在以前的mysql版本中,读写分离的实现一般都是基于日志的主从复制实现的,这样会产生一个问题,就是master宕机之后,slave由于同步延时的问题,会导致master和slave内容不同,甚至会多个slave之间互相不同。所以为了解决这个问题,再mysql5.7.6版本之后加入了基于GTID的事务控制,具体的说就是每个事务由一个唯一的gtid标识,当slave都成功执行之后master才写入硬盘完成该事务,如果master突然宕机,那么就自动回滚。数据的一致性得到保证。
操作方法和普通的基于日志的主从复制差不了很多,主要就是打开两个开关
enforce_gtid_consistency = ON
gtid_mode = ON
那么就具体的介绍一下这种主从同步的搭建过程。
Master:
首先要修改mysql的配置文件,我这里的配置文件路径为/etc/mysql/mysql.conf.d/mysqld.cnf,基于docker,不同的版本位置可能会不一样,windows下多数都叫my.cnf,下载地址:https://hub.docker.com/r/alexzhuo/mysql/。
这里只截取要修改的那一段
修改前:
#server-id = 1
#log_bin = /var/log/mysql/mysql-bin.log
expire_logs_days = 10
max_binlog_size = 100M
#binlog_do_db = include_database_name
#binlog_ignore_db = include_database_name修改后
server-id = 1
log_bin = /var/log/mysql/mysql-bin.log
expire_logs_days = 10
max_binlog_size = 100M
#binlog_do_db = include_database_name
#binlog_ignore_db = include_database_name其实就是去掉了两个注释,打开了binlog,必须打开binlog主从之间同步才有据可依。
其中server-id是这个mysql集群中,每个节点都要有自己的id,不能重复,一般master设置为1,slave设置为2,3,4,5.如果这一行被注释掉了,那么slave节点是启动不起来的。
关于binlog_do_db,它是制定哪些库的操作会写入到binlog中,也就是同步哪些库,而binlog_ignore_db是哪些库不写入到binlog中,也就是不同步哪些库。一般情况下可以把这两行注释掉,也就是同步所有的库。在slave节点中也会有这样的配置,但是配置的字段不一样,在slave端进行控制可以降低master的压力,同时还可以精确到某个表是否同步,所以一般在slave节点上进行设置,可见下图:

然后再查看一下同步格式
mysql> show global variables like 'binlog%';
+-----------------------------------------+--------------+
| Variable_name | Value |
+-----------------------------------------+--------------+
| binlog_cache_size | 32768 |
| binlog_checksum | CRC32 |
| binlog_direct_non_transactional_updates | OFF |
| binlog_error_action | ABORT_SERVER |
| binlog_format | ROW |
| binlog_group_commit_sync_delay | 0 |
| binlog_group_commit_sync_no_delay_count | 0 |
| binlog_gtid_simple_recovery | ON |
| binlog_max_flush_queue_time | 0 |
| binlog_order_commits | ON |
| binlog_row_image | FULL |
| binlog_rows_query_log_events | OFF |
| binlog_stmt_cache_size | 32768 |
+-----------------------------------------+--------------+
13 rows in set (0.00 sec)注意这里的binlog_format是个重点,再mysql 5.7版本中,有三种模式,分别是
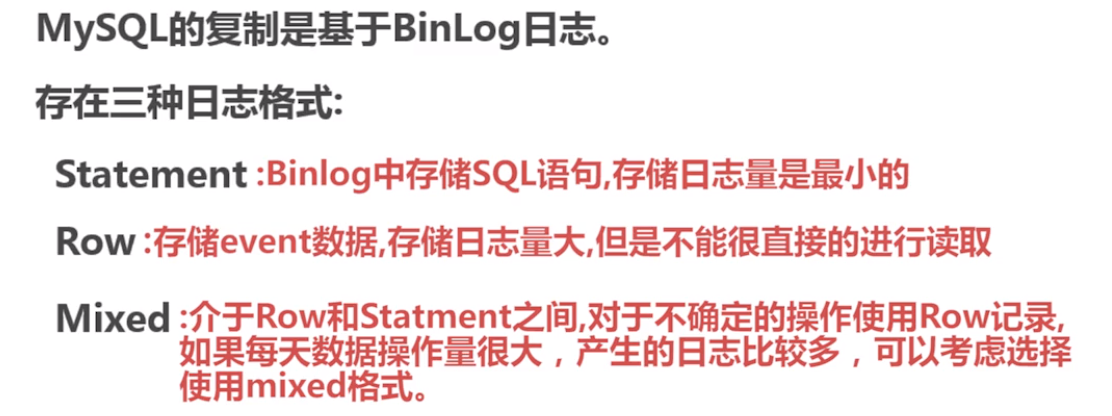
可以根据自己的需要进行选择,默认是row。
然后我们需要在master节点上创建一个用户,然后给它授权专门用来做复制任务,但是它不能select或者修改任何一张表。语句如下:
create user 'dba'@'%' identified by '123456';
grant replication slave on *.* to dba;然后我们就可以将当前数据库的所有内容导出出来,然后导入新的数据库里。当然新的slave数据库也是个docker。导出语句如下
mysqldump --single-transaction --master-data=2 --triggers --routines --all-databases -uroot -p > all.sql如果没有将server-id以及log_bin的注释打开,那么在导出数据库的时候就会报如下错误
root@701cc1949c81:/home/mysql# mysqldump --single-transaction --master-data=2 --triggers --routines --all-databases -uroot -p > all.sql
Enter password:
mysqldump: Error: Binlogging on server not active然后我们就可以再开启一个新的docker,然后导入这个库,当然你首先要把刚才导出的all.sql传输到新docker容器上,导入语句为:
mysql -uroot -p < all.sql然后作为从数据库,我们也要注意两个配置的地方
1是server-id,也要打开,并且不能和master的重复,方法跟上面一样,修改/etc/mysql/mysql.conf.d/mysqld.cnf这个文件。
修改前
#server-id = 1
#log_bin = /var/log/mysql/mysql-bin.log
expire_logs_days = 10
max_binlog_size = 100M
#binlog_do_db = include_database_name
#binlog_ignore_db = include_database_name修改后
server-id = 2
#log_bin = /var/log/mysql/mysql-bin.log
expire_logs_days = 10
max_binlog_size = 100M
#binlog_do_db = include_database_name
#binlog_ignore_db = include_database_name与master不同的是,只修改server-id这一项就可以了,因为slave不需要开启binlog。
2、我们还要修改数据库的UUID,否则启动slave的时候会报错。由于master和slave都是通过同一个docker镜像产生的,所以UUID默认是同一个,需要修改配置文件。
查看当前mysql UUID的命令
mysql> show variables like '%server_uuid%';
+---------------+--------------------------------------+
| Variable_name | Value |
+---------------+--------------------------------------+
| server_uuid | b790fa18-404a-11e7-b542-0242ac110002 |
+---------------+--------------------------------------+解决这个问题的方法是修改/var/lib/mysql/auto.cnf这个文件中的UUID,只要和其他master,slave不同即可,然后重启数据库。如果master和slave不一样,那么start slave之后主从I/O无法进行,并且会报错如下
mysql> show slave status \G
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: 172.17.0.3
Master_User: dba
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 154
Relay_Log_File: 6b901656c610-relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: No
Slave_SQL_Running: Yes
......
Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work.
Last_SQL_Errno: 0
Last_SQL_Error:
......
1 row in set (0.00 sec)这些都做好之后,我们就可以让slave准备开始同步了,指令如下
change master to master_host='Master的IP地址',
-> master_user='dba',
-> master_password='123456',
-> master_log_file='binlog文件名',
-> master_log_pos=数字;第一行要知道master的IP地址和端口,如果是3306端口那么只填写IP地址即可,对于docker容器,可以通过下面命令查找IP
docker inspect <容器ID>
......
"Networks": {
"bridge": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"NetworkID": "cada7bb270b98235a23771daa68c16a0393bf7acdbf9beea824381c0565e716b",
"EndpointID": "195ec54ec8fa862dc45d0ac35db9ece1474276b355eec97bf5186bc72dbe6e7d",
"Gateway": "172.17.0.1",
"IPAddress": "172.17.0.3",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"MacAddress": "02:42:ac:11:00:03",
"DriverOpts": null
}
}这样就可以看到某个容器的IP了,如果你的容器部署在两台机器上,那么你直接做端口映射即可。
master_log_file这个参数一般为binlog.00001(新数据库)或者binlog.0000X(X是自然数,并且会随着时间的推移逐渐增大)。要获取这个binlog的文件名,我们可以去查找刚刚导出的all.sql这个文件,这里面有相关记载,如下
--
-- Position to start replication or point-in-time recovery from
--
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=154;或者在你手动同步master或者slave数据之后(比如sql导入或者直接拷贝数据库文件),可以在master端通过命令看到,如下
mysql> show master status \G
*************************** 1. row ***************************
File: mysql-bin.000001
Position: 154
Binlog_Do_DB:
Binlog_Ignore_DB:
1 row in set (0.00 sec)
这个文件中的MASTER_LOG_FILE对应master_log_file这个参数,MASTER_LOG_POS对应master_log_pos这个参数。于是我的配置命令就变成了:
change master to master_host='172.17.0.3',
-> master_user='dba',
-> master_password='123456',
-> master_log_file='mysql-bin.000001',
-> master_log_pos=154;如果执行成功,可以检查一下是否配置正确,方法是:
mysql> show slave status \G
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: 172.17.0.3
Master_User: dba
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 154
Relay_Log_File: 6b901656c610-relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: No
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
......这里面最重要的两个参数是Slave_IO_Running和Slave_SQL_Running,由于当前还没有开启slave节点,所以两个都是NO,可以通过下面命令开启
start slave;开启之后,上面两个字段如果均为yes说明slave节点同步成功。如果还有NO,那么把报错会显示在Last_IO_Error字段,如下
mysql> show slave status \G
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: 172.17.0.3
Master_User: dba
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 154
Relay_Log_File: 6b901656c610-relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 154
Relay_Log_Space: 154
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1593
Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work.
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID:
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 180527 08:16:18
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)当然这个问题上面已经提供了解决方案。
当Slave_IO_Running和Slave_SQL_Running都是yes后,我们就可以再master节点执行建库,建表,insert,update操作,然后再slave上查看是否同步了数据。
上面已经完成了传统的基于日志的主从复制,下面要开启mysql 5.7的新特性,基于事务的复制,其主要的操作就两点
1、在master和slave上都开启enforce_gtid_consistency
2、在master和slave上都开启gtid_mode
我们在master和slave上均执行下面的操作
首先检查一下是否已经开启了gtid,如果返回是empty那么说明还灭有开启
mysql> show variables like 'grid_mode';
Empty set (0.00 sec)set @@global.enforce_gtid_consistency=warn;
set @@global.enforce_gtid_consistency=on;为什么一个set语句要执行两遍呢,因为这个参数不允许直接从off设置成on,而要off-warn-on的转变的过程。设置完之后,我们查看一下errorlog看有无报错
tail -f /var/log/mysql/error.log
2018-05-27T07:58:22.327301Z 0 [Warning] 'proxies_priv' entry '@ root@localhost' ignored in --skip-name-resolve mode.
2018-05-27T07:58:22.328919Z 0 [Warning] 'tables_priv' entry 'sys_config mysql.sys@localhost' ignored in --skip-name-resolve mode.
2018-05-27T07:58:22.340490Z 0 [Note] Event Scheduler: Loaded 0 events
2018-05-27T07:58:22.341126Z 0 [Note] /usr/sbin/mysqld: ready for connections.
Version: '5.7.18-0ubuntu0.16.04.1-log' socket: '/var/run/mysqld/mysqld.sock' port: 3306 (Ubuntu)
2018-05-27T07:58:22.341233Z 0 [Note] Executing 'SELECT * FROM INFORMATION_SCHEMA.TABLES;' to get a list of tables using the deprecated partition engine. You may use the startup option '--disable-partition-engine-check' to skip this check.
2018-05-27T07:58:22.341274Z 0 [Note] Beginning of list of non-natively partitioned tables
2018-05-27T07:58:22.366089Z 0 [Note] End of list of non-natively partitioned tables
2018-05-27T08:19:47.238163Z 9 [Note] Start binlog_dump to master_thread_id(9) slave_server(2), pos(mysql-bin.000001, 154)
2018-05-27T08:37:15.629583Z 8 [Note] Changed ENFORCE_GTID_CONSISTENCY from OFF to WARN.没有报错就可以查看一下是否成功,然后继续下面的操作了
show global variables like 'enforce_gtid%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| enforce_gtid_consistency | ON |
+--------------------------+-------+set @@global.gtid_mode = off_permissive;
set @@global.gtid_mode = on_permissive;
set @@global.gtid_mode = on;同理,global.gtid_mode这个参数也必须以off-off_permissive-on_permissive-on的过程变化,设置完之后我们同样需要查看一下有无报错日志,然后检查一下是否开启。
show variables like 'gtid_mode';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| gtid_mode | ON |
+---------------+-------+在master和所有slave节点都执行上述命令之后,master节点无需重启。但是slave节点需要重启slave模式,如下
mysql> stop slave;
Query OK, 0 rows affected (0.05 sec)
mysql> change master to master_auto_position=1;
Query OK, 0 rows affected (0.31 sec)
mysql> start slave;
Query OK, 0 rows affected (0.03 sec)这样就完成了slave节点的重启。然后我们立即执行命令观察一下相关参数
mysql> show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.17.0.3
Master_User: dba
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 154
Relay_Log_File: 6b901656c610-relay-bin.000002
Relay_Log_Pos: 367
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 154
Relay_Log_Space: 581
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: b790fa18-404a-11e7-b542-0242ac110002
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)发现和基于日志也没什么不同,只是Master_UUID变成了master节点上/var/lib/mysql/auto.cnf这个文件里写的UUID了。但是当我们再master上执行一下insert或者其他写入操作后,Executed_Gtid_Set这一参数就会有值,而且适合Master_UUID有关联的一个值。更是基于gtid复制是否成功的标志。如下
mysql> show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.17.0.3
Master_User: dba
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 411
Relay_Log_File: 6b901656c610-relay-bin.000002
Relay_Log_Pos: 624
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
......
Retrieved_Gtid_Set: b790fa18-404a-11e7-b542-0242ac110002:1
Executed_Gtid_Set: b790fa18-404a-11e7-b542-0242ac110002:1
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.01 sec)然后我们检查一下相关建库建表插入操作是否同步成功即可。
注意,如果按照上面的配置,手动将enforce_gtid_consistency和gtid_mode设置为ON之后,如果你重启了容器或者mysql服务,再次启动时会发现没有自动同步,Slave_IO_Running和Slave_SQL_Running都是NO,start slave时会报错,如下
mysql> show slave status \G
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: 172.17.0.3
Master_User: dba
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 411
Relay_Log_File: 6b901656c610-relay-bin.000002
Relay_Log_Pos: 624
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: No
Slave_SQL_Running: Nomysql> start slave
-> ;
ERROR 3112 (HY000): The replication receiver thread for channel '' cannot start in AUTO_POSITION mode: this server uses @@GLOBAL.GTID_MODE = OFF.这是因为重启mysql服务后需要重新按照上面的方法手动设置enforce_gtid_consistency和gtid_mode为ON,当然这样太麻烦了,应该写在mysql配置文件my.cnf里,这样每次启动就会自动开启同步模式,无需再手动执行任何命令。方法就是再my.cnf文件末尾加入
vi /etc/mysql/mysql.conf.d/mysqld.cnf
......
enforce_gtid_consistency = ON
gtid_mode = ON
当你把master和slave两个docker保存好,迁移到其他机器上或者宕机重启之后,或者master更换IP之后,你会发现slave端经常起不来。报错如下
mysql> start slave;
ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository这是因为master或者slave重启之后,原先的binlog就对不上了,需要我们手动重置slave节点,master不用动,好在gtid的设置不用再来一遍了,slave端执行如下命令。
mysql> reset slave;
mysql> start slave;注意,由于上面在开启gtid模式的时候设置了
change master to master_auto_position=1;
语句,所以如果此时重新执行change master语句,那么里面的
-> master_log_file='binlog文件名',
-> master_log_pos=数字;
会导致不能成功,因为gtid模式下,会自动的同步这两个参数,如果实在想通过手动方式设置binlog的位置的行数,那么需要先change master to master_auto_position=0;
由于gtid模式下不需要填binlog文件名和行数了,如果你的master节点IP变化了,那么只需重新设置master的IP即可,注意之后还要reset slave和start slave;
change master to master_host='Master的IP地址',
-> master_user='dba',
-> master_password='123456'
reset slave;
start slave;一步到位直接开启GTID模式
上面提供的方案中,是先开启普通的日志复制模式,然后再采用基于GTID的复制模式,如何一步到位直接开启gtid模式呢。方法其实很简单,因为在gtid模式下,可以自动定位master binlog的文件名和行数,所以省去了去master服务器查看的麻烦。只要master和slave数据首先一模一样(通过mysqldump导入),同时master没有任何操作(需要将3306上所有连接都断开)。然后直接使用change master命令即可。详细过程如下
1、Master的配置还和上面一样。需要打开binlog,并开启enforce_gtid_consistency和gtid_mode(如果嫌每次启动master都要手动开启太麻烦,那么就把这两项写到my.cnf中,上面有提到)
2、Slave的配置文件my.cnf中加入
enforce_gtid_consistency = ON
gtid_mode = ON并且别忘了修改serverid
server-id = 2启动之后,通过change master语句设置master的IP地址,无需设置binlog的位置和行数,只需保证目前的库和master库内容一致即可
change master to master_host='Master的IP地址',
-> master_user='dba',
-> master_password='123456'
start slave;mysql> show slave status \G