问题提出:
众所周知,Hadoop框架使用Mapper将数据处理成一个<key,value>键值对,再网络节点间对其进行整理(shuffle),然后使用Reducer处理数据并进行最终输出。
在上述过程中,我们看到至少两个性能瓶颈:
- 如果我们有10亿个数据,Mapper会生成10亿个键值对在网络间进行传输,但如果我们只是对数据求最大值,那么很明显的Mapper只需要输出它所知道的最大值即可。这样做不仅可以减轻网络压力,同样也可以大幅度提高程序效率。
- 使用专利中的国家一项来阐述数据倾斜这个定义。这样的数据远远不是一致性的或者说平衡分布的,由于大多数专利的国家都属于美国,这样不仅Mapper中的键值对、中间阶段(shuffle)的键值对等,大多数的键值对最终会聚集于一个单一的Reducer之上,压倒这个Reducer,从而大大降低程序的性能。
目标:
MapReduce中的Combiner就是为了避免map任务和reduce任务之间的数据传输而设置的,Hadoop允许用户针对map task的输出指定一个合并函数。即为了减少传输到Reduce中的数据量。它主要是为了削减Mapper的输出从而减少网络带宽和Reducer之上的负载。
Without Combiner:

With Combiner:
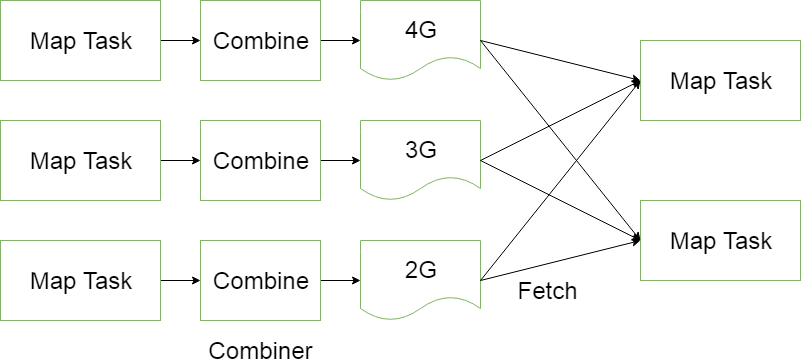
可以看出,使用Combiner之后,能够节省很大的带宽。
数据格式转换:
map: (K1, V1) → list(K2,V2)
combine: (K2, list(V2)) → list(K3, V3)
reduce: (K3, list(V3)) → list(K4, V4)
注意:combine的输入和reduce的完全一致,输出和map的完全一致
使用注意:
对于Combiner有几点需要说明的是:
-
有很多人认为这个combiner和map输出的数据合并是一个过程,其实不然,map输出的数据合并只会产生在有数据spill出的时候,即进行merge操作。
-
与mapper与reducer不同的是,combiner没有默认的实现,需要显式的设置在conf中才有作用。
-
并不是所有的job都适用combiner,只有操作满足结合律的才可设置combiner。combine操作类似于:opt(opt(1, 2, 3), opt(4, 5, 6))。如果opt为求和、求最大值的话,可以使用,但是如果是求中值的话,不适用。
-
一般来说,combiner和reducer它们俩进行同样的操作。
但是:特别值得注意的一点,一个combiner只是处理一个结点中的的输出,而不能享受像reduce一样的输入(经过了shuffle阶段的数据),这点非常关键。具体原因查看下面的数据流解释。
插入了Combiner的MapReduce数据流
Combiner:前面展示的流水线忽略了一个可以优化MapReduce作业所使用带宽的步骤,这个过程叫Combiner,它在Mapper之后Reducer之前运行。Combiner是可选的,如果这个过程适合于你的作业,Combiner实例会在每一个运行map任务的节点上运行。Combiner会接收特定节点上的Mapper实例的输出作为输入,接着Combiner的输出会被发送到Reducer那里,而不是发送Mapper的输出。Combiner是一个“迷你reduce”过程,它只处理单台机器生成的数据(特别重要,作者在做一个矩阵乘法的时候,没有领会到这点,把它当成一个完全的reduce的输入数据来处理,结果出错。)。
词频统计是一个可以展示Combiner的用处的基础例子,上面的词频统计程序为每一个它看到的词生成了一个(word,1)键值对。所以如果在同一个文档内“cat”出现了3次,(”cat”,1)键值对会被生成3次,这些键值对会被送到Reducer那里。通过使用Combiner,这些键值对可以被压缩为一个送往Reducer的键值对(”cat”,3)。现在每一个节点针对每一个词只会发送一个值到reducer,大大减少了shuffle过程所需要的带宽并加速了作业的执行。这里面最爽的就是我们不用写任何额外的代码就可以享用此功能!如果你的reduce是可交换及可组合的,那么它也就可以作为一个Combiner。你只要在driver中添加下面这行代码就可以在词频统计程序中启用Combiner。
例子
输入文件
test1.txt
hello darren
hello zhang
hello javatest2.txt
hello hadoop
hello spark工具类
package com.darren.hadoop.util;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.log4j.Logger;
public class HDFSUtil {
private static final Logger LOG = Logger.getLogger(HDFSUtil.class);
/**
* Delete file
*
* @param conf
* @param hdfsPath File path
* @throws IOException
*/
public static void deleteHDFSFile(Configuration conf, String hdfsPath) throws IOException {
FileSystem fileSystem = FileSystem.get(conf);
Path path = new Path(hdfsPath);
if (fileSystem.exists(path)) {
fileSystem.delete(path, true);
LOG.info("HDFS deleted: " + path);
}
}
}Mapper文件
package com.darren.hadoop.wordcount.combiner;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCoundMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text word = new Text();
IntWritable one = new IntWritable(1);
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
String token = tokenizer.nextToken();
word.set(token);
context.write(word, one);
}
}
}Reduce文件
package com.darren.hadoop.wordcount.combiner;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCoundReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
int count = value.get();
sum += count;
}
context.write(key, new IntWritable(sum));
}
}
没有Combiner的Driver文件
package com.darren.hadoop.wordcount.combiner;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.log4j.Logger;
import com.darren.hadoop.util.HDFSUtil;
public class WordCount extends Configured implements Tool {
private static final Logger LOG = Logger.getLogger(WordCount.class);
private static final String INPUT_PATH = "test-in/wordcount";
private static final String OUTPUT_PATH = "test-out/wordcount";
public static void main(String[] args) throws Exception {
int rtnStatus = -1;
try {
rtnStatus = ToolRunner.run(new Configuration(), new WordCount(), args);
} catch (Exception e) {
LOG.error("WordCount Driver", e);
}
LOG.info("WordCount Driver Status Code :" + rtnStatus);
System.exit(rtnStatus);
}
@Override
public int run(String[] args) throws Exception {
long start = System.currentTimeMillis();
Configuration conf = getConf();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCount.class);
job.setJobName("WordCount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(WordCoundMapper.class);
job.setReducerClass(WordCoundReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
// job.setCombinerClass(WordCoundCombiner.class);
// set reduce number
job.setNumReduceTasks(1);
LOG.info(String.format("No of Reducers: %s", job.getNumReduceTasks()));
// delete the output path
HDFSUtil.deleteHDFSFile(conf, OUTPUT_PATH);
FileInputFormat.addInputPath(job, new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
job.waitForCompletion(true);
// close
this.close();
long end = System.currentTimeMillis();
double s = (end - start) / 1000.0;
double m = s / 60.0;
double h = m / 60.0;
LOG.info("Total Cost: [" + s + "] s");
LOG.info("Total Cost: [" + m + "] m");
LOG.info("Total Cost: [" + h + "] h");
return 0;
}
private void close() throws IOException {
FileSystem fileSystem = FileSystem.get(getConf());
fileSystem.close();
}
}执行结果日志
Map-Reduce Framework
Map input records=5
Map output records=10
Map output bytes=101
Map output materialized bytes=133
Input split bytes=270
Combine input records=0
Combine output records=0
Reduce input groups=6
Reduce shuffle bytes=133
Reduce input records=10
Reduce output records=6
Spilled Records=20
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=9
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=913833984分析
Map input records=5 Map output records=10,从输入文件的数据来看是正确的。
Combine input records=0 Combine output records=0,因为没有使用Combiner,输入输出是0也是正确的。
Reduce input records=10 Reduce output records=6,从输入文件和mapper结果分析也是正确的。
那么我们来看一下使用Combiner的结果是怎样的。
Combiner文件
package com.darren.hadoop.wordcount.combiner;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCoundCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
int count = value.get();
sum += count;
}
context.write(key, new IntWritable(sum));
}
}
带有Combiner的Driver文件,把注释去掉
// job.setCombinerClass(WordCoundCombiner.class);
job.setCombinerClass(WordCoundCombiner.class);执行结果日志
Map-Reduce Framework
Map input records=5
Map output records=10
Map output bytes=101
Map output materialized bytes=97
Input split bytes=270
Combine input records=10
Combine output records=7
Reduce input groups=6
Reduce shuffle bytes=97
Reduce input records=7
Reduce output records=6
Spilled Records=14
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=0
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=1016070144分析
Map input records=5 Map output records=10,从输入文件的数据来看是正确的。
Combine input records=10 Combine output records=7,输入和Map输出一致,但是输出为什么是7而不是6。从输入文件可知,两个输入文件,明显都小于128M,显然会划分成两个Map Task, 每一个Map Task对应一个Combiner,所以两个Combiner的输入输出分别是:
// 输入 hello 1 hello 1 hello 1 darren 1 zhang 1 java 1 // 输出 hello 3 darren 1 zhang 1 java 1// 输入 hello 1 hello 1 hadoop 1 spark 1 // 输出 hello 2 hadoop 1 spark 1所以,输入是10,输出是7而不是6
Reduce input records=7 Reduce output records=6,输入是Combiner的输出结果,7是正确的,最终结果6也是正确的。
参考: