Combiner类是用于提高MapReduce的性能,作用在Map与Reduce之间,减少Mapper的输出和Reduce的压力。

图1 基本流程
例:计算出apat63_99.txt中,每个国家专利声明的平均数
图2原始数据
在这份数据中,每一条都记录了专利号、批准年、批准日、申请年、第一发明人国家、第一发明人所在州、专利权人、专利权人类型、声明数目、主要专利类型等,而我们需要的就是利用这里的第一发明人国家和声明数目统计出每个国家专利声明的平均数。
代码:

packageorg.apache.hadoop.pr;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.KeyValueTextInputFormat;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class AverageByAttribute extends Configured implementsTool{
//Mapper类,找出数据——国家,专利数目,最后还有一个1作为标记
publicstatic class MapClass extends MapReduceBase implementsMapper{
public voidmap(LongWritable key, Text value, OutputCollector out, Reporterreporter)
throwsIOException {
Stringfields[] = value.toString().split(",", -20);//将文本以“,”分开,存进数组fields中
Stringcountry = fields[4];//取出第5个数据国家
StringnumClaims = fields[8];//取出第9个数据声明数目
if(numClaims.length()>0 &&!numClaims.startsWith("\"")){//如果声明数目有值,而且不是以"开头(不是字符串)
out.collect(new Text(country), newText(numClaims+",1"));//以的形式输出
}
}
}
//Combine类,接收mapper的结果
publicstatic class Combine extends MapReduceBase implementsReducer{
public voidreduce(Text key, Iterator values, OutputCollector output, Reporterreporter)
throwsIOException {
double sum =0;
intcount = 0;
while(values.hasNext()){
Stringfields[] = values.next().toString().split(",");//将values中的每份{numClaims,1}放到数组中
sum +=Double.parseDouble(fields[0]); //统计出声明总数量
count +=Integer.parseInt(fields[1]);//统计出有多少份专利
}
output.collect(key, new Text(sum + "," + count));//输出的形式就是
}
}
//Reducer类,以国家为key,目的要用所有声明的和/专利的总个数,求出这个国家专利平均声明个数
publicstatic class Reduce extends MapReduceBase implements Reducer{
public voidreduce(Text key, Iterator values, OutputCollector output, Reporterreporter)
throwsIOException {
double sum =0;
int count =0;
while(values.hasNext()){
Stringfields[] = values.next().toString().split(","); //将values中的{声明总数,专利个数}以“,”分开存到数组中
sum +=Double.parseDouble(fields[0]);//遍历之后计算所有声明数目的和
count +=Integer.parseInt(fields[1]);//遍历之后计算共有多少个专利
}
output.collect(key, new DoubleWritable(sum/count));//算出平均数
}
}
public intrun(String[] args) throws Exception {
Configuration conf = getConf();
JobConf job= new JobConf(conf, AverageByAttribute.class);
Path in =new Path(args[0]);
Path out =new Path(args[1]);
FileInputFormat.setInputPaths(job, in);//设置输入路径
FileOutputFormat.setOutputPath(job, out);//设置输出路径
job.setJobName("MyJob");//设置job名
job.setMapperClass(MapClass.class);//设置map类
job.setCombinerClass(Combine.class);//设置combine类
job.setReducerClass(Reduce.class);//设置reduce类
job.setInputFormat(TextInputFormat.class);//输入方式
job.setOutputFormat(TextOutputFormat.class);//输出方式
job.setOutputKeyClass(Text.class);//输出key值类型
job.setOutputValueClass(Text.class);//输出value值类型
JobClient.runJob(job);//启动job
return0;
}
public static void main(String[] args) throwsException{
int res =ToolRunner.run(new Configuration(), new AverageByAttribute(),args);
System.exit(res);
}
}

图3运行结果
运行分析:
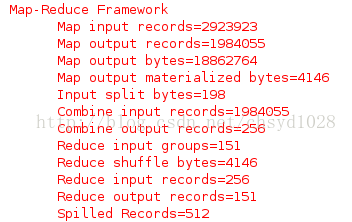
图4 运行过程部分截取
从上图中可以看出,在Map中输入了2923923条记录,处理后输出1984055条记录,在Combine中将这1984055条记录处理后,仅剩余256条记录交给Reduce处理,大大减少了Reduce的压力。
使用时注意事项:
①在写Combine时,必须保证即使没有Combine也能运行,因此最好先写mapper和reduce,之后再添加Combine类。
②Combine要实现的是Reduce接口。
③为了使Combiner可行,driver除了要继承mapper、reducer类之外,还要继承Combiner指定类。
要在run()方法中加入代码:job.setCombinerClass(Combiner.class)