi-1….),所以主要有两个缺点:首先是如果N选的太大,语料经常不足,而且语料库太大。其次是可能会出现某些Gram在语料中不存在的情况,这时候概率值相乘就为0,解决方法有两个:平滑法(平滑法,即给分子分母都加1)和回退法(利用n-1元组去估计n元组)。
2.2 模型的问题和目标
如果都是用最原始的直接统计数数的方式去计算,这样的语言模型没有参数,直接计算,但是通常模型是带有参数的,比如n-gram中如果采用平滑法,分子分母分别加上的常数是什么。
另外一种解决方式就是我们是把contex(wi)和wi直接带入到某个函数中求解出来的,不再是数数数出来的概率。一般会基于现有的训练数据样本,用函数去拟合出概率值:
优化的思想就是极大似然估计,也就是我们利用极大似然估计作为我们的优化策略,让目标预测值等于实际值的概率尽可能的大,这里的意思是既然某句话已经出现了,那么我们就让这句话出现的概率最大。至于为什么要取对数,一个原因是可能随着自变量的增大,因变量的方差越来越大,我们需要把它拉回到一个正常的数值,数据变得更加平滑。所以,优化的目标是:
2.3 NNLM模型
首先介绍2003年Bingo发表的论文中所描述的神经网络模型
:
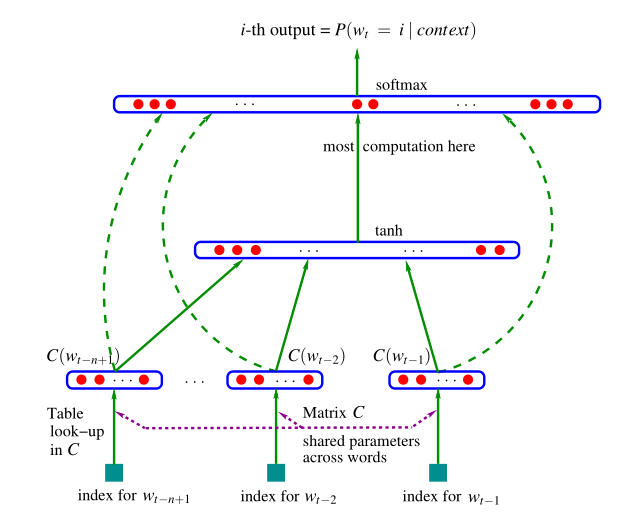
一共分为四层:==输入层,投影层,隐藏层,输出层==。输入层输入的是单词wi的上下文,一般会定义一个窗口的大小,假设我们只看每个词的前面四个词,那么投影层,会取出这4个词对应的词向量前后拼接在一起。假设语料库大小为10000,矩阵C的维度为300x10000,其中300代表着每一个词向量的维度。对应的投影层的结果就是4个300维的向量然后经过拼接变成的隐藏层1200维向量。然后隐藏层神经元连接到输出层,输出向量的维度为1w的向量,向量每个位置的数值表示P(w_i|contex(w_i)),因为wi一共有1w中可能,所以向量的维数为1w。
优化的目标函数是:
输出层要经过一次softmax,才能变成概率的含义,这样1w维向量每个位置的值就表示为概率。正常来说,语料一般有多句话,每句话都有多个词语,我们的目标函数写的比较简单,实际中应该是每句话的概率都要最大。虽然每句话给进我们的模型中,它的句子不同,上下文也不同,但是大家都有相同的b,W,U,C,d,通过在求解f的过程中,就可以更新出这些参数。