pickle
可以将任何数据类型转为字符串;但是pickle之后的结果也只有python可以看懂,而且反序列化依靠python代码;
pickle 和 json 很像 都是有dumps loads dump 和 load 四个方法;
但是 pickle 序列化之后的结果是一串二进制(bytes类型)所以pickle 在使用 dump 和 load 进行和文件相关的操作时 需要以二进制的方式打开文件,加上b;
1. pickle.dumps()---将任何数据类型进行序列化(pickle序列化的结果是bytes类型)
pickle.loads()---反序列化,转回原来的数据类型;
import pickle dict={'a':1,'b':2,'c':3} print(dict,type(dict)) str_dic=pickle.dumps(dict) # 使用pickle.dumps()将字典序列化 print(str_dic,type(str_dic)) dic_2=pickle.loads(str_dic) print(dic_2,type(dic_2))
运行结果:

2. pickle.dump() -----文件操作有关,注意此时文件必须以二进制方式打开,序列化;
pickle.load()--- 反序列化,文件必须以二进制方式打开;
pickle.dump()和 pickle.load() 可以对多个数据类型进行写入文件操作,然后一个一个读出来,也就是支持多次dump 和 多次load (json.dump() 和 json.load()是不直接支持这种操作的)
import pickle dic={'a':1,'b':2,'c':3} f=open('info','wb') # pickle.dump()在对数据类型进行序列化时,文件比如以二进制方式打开,但是encoding=utf-8就不需要了,因为本身bytes类型就是utf-8 pickle.dump(dic,f) # pickle.dump()是没有返回值的,但是pickle.dumps() pickle.loads() pickle.load()都有返回值 f.close() f=open('info','rb') # pickle.load()在进行反序列化时,文件也必须是二进制方式打开; dic_2=pickle.load(f) print(dic_2,type(dic_2)) f.close()
运行结果:
然而此时dump进文件的内容是看不懂的~并且会生成三个文件:
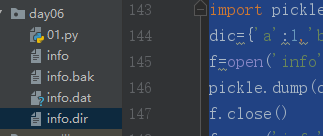
再来看pickle.dump() pickle.load() 多次dump 和 多次load 的情况(json.dump() 和 json.load()是不支持的)
import pickle import time struct_time1=time.localtime(1600000000) # 这次使用的数据类型是结构化元组(struct_time数据类型) struct_time2=time.localtime() f=open('info','wb') pickle.dump(struct_time1,f) # 对struct_time这种数据类型进行多次dump pickle.dump(struct_time2,f) f.close() f=open('info','rb') struct_time1=pickle.load(f) # 对刚才序列化之后的结果多次load struct_time2=pickle.load(f) print(struct_time1,type(struct_time1)) print(struct_time2) print(struct_time1.tm_year) print(struct_time2.tm_year)
运行结果:
