一 序
上一篇介绍了《innodb的数据存储结构》。本篇继续整理Innodb索引实现原理。本文基于《MySQL运维内参》第8章整理。
二 B+树
B+树属于索引的基础,不在详细介绍插入删除过程。只介绍特点。
1 搜索二叉树:每个节点有两个子节点,数据量的增大必然导致高度的快速增加,显然这个不适合作为大量数据存储的基础结构。
2 B树(m阶):一棵m阶B树是一棵平衡的m路搜索树。
- 每个节点之多拥有m棵子树;
- 根结点至少拥有两颗子树(存在子树的情况下);
- 除了根结点以外,其余每个分支结点至少拥有 m/2 棵子树;
- 所有的叶结点都在同一层上;
- 有 k 棵子树的分支结点则存在 k-1 个关键码,关键码按照递增次序进行排列;
- 关键字数量需要满足ceil(m/2)-1 <= n <= m-1;
特点:
- 关键字集合分布在整颗树中;
- 任何一个关键字出现且只出现在一个节点中;
- 每个节点存储data和key;
- 搜索有可能在非叶子节点结束;
- 一个节点中的key从左到右非递减排列;
- 所有叶节点具有相同的深度,等于树高h。

3 .B+树:
- 根结点只有一个,分支数量范围为[2,m]
- 分支结点,每个结点包含分支数范围为[ceil(m/2), m];
- 分支结点的关键字数量等于其子分支的数量减一,关键字的数量范围为[ceil(m/2)-1, m-1],关键字顺序递增;
- 所有叶子结点都在同一层;

特点:
- 所有关键字都存储在叶子节上,且链表中的关键字是有序的;
- 不可能非叶子节点命中返回;
- 非叶子节点相当于叶子节点的索引,叶子节点相当于是存储(关键字)数据的数据层 带顺序访问指针的B+树提高了区间查找能力
B+树与B树区别:
- B+非叶子节点不存储data,只存储key
- 所有的关键字全部存储在叶子节点上
- 每个叶子节点含有一个指向相邻叶子节点的指针
- 非叶子节点可以看成索引部分,节点中仅含有其子树(根节点)中的最大(或最小)关键字
三 索引的设计
数据库作为存取数据的工具,对应性能影响主要有三块:CPU,内存,磁盘 。

索引是一冲存储形式,影响最大的就是磁盘。索引查找过程要产生磁盘I/O,相对于内存存取,磁盘I/O要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是查找过程中磁盘I/O操作次数的渐进复杂度。磁盘原理很多书都介绍了,简单说一下:而硬盘的随机访问要经过机械动作(1磁头移动 2盘片转动),访问效率比内存低几个数量级,但是硬盘容量较大。典型的数据库容量大大超过可用内存大小,这就决定了在B+树中检索一条数据很可能要借助几次磁盘IO操作来完成。如下图所示:通常向下读取一个节点的动作可能会是一次磁盘IO操作,不过非叶节点通常会在初始阶段载入内存以加快访问速度。同时为提高在节点间横向遍历速度,真实数据库中可能会将图中蓝色的CPU计算/内存读取优化成二叉搜索树(InnoDB中的page directory机制)。
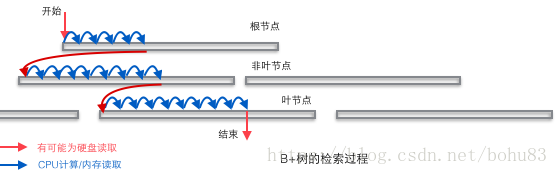
结合关系型数据库的特点:行存储,每行有主键,可以形成键值对,键值可以排序。
先说下一开始的平衡二叉树与磁盘预读:
我们知道磁盘的存取速度比主存的慢很多,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。而平衡二叉树的深度H高,由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以平衡二叉树的I/O渐进复杂度也为O(h),效率明显比B树差很多。
再看为啥B+树比B树适合做索引:B+内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
但这不是最主要的因素,关键是B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。梁斌老师对此解释很好:B+树还有一个最大的好处,方便扫库,B树必须用中序遍历的方法按序扫库,而B+树直接从叶子结点挨个扫一遍就完了,B+树支持range-query非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
另外B树也好B+树也好,根或者上面几层因为被反复query,所以这几块基本都在内存中,不会出现读磁盘IO,一般已启动的时候,就会主动换入内存。
真实数据库中的B+树应该是非常扁平的,可以通过向表中顺序插入足够数据的方式来验证InnoDB中的B+树到底有多扁平。通常是单表在千万级,大小几十个G的情况下,高度是3.高度是4的情况通常实际业务达不到已经分表了。
到此,索引理论结束了,可以有个雏形了,跟之前的Innodb的文件管理串起来。
三 聚簇索引与二级索引
在查询数据时,通常在被查询列建一个索引,这是利用了索引中被排序的键值。通过内节点的索引功能及叶子节点的有序性,利用二分查找的方法,极大提高了查询性能。
每个InnoDB的表都拥有一个特殊索引,此索引中存储着行记录(称之为聚簇索引Clustered Index),一般来说,聚簇索引是根据主键生成的。聚簇索引按照如下规则创建:
- 当定义了主键后,InnoDB会利用主键来生成其聚簇索引;
- 如果没有主键,InnoDB会选择一个非空的唯一索引来创建聚簇索引;
- 如果这也没有,InnoDB会隐式的创建一个自增的列(rowid)来作为聚簇索引。
除了主键索引之外的索引,成为二级索引(Secondary Index)。二级索引可以有多个,二级索引建立在经常查询的列上。与聚簇索引的区别在于二级索引的叶子节点中存放的是除了这几个列外用来回表的主键信息(指针)。
所为回表:就是在使用二级索引时,因为二级索引只存储了部分数据,如果根据键值查找的数据不能包含全部目标数据,就需要根据二级索引的键值的主键信息,去聚簇索引的全部数据。然后根据完整数据取出所需要的列。这种在二级索引不能找到全部列的现象称为“非索引覆盖”,需要两次B+树查询,反之称为索引覆盖。所以索引需要平衡考虑,多建索引有利于查询,但是占用空间大还影响写入性能。即索引要精有用。
为啥要这样设计呢?
1 由于行数据和叶子节点存储在一起,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。
2 辅助索引使用主键作为"指针" 而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置(实现中通过16K的Page来定位,后面会涉及)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址,不是本文重点不展开。
InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同,下面介绍innodb二级索引的指针。
以自定义主键为例,介绍二级索引与聚簇索引的逻辑关系:
聚簇索引
索引结构:[主键列][TRXID][ROLLPTR][其他建表的非主键列]
参与记录比较的列:主键列
内节点key列:[主键列]+page No指针
二级唯一索引
索引结构:[唯一索引列][主键列]
参与记录比较的列:[唯一索引列][主键列]
内节点key列:[唯一索引列]+page No指针
二级非唯一索引
索引结构:[非唯一索引列][主键列]
参与记录比较的列:[非唯一索引列][主键列]
内节点key列:[非唯一索引列][主键列]+page No指针
为自定义主键列的,主键列有rowid替代。
上面除了列出了索引包含的列,也解释了用来查找数据时,在二级索引及聚簇索引中,参与比较大小的列是什么。
四 页分裂

书上讲了innodb的插入过程。插入过程B+树的页分裂。
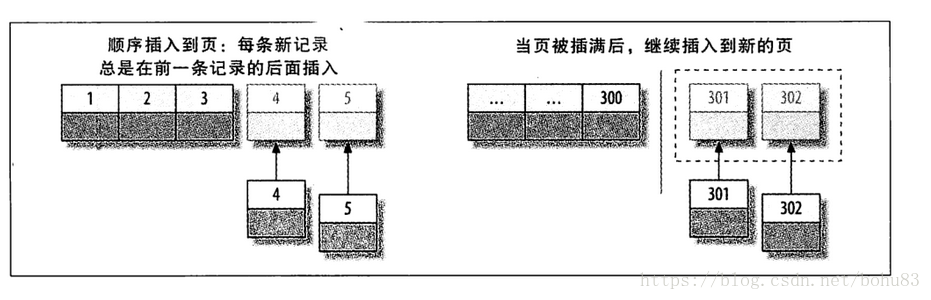
如果写入是乱序的,InnoDB不得不频繁地做页分裂操作,以便为新的行分配空间。页分裂会导致移动大量数据,一次插入最少需要修改三个页而不是一个页。 如果频繁的页分裂,页会变得稀疏并被不规则地填充,所以最终数据会有碎片。
这里可以往库里插数据测试下,主键ID连续跟随机做个对比。
当然MySQL还是做了优化的,跟B+树的不太一样。网上有个例子:http://hedengcheng.com/?p=525
下图,是一个经典的B+树组织结构图(2层B+树,每个页面的扇出为4):

- 此B+树,以InnoDB实现的B+树结构为准;
- 此B+树,有5条用户记录,分别是1,2,3,4,5;
- B+树上层页面中的记录,存储的是下层页面中的最小值(Low Key);
- B+树的所有数据,均存储在B+树的叶节点;
- B+树叶节点的所有页面,通过双向链表链接起来;
4.1 B+树的分裂
在上图B+树的基础上,继续插入记录6,7,B+树结构会产生以下的一系列变化:
插入记录6,新的B+树结构如下:

插入记录7,由于叶页面中只能存放4条记录,插入记录7,导致叶页面分裂,产生一个新的叶页面。

传统B+树页面分裂操作分析:
按照原页面中50%的数据量进行分裂,针对当前这个分裂操作,3,4记录保留在原有页面,5,6记录,移动到新的页面。最后将新纪录7插入到新的页面中;
50%分裂策略的优势:
分裂之后,两个页面的空间利用率是一样的;如果新的插入是随机在两个页面中挑选进行,那么下一次分裂的操作就会更晚触发;
50%分裂策略的劣势:
空间利用率不高:按照传统50%的页面分裂策略,索引页面的空间利用率在50%左右;
分裂频率较大:针对如上所示的递增插入(递减插入),每新插入两条记录,就会导致最右的叶页面再次发生分裂;
4.2 Inodb的优化:
经过优化,以上的B+树索引,在记录6插入完毕,记录7插入引起分裂之后,新的B+树结构如下图所示:

进行分裂时,如果定位的cursor是当前页的尾部,先试图向右兄弟页插入。如果插入失败,再进行分裂。减少分裂次数。
/* try to insert to the next page if possible before split */
rec = btr_insert_into_right_sibling(
flags, cursor, offsets, *heap, tuple, n_ext, mtr);
if (rec != NULL) {
return(rec);
}优化分裂策略的优势:
- 索引分裂的代价小:不需要移动记录;
- 索引分裂的概率降低:如果接下来的插入,仍旧是递增插入,那么需要插入4条记录,才能再次引起页面的分裂。相对于50%分裂策略,分裂的概率降低了一半;
- 索引页面的空间利用率提高:新的分裂策略,能够保证分裂前的页面,仍旧保持100%的利用率,提高了索引的空间利用率;
优化分裂策略的劣势:如果新的插入,是随机插入,而是插入到原有页面,那么就会导致原有页面再次分裂,增加了分裂的概率。
劣势这里不太理解,需要结合源码去看。
下面贴一下完整的代码。这个是5.6.24版本的。
btr_page_split_and_insert(
/*======================*/
ulint flags, /*!< in: undo logging and locking flags */
btr_cur_t* cursor, /*!< in: cursor at which to insert; when the
function returns, the cursor is positioned
on the predecessor of the inserted record */
ulint** offsets,/*!< out: offsets on inserted record */
mem_heap_t** heap, /*!< in/out: pointer to memory heap, or NULL */
const dtuple_t* tuple, /*!< in: tuple to insert */
ulint n_ext, /*!< in: number of externally stored columns */
mtr_t* mtr) /*!< in: mtr */
{
buf_block_t* block;
page_t* page;
page_zip_des_t* page_zip;
ulint page_no;
byte direction;
ulint hint_page_no;
buf_block_t* new_block;
page_t* new_page;
page_zip_des_t* new_page_zip;
rec_t* split_rec;
buf_block_t* left_block;
buf_block_t* right_block;
buf_block_t* insert_block;
page_cur_t* page_cursor;
rec_t* first_rec;
byte* buf = 0; /* remove warning */
rec_t* move_limit;
ibool insert_will_fit;
ibool insert_left;
ulint n_iterations = 0;
rec_t* rec;
ulint n_uniq;
if (!*heap) {
*heap = mem_heap_create(1024);
}
n_uniq = dict_index_get_n_unique_in_tree(cursor->index);
func_start:
mem_heap_empty(*heap);
*offsets = NULL;
ut_ad(mtr_memo_contains(mtr, dict_index_get_lock(cursor->index),
MTR_MEMO_X_LOCK));
ut_ad(!dict_index_is_online_ddl(cursor->index)
|| (flags & BTR_CREATE_FLAG)
|| dict_index_is_clust(cursor->index));
#ifdef UNIV_SYNC_DEBUG
ut_ad(rw_lock_own(dict_index_get_lock(cursor->index), RW_LOCK_EX));
#endif /* UNIV_SYNC_DEBUG */
block = btr_cur_get_block(cursor);
page = buf_block_get_frame(block);
page_zip = buf_block_get_page_zip(block);
ut_ad(mtr_memo_contains(mtr, block, MTR_MEMO_PAGE_X_FIX));
ut_ad(!page_is_empty(page));
/* try to insert to the next page if possible before split */
rec = btr_insert_into_right_sibling(
flags, cursor, offsets, *heap, tuple, n_ext, mtr);
if (rec != NULL) {
return(rec);
}
page_no = buf_block_get_page_no(block);
/* 1. Decide the split record; split_rec == NULL means that the
tuple to be inserted should be the first record on the upper
half-page */
insert_left = FALSE;
if (n_iterations > 0) {
direction = FSP_UP;
hint_page_no = page_no + 1;
split_rec = btr_page_get_split_rec(cursor, tuple, n_ext);
if (split_rec == NULL) {
insert_left = btr_page_tuple_smaller(
cursor, tuple, offsets, n_uniq, heap);
}
} else if (btr_page_get_split_rec_to_right(cursor, &split_rec)) {
direction = FSP_UP;
hint_page_no = page_no + 1;
} else if (btr_page_get_split_rec_to_left(cursor, &split_rec)) {
direction = FSP_DOWN;
hint_page_no = page_no - 1;
ut_ad(split_rec);
} else {
direction = FSP_UP;
hint_page_no = page_no + 1;
/* If there is only one record in the index page, we
can't split the node in the middle by default. We need
to determine whether the new record will be inserted
to the left or right. */
if (page_get_n_recs(page) > 1) {
split_rec = page_get_middle_rec(page);
} else if (btr_page_tuple_smaller(cursor, tuple,
offsets, n_uniq, heap)) {
split_rec = page_rec_get_next(
page_get_infimum_rec(page));
} else {
split_rec = NULL;
}
}
/* 2. Allocate a new page to the index */
new_block = btr_page_alloc(cursor->index, hint_page_no, direction,
btr_page_get_level(page, mtr), mtr, mtr);
new_page = buf_block_get_frame(new_block);
new_page_zip = buf_block_get_page_zip(new_block);
btr_page_create(new_block, new_page_zip, cursor->index,
btr_page_get_level(page, mtr), mtr);
/* 3. Calculate the first record on the upper half-page, and the
first record (move_limit) on original page which ends up on the
upper half */
if (split_rec) {
first_rec = move_limit = split_rec;
*offsets = rec_get_offsets(split_rec, cursor->index, *offsets,
n_uniq, heap);
insert_left = cmp_dtuple_rec(tuple, split_rec, *offsets) < 0;
if (!insert_left && new_page_zip && n_iterations > 0) {
/* If a compressed page has already been split,
avoid further splits by inserting the record
to an empty page. */
split_rec = NULL;
goto insert_empty;
}
} else if (insert_left) {
ut_a(n_iterations > 0);
first_rec = page_rec_get_next(page_get_infimum_rec(page));
move_limit = page_rec_get_next(btr_cur_get_rec(cursor));
} else {
insert_empty:
ut_ad(!split_rec);
ut_ad(!insert_left);
buf = (byte*) mem_alloc(rec_get_converted_size(cursor->index,
tuple, n_ext));
first_rec = rec_convert_dtuple_to_rec(buf, cursor->index,
tuple, n_ext);
move_limit = page_rec_get_next(btr_cur_get_rec(cursor));
}
/* 4. Do first the modifications in the tree structure */
btr_attach_half_pages(flags, cursor->index, block,
first_rec, new_block, direction, mtr);
/* If the split is made on the leaf level and the insert will fit
on the appropriate half-page, we may release the tree x-latch.
We can then move the records after releasing the tree latch,
thus reducing the tree latch contention. */
if (split_rec) {
insert_will_fit = !new_page_zip
&& btr_page_insert_fits(cursor, split_rec,
offsets, tuple, n_ext, heap);
} else {
if (!insert_left) {
mem_free(buf);
buf = NULL;
}
insert_will_fit = !new_page_zip
&& btr_page_insert_fits(cursor, NULL,
offsets, tuple, n_ext, heap);
}
if (insert_will_fit && page_is_leaf(page)
&& !dict_index_is_online_ddl(cursor->index)) {
mtr_memo_release(mtr, dict_index_get_lock(cursor->index),
MTR_MEMO_X_LOCK);
}
/* 5. Move then the records to the new page */
if (direction == FSP_DOWN) {
/* fputs("Split left\n", stderr); */
if (0
#ifdef UNIV_ZIP_COPY
|| page_zip
#endif /* UNIV_ZIP_COPY */
|| !page_move_rec_list_start(new_block, block, move_limit,
cursor->index, mtr)) {
/* For some reason, compressing new_page failed,
even though it should contain fewer records than
the original page. Copy the page byte for byte
and then delete the records from both pages
as appropriate. Deleting will always succeed. */
ut_a(new_page_zip);
page_zip_copy_recs(new_page_zip, new_page,
page_zip, page, cursor->index, mtr);
page_delete_rec_list_end(move_limit - page + new_page,
new_block, cursor->index,
ULINT_UNDEFINED,
ULINT_UNDEFINED, mtr);
/* Update the lock table and possible hash index. */
lock_move_rec_list_start(
new_block, block, move_limit,
new_page + PAGE_NEW_INFIMUM);
btr_search_move_or_delete_hash_entries(
new_block, block, cursor->index);
/* Delete the records from the source page. */
page_delete_rec_list_start(move_limit, block,
cursor->index, mtr);
}
left_block = new_block;
right_block = block;
lock_update_split_left(right_block, left_block);
} else {
/* fputs("Split right\n", stderr); */
if (0
#ifdef UNIV_ZIP_COPY
|| page_zip
#endif /* UNIV_ZIP_COPY */
|| !page_move_rec_list_end(new_block, block, move_limit,
cursor->index, mtr)) {
/* For some reason, compressing new_page failed,
even though it should contain fewer records than
the original page. Copy the page byte for byte
and then delete the records from both pages
as appropriate. Deleting will always succeed. */
ut_a(new_page_zip);
page_zip_copy_recs(new_page_zip, new_page,
page_zip, page, cursor->index, mtr);
page_delete_rec_list_start(move_limit - page
+ new_page, new_block,
cursor->index, mtr);
/* Update the lock table and possible hash index. */
lock_move_rec_list_end(new_block, block, move_limit);
btr_search_move_or_delete_hash_entries(
new_block, block, cursor->index);
/* Delete the records from the source page. */
page_delete_rec_list_end(move_limit, block,
cursor->index,
ULINT_UNDEFINED,
ULINT_UNDEFINED, mtr);
}
left_block = block;
right_block = new_block;
lock_update_split_right(right_block, left_block);
}
#ifdef UNIV_ZIP_DEBUG
if (page_zip) {
ut_a(page_zip_validate(page_zip, page, cursor->index));
ut_a(page_zip_validate(new_page_zip, new_page, cursor->index));
}
#endif /* UNIV_ZIP_DEBUG */
/* At this point, split_rec, move_limit and first_rec may point
to garbage on the old page. */
/* 6. The split and the tree modification is now completed. Decide the
page where the tuple should be inserted */
if (insert_left) {
insert_block = left_block;
} else {
insert_block = right_block;
}
/* 7. Reposition the cursor for insert and try insertion */
page_cursor = btr_cur_get_page_cur(cursor);
page_cur_search(insert_block, cursor->index, tuple,
PAGE_CUR_LE, page_cursor);
rec = page_cur_tuple_insert(page_cursor, tuple, cursor->index,
offsets, heap, n_ext, mtr);
#ifdef UNIV_ZIP_DEBUG
{
page_t* insert_page
= buf_block_get_frame(insert_block);
page_zip_des_t* insert_page_zip
= buf_block_get_page_zip(insert_block);
ut_a(!insert_page_zip
|| page_zip_validate(insert_page_zip, insert_page,
cursor->index));
}
#endif /* UNIV_ZIP_DEBUG */
if (rec != NULL) {
goto func_exit;
}
/* 8. If insert did not fit, try page reorganization.
For compressed pages, page_cur_tuple_insert() will have
attempted this already. */
if (page_cur_get_page_zip(page_cursor)
|| !btr_page_reorganize(page_cursor, cursor->index, mtr)) {
goto insert_failed;
}
rec = page_cur_tuple_insert(page_cursor, tuple, cursor->index,
offsets, heap, n_ext, mtr);
if (rec == NULL) {
/* The insert did not fit on the page: loop back to the
start of the function for a new split */
insert_failed:
/* We play safe and reset the free bits */
if (!dict_index_is_clust(cursor->index)) {
ibuf_reset_free_bits(new_block);
ibuf_reset_free_bits(block);
}
/* fprintf(stderr, "Split second round %lu\n",
page_get_page_no(page)); */
n_iterations++;
ut_ad(n_iterations < 2
|| buf_block_get_page_zip(insert_block));
ut_ad(!insert_will_fit);
goto func_start;
}
func_exit:
/* Insert fit on the page: update the free bits for the
left and right pages in the same mtr */
if (!dict_index_is_clust(cursor->index) && page_is_leaf(page)) {
ibuf_update_free_bits_for_two_pages_low(
buf_block_get_zip_size(left_block),
left_block, right_block, mtr);
}
#if 0
fprintf(stderr, "Split and insert done %lu %lu\n",
buf_block_get_page_no(left_block),
buf_block_get_page_no(right_block));
#endif
MONITOR_INC(MONITOR_INDEX_SPLIT);
ut_ad(page_validate(buf_block_get_frame(left_block), cursor->index));
ut_ad(page_validate(buf_block_get_frame(right_block), cursor->index));
ut_ad(!rec || rec_offs_validate(rec, cursor->index, *offsets));
return(rec);
}本来还想继续吧page结构接着加上,太长了分片吧。索引的理论部分算是结束了,下一篇是page的结构。
***************************