概述
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
——摘自《百度百科》
版权说明
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。
本文作者:Q-WHai
发表日期: 2016年6月13日
本文链接:http://blog.csdn.net/lemon_tree12138/article/details/51659657
来源:CSDN
更多内容:分类 >> 大数据之 Hadoop
前言
在很多大数据的应用场景中我们都有可能看到倒排索引的身影,我第一次接触倒排索引是在学习 Lucene 全文检索框架的时候。本文会从倒排索引开始说明,再补充讲解倒排索引文档及带权重的倒排索引文档。你是不是想说这些不都是同一个东西么?显然,他们不是同一个东西。
倒排索引
根据上面的概述所言,我相信你应该已经对倒排索引的原理有了一个初步的认识。如果你有一些编程的功底,那么基于某种编程语言写一个倒排索引的程序应该不难。只是如何将这个倒排索引程序翻译成 Hadoop 中 的 MapReduce 程序呢?这是需要探讨的问题。
如果你理解了前面的 WordCount 程序的话,尤其是 Mapper 和 Reducer 的过程,那么倒排索引对你来说也就是一菜一碟了。
输入的文件格式
要让 MapReduce 程序正确的运行,我们首先要确保 MapReduce 的输入是正确的。反映在文件中就是文件的格式需要提前被规定好。现在我们的文件输入格式定义如下:
<key_name>:<value1> <value2> <value3> ... <value4>在输入的格式中,我们把 key 与 values 用英文冒号( : )分隔开了。而 value 与 value 之间则是使用空格分隔开。
假设这里的 key 是一个代表文件的文件名称,后面的 values 则是文件中的内容(单词)。根据格式我们编写了如下的几组测试样例:
file01
file01:hello world hello todayfile02
file02:hi today funny dayfile03
file03:face day face world分布式运行的过程
对于文件从本地上传到 HDFS 的过程不是本文的讨论范围,如果你感兴趣可以查阅相关资料,理解上也并不困难。
当倒排索引的 MR 程序运行时,其过程大致可以用下图进行表示:
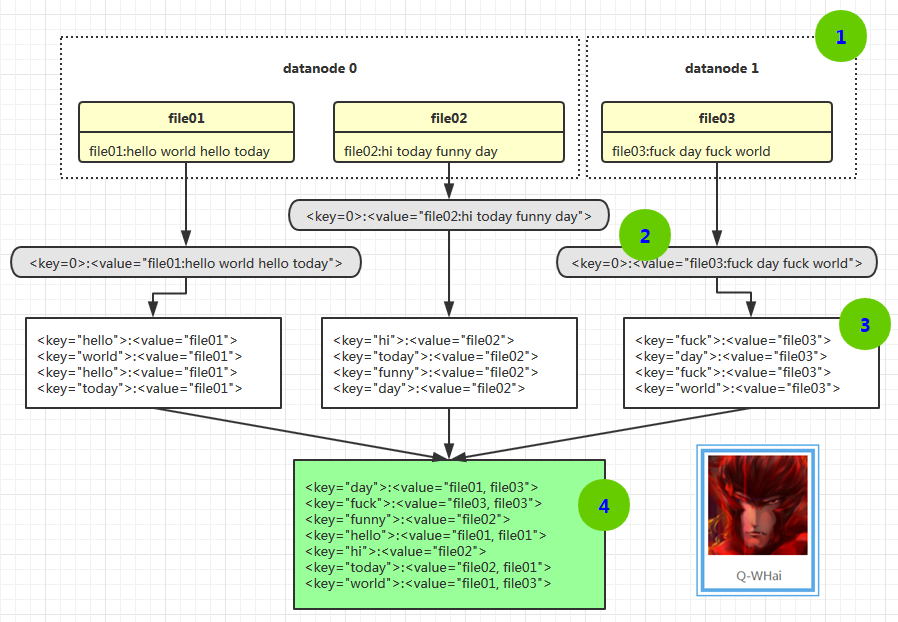
- 首先我们从 HDFS 的 DataNode 节点上读取数据(读取时是随机读取每个数据备份中的一个)。比如,file01 和 file02 是在 datanode0 上读取的,而 file03 是在 datanode1 上读取的;
- 在读取文件时,是以行为单位进行读取,每一行都将以行号作为 key,这一行的本文作为 value 读取,并将此 key:value 传入 Mapper;
- 经过 Mapper.map() 函数的处理,会形成以本文内容为 key,文本的第一个 word 为 value 的局部倒排索引序列。就像上图中的 3 号位置所示;
- 将第 3 步形成的局部倒排索引进行 Reducer.reduce() 函数的整合形成最终结果。
MapReduce 程序编写
这里的代码逻辑与代码结构与之前的 WordCount 程序有很多相似的地方。而与 WordCount 程序不同的是,InvertedIndex 在 Mapper 中需要对文件中的内容进行区别对待,因为文件的最开始是文件名的 key;在 Reducer 中累加的不是单词的个数,而是 value 字符串的适当叠加。具体代码如下:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
public class InvertedCoreMR {
public static class CoreMapper extends Mapper<Object, Text, Text, Text> {
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
String[] splits = value.toString().split(":");
StringTokenizer tokenizer = new StringTokenizer(splits[1]);
while (tokenizer.hasMoreTokens()) {
context.write(new Text(tokenizer.nextToken()), new Text(splits[0]));
}
}
}
public static class CoreReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
if (null == values) {
return;
}
StringBuffer filesBuffer = new StringBuffer();
boolean firstFlag = true;
for (Text invertedFile : values) {
filesBuffer.append((firstFlag ? "" : ", ") + invertedFile.toString());
firstFlag = false;
}
context.write(key, new Text(filesBuffer.toString()));
}
}
}InvertedIndex 的客户端程序与 WordCount 的客户端基本上是一样的。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.demo.index.inverted.core.InvertedCoreMR;
public class InvertedClient extends Configuration implements Tool {
public static void main(String[] args) {
InvertedClient client = new InvertedClient();
try {
ToolRunner.run(client, args);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public Configuration getConf() {
return this;
}
@Override
public void setConf(Configuration arg0) {
}
@Override
public int run(String[] args) throws Exception {
Job job = new Job(getConf(), "File Inverted Index");
job.setJarByClass(InvertedCoreMR.class);
job.setMapperClass(InvertedCoreMR.CoreMapper.class);
job.setReducerClass(InvertedCoreMR.CoreReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
}
结果展示
day file02, file03
face file03, file03
funny file02
hello file01, file01
hi file02
today file02, file01
world file01, file03优化
在上面的结果展示中可以看到 face 和 hello 这两个单词分别出现在了两个相同的文件中。这不是一个好的用户体验,所以需要优化。优化的逻辑就是过滤。如果你有一些项目经验的话,你可能会已经想到要 BloomFilter 或是字典树之类的。这两种过滤方案的确是很好的,只是这里我就不使用 BloomFilter 和字典树了,感觉有一些“大材小用”了。直接使用 Java 提供的 HashSet 会更好一些。我一直比较提倡的做法就是,不要在一个小功能上使用大工具或是大框架,这样会让你的程序显得臃肿肥大,且没有什么实用价值。
可能你会说这里不应该直接使用过滤,应该进行词频的统计。是的,的确是要做词频统计,你先别急,咱们一步步来,后面会作介绍的。现在只对重复的文件名进行过滤就 ok 了。
import java.util.HashSet;
import java.util.Set;
... ( 此处省略 N 行 ) ...
public class InvertedCoreMR {
public static class CoreMapper extends Mapper<Object, Text, Text, Text> {
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
... ( 此处省略 N 行 ) ...
Set<String> filterSet = new HashSet<>();
while (tokenizer.hasMoreTokens()) {
String label = tokenizer.nextToken();
if (filterSet.contains(label)) {
continue;
}
filterSet.add(label);
... ( 此处省略 N 行 ) ...
}
}
}
public static class CoreReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
... ( 此处省略 N 行 ) ...
Set<String> filterSet = new HashSet<>();
for (Text invertedFile : values) {
if (filterSet.contains(invertedFile.toString())) {
continue;
}
filterSet.add(invertedFile.toString());
... ( 此处省略 N 行 ) ...
}
context.write(key, new Text(filesBuffer.toString()));
}
}
}
修改之后,结果就要好用得多了。
day file03, file02
face file03
funny file02
hello file01
hi file02
today file02, file01
world file01, file03倒排索引文档
在上面的倒排索引中,我们是人为给文件添加 key,也就是文件名来达到单词映射文件名的目的。可是,如果我们的输入文件中并不符合我们 MapReduce 程序的格式要求,那么之前的做法就与我们的愿望相悖了。我们要让文档检索的时候更具一般性,那么就不能限定文件名,而是应该让程序去动态获取。
所以,这里我们首先介绍一下在 MapReduce 程序中如何动态获取文件名,这一点是关键。
动态获取文件名需要用到的两个类分别是:InputSplit, FileSplit
它们所在的包名分别为:
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;我们可以在 Mapper 中通过如下两句代码获取文件名:
InputSplit inputSplit = context.getInputSplit();
String fileName = ((FileSplit)inputSplit).getPath().toString();于是,我们修改了 CoreMapper.map() 方法:
public static class CoreMapper extends Mapper<Object, Text, Text, Text> {
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
InputSplit inputSplit = context.getInputSplit();
String fileName = ((FileSplit)inputSplit).getPath().toString();
StringTokenizer tokenizer = new StringTokenizer(value.toString());
Set<String> filterSet = new HashSet<>();
while (tokenizer.hasMoreTokens()) {
String label = tokenizer.nextToken();
if (filterSet.contains(label)) {
continue;
}
filterSet.add(label);
context.write(new Text(label), new Text(fileName));
}
}
}运行 Hadoop 程序,然后,我们就可以得到如下的结果:
day file:/home/hadoop/temp/inverted/file03, file:/home/hadoop/temp/inverted/file02
face file:/home/hadoop/temp/inverted/file03
funny file:/home/hadoop/temp/inverted/file02
hello file:/home/hadoop/temp/inverted/file01
hi file:/home/hadoop/temp/inverted/file02
today file:/home/hadoop/temp/inverted/file02, file:/home/hadoop/temp/inverted/file01
world file:/home/hadoop/temp/inverted/file01, file:/home/hadoop/temp/inverted/file03这样我们就完成了更加一般性的倒排索引文档方案,程序的运行结果也展示了我们想要达到的效果。
带权重的倒排索引文档
上面对文档中的重复数据是采用 HashSet 过滤,而在实际应用中我们不能这样一概而论。比如,文档 Doc1 中单词总数为 100 个,单词 word1 的个数为 20 个,比率为 20% ;而文档 Doc2 中的单词总数为 1000 个,单词 word1 的个数为 30 个,比率为 3%。如果我们不进行词频统计,那么这两个文档中 word1 的重要性是一样的。这显然与实际情况相悖。
所以这里我们还需要对每个单词进行词频统计。
我们修改了 Mapper.map() 方法,具体代码如下:
public static class CoreMapper extends Mapper<Object, Text, Text, Text> {
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
InputSplit inputSplit = context.getInputSplit();
String fileName = ((FileSplit)inputSplit).getPath().toString();
StringTokenizer tokenizer = new StringTokenizer(value.toString());
Map<String, Integer> freqMap = new HashMap<String, Integer>();
while (tokenizer.hasMoreTokens()) {
String label = tokenizer.nextToken();
if (freqMap.containsKey(label)) {
freqMap.put(label, freqMap.get(label) + 1);
} else {
freqMap.put(label, 1);
}
context.write(new Text(label), new Text(fileName + "," + freqMap.get(label)));
}
}
}上面代码的逻辑就是,如果发现一个单词已经存在就将其记数器 +1. 如果单词不存在,就新建记数器。记数器的选择是 HashMap,这很好用,而且方便轻巧。
在 Reducer.reduce() 方法中需要修改的地方不多,因为要展示词频,所以首先要获取词频,并把词频在结果中显示出来即可。具体代码如下:
public static class CoreReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
if (null == values) {
return;
}
StringBuffer filesBuffer = new StringBuffer();
boolean firstFlag = true;
Set<String> filterSet = new HashSet<String>();
for (Text invertedFile : values) {
String fileName = invertedFile.toString().split(",")[0];
int wordFreq = Integer.parseInt(invertedFile.toString().split(",")[1]);
if (filterSet.contains(fileName)) {
continue;
}
filterSet.add(fileName);
filesBuffer.append((firstFlag ? "[" : ", [") + fileName + " : " + wordFreq + "]");
firstFlag = false;
}
context.write(key, new Text(filesBuffer.toString()));
}
}修改后的结果展示
day [file:/home/hadoop/temp/inverted/file02 : 1], [file:/home/hadoop/temp/inverted/file03 : 1]
face [file:/home/hadoop/temp/inverted/file03 : 2]
funny [file:/home/hadoop/temp/inverted/file02 : 1]
hello [file:/home/hadoop/temp/inverted/file01 : 2]
hi [file:/home/hadoop/temp/inverted/file02 : 1]
today [file:/home/hadoop/temp/inverted/file02 : 1], [file:/home/hadoop/temp/inverted/file01 : 1]
world [file:/home/hadoop/temp/inverted/file01 : 1], [file:/home/hadoop/temp/inverted/file03 : 1]上面就是整个倒排索引的全部内容了,如果你任何疑问,欢迎留言。一起讨论,一起进步。后面,我将更新 N 个 MapReduce 共同执行和 TF-IDF 的 MapReduce 实现(网络上的那些 MR 版的 TF-IDF 文章有点看不下去了。。。),敬请期待。