一、正则表达式
使用/etc/passwd文件来练习
1.范围内字符
(1)单个字符 []
数字字符:[0-9],[259]
小写字符:[a-z]
大写字符:[A-Z]
小写,大写字符:[a-zA-Z]
grep '1' passwd #匹配单个字符1
grep 'a' passwd #匹配单个字符a
grep '[0-9]' passwd #匹配单个字符,该字符为0-9中间的任意一个数字

grep '[259]' passwd #匹配单个字符,该字符为2或5或9中间的任意一个数字
grep '[,:_/]' passwd
(2)反向字符^
取反:[^0-9],[^0]
grep '[^0-9]' passwd #匹配除数字以外的所有单个字符
(3)任意字符
代表任何一个字符: '.'
grep '.' passwd
注意:[.]和\.都表示点号本身
grep '[.]' passwd
grep '\.' passwd
2.其他符号
(1)边界字符:头尾字符
^:^root 表示以root开头的字符(注意与[^]的区别)
$:false$ 表示以false结尾的字符
空行的表示:^$
grep '^root' passwd
grep 'false$' passwd
grep '^$' passwd
(2)元字符(代表普通字符或特殊字符)
\w:匹配任何字类字符,包括下划线([A-Za-z0-9_])
\W:匹配任何非字类字符([^A-Za-z0-9_])
\b:代表单词的分隔
grep '\w' passwd
grep '\W' passwd
grep '\bx\b' passwd
3.重复字符表示
(1)字符串(重复,逻辑)
'root' '1000' 'm..c'(长度为4的字符,以m开头,c结尾)
[A-Z][a-z](将一个大写字母和一个小写字母放在一起的组合)
[0-9][0-9](两个数字的组合)
还可以写成 grep -P '\d{2}' passwd(https://blog.csdn.net/yufenghyc/article/details/51078107)
*1重复
*:零次或多次匹配前面的字符或子表达式 {0,}
+:一次或多次匹配前面的字符或子表达式 {1,}
?:零次或一次匹配前面的字符或子表达式 {0,1}
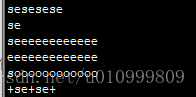
sesesese
se
seeeeeeeeeeee
eeeeeeeeeeeee
soooooooooooo
+se+se+grep 'se*' test.txt
#这个可以匹配
sesesese
se
seeeeeeeeeeee
soooooooooooo
+se+se+
grep 'se+' test.txt
#这个可以匹配
+se+se+
和我们预想的不太一样,因为grep在这里把+号当成了普通符号,没有当做正则的特有符号来处理
grep 'se\+' test.txt
#这个可以匹配
sesesese
se
seeeeeeeeeeee
+se+se+
grep 'se\?' test.txt
#这个可以匹配(问号作为重复字符,也不能直接使用,必须使用转义符)
sesesese
se
seeeeeeeeeeee
soooooooooooo
+se+se+
grep '\(se\)*' test.txt
#这个可以匹配(se不断重复)
sesesese
se
seeeeeeeeeeee
eeeeeeeeeeeee
soooooooooooo
+se+se+
grep '\(se\)+' test.txt
#这个可以匹配
sesesese
se
seeeeeeeeeeee
+se+se+
grep '\(se\)\?' test.txt
#这个可以匹配
sesesese
se
seeeeeeeeeeee
eeeeeeeeeeeee
soooooooooooo
+se+se+
重复特定次数:{n,m}
grep '[0-9]\{2,3\}' passwd #字符个数为2-3个,且均为数字的字符组合
*2逻辑
任意字符串的表示:.*
例如: ^r.* m.*c
m..c和m.*c的区别:
m..c 以m开头和c结尾,长度为4的字符串
m.*c 以m开头和c结尾,长度任意的字符串
grep 'bin/\(bash\|sync\)' passwd #匹配bin\后面接的是bash或者是sync的字符串举例:
grep '^[0-9]\{4,10\}$' test.txt #匹配4-10位的数字
grep '^[1-9]\([0-9]\{13\}\|[0-9]\{16\}\)[0-9xX]$' test.txt #匹配15位或18位身份证号码(支持带X的)
grep '^\w\+$' #匹配密码(由数字、26个字母和下划线组成)二、sed命令
1.sed基本操作(-p 打印)
sed -n 'p' passwd #打印文件的所有行
sed -n '10p' passwd #打印文件的第10行
nl passwd | sed -n '10p' #先给文件标上行号,然后打印第10行内容
sed -n '/mooc/p' passwd #打印/mooc/所定位到的行
nl passwd | sed -n '10,20p' #打印10~20行的内容
nl passwd | sed -n '/uucp/,/ntp/p' #打印由/uucp/和/ntp/所定位到的行之间的内容,
(假如分别为10行,20行,则打印的为10~20行的内容)
nl passwd | sed -n '10!p' #打印除第10行以外的所有行的内容
nl passwd | sed -n '10,20!p' #打印排除了10~20行以外的所有行的内容
nl passwd | sed -n '/uucp/,/ntp/!p' #打印排除由/uucp/和/ntp/所定位到的行之间的内容以外的内容,
(假如分别为10行,20行,则打印的为除了10~20行以外的内容)
nl passwd | sed -n '1~2p' #打印奇数行(1为初始值,2为步长)
2.基本操作命令-行处理命令
-a (新增行)/ -i (插入行)
-c (替代行)
-d (删除行)
nl passwd | sed '5a ========================' #在第5行的后面添加分隔符号(一长串的等号)
nl passwd | sed '1,5a ========================' #在第1~5行的每一行后面添加分隔符号
nl passwd | sed '5i ========================' #在第5行的前面添加分隔符号
nl passwd | sed '1,5i ========================' #在第1~5行的每一行前面添加分隔符号
nl passwd | sed '30c aaaaaadfjklsdjfskljfd' #将第30行替换成敲入的字符
nl passwd | sed '30,32c aaaaaadfjklsdjfskljfd' #将第30~32行全部替换成敲入的字符
nl passwd | sed '/mooc/d' #删除/mooc/匹配到的所在行
例子1.将一小段文字追加到指定文本文件后(优化配置文件)
添加前

sed '$a \ port52113\n permitrootlogin no ' test.txt
添加后

例子2.删除文本空行
删除前

sed '/^$/d' test.txt
例子3.服务器日志处理(服务器log找出error报错信息)
sed -n '/Error/p' test.log
3.基本操作命令-s替换命令
-s(替换):分隔符 / , #等
sed 's/false/true/' passwd #将false替换为true,每行被匹配到的第一个会被替换掉
sed 's/:/%/g' passwd #将所有的冒号替换为百分号(如果不加g,则替换每一行中第一个被匹配到的)
例子1.获取eth0的ip
查看下本机启用的网卡 ifconfig
从ifconfig eth0在页面上打印的结果中,截取出ip地址
ifconfig eth0 | sed -n '/inet /p' | sed 's/inet.*r://' | sed 's/B.*$//'
说明:r 表示取消正则默认的贪婪匹配模式,
/B 表示空格
4.sed高级操作命令{}n
-{}:多个sed命令,用;分开
nl passwd | sed '{20,30d;s/false/true/}' #先将20~30行删除,然后将每行匹配的第一个false替换为true
-n:读取下一个输入行(用下一个命令处理)
nl passwd | sed -n '{n;p}' #打印偶数行(或者nl passwd | sed -n '2~2p')
nl passwd | sed -n '{p,n}' #打印奇数行(或者nl passwd | sed -n '1~2p')
nl passwd | sed -n '{n;n;p}' #打印3,6,9,...行
5.sed高级操作命令&
&:替换固定字符串
sed 's/^[a-z_-]\+/& /' passwd #将passwd中的所有用户名后面都加上一部分空格
例子1.大小写转换
(1)将用户名的首字母转换为大写/小写
(元字符\u \l \U \L:转换为大写/小写字符)
sed 's/^[a-z_-]\+/\u&/' passwd #用户名首字母转换为大写(2)将文件夹下的.txt文件名转换为大写
ls *.txt|sed 's/^\w\+/\U&/'(如果文件名只是小写字符,可以写成
ls *.txt|sed 's/^[a-z]\+/\U&/')6.sed高级操作命令()
-\( \):替换某种(部分)字符串(\1,\2)
例子1.获取eth0的ip
ifconfig eth0|sed -n '/inet /p'|sed 's/inet.*r:\([0-9.]\+\).*$/\1/'例子2.获取passwd的用户名,uid,gid
sed 's/\(^[a-z_-]\+\):x:\([0-9]\+\):\([0-9]\+\):.*$/USER:\1 UID:\2 GID:\3/' passwd7.sed高级操作命令rw
-r:复制指定文件插入到匹配行
-w:复制匹配行拷贝指定文件里
创建一个全是数字的文件123.txt
echo -e '38090239392\n392039390239\n883923838239' > 123.txt
创建一个全是字母的文件abc.txt
echo -e 'ksdsksdfs\nsdflkjkf\nmnjkdfhsdhfkdfff' > abc.txt
sed '1r 123.txt' abc.txt #将123.txt的全部内容读到abc.txt的第一行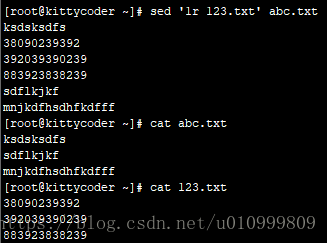
sed '1w abc.txt' 123.txt #将123.txt的第一行写到abc.txt中(直接覆盖abc.txt的原有内容)
sed 'w abc.txt' 123.txt #将123.txt的所有内容写到abc.txt中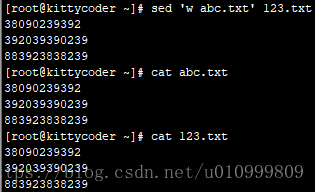
说明:r和w的区别========r不会改变目标文件内容,w会改变目标文件内容
8.sed高级操作命令q
(1)打印到第10行就退出sed

(2)找到第一个nologin就退出sed

三、awk命令
1.awk内置参数
(1)awk内置参数:分隔符
options:-F field-separator(默认为空格)
例如:$awk -F ':' '{print $3}' /etc/passwd
awk -F ':' '{print $1,$3,$4}' passwd #将每行打印的字符用空格分隔
awk -F ':' '{print "USER:"$1"\tUID:"$3"\tGID:"$4}' passwd #给每行打印的字符添加说明文字(USER,UID,GID)
(2)NR:每行的记录号(行号)
NF:字段数量变量(字段总数,列号)
FILENAME:正在处理的文件名
awk -F ':' '{print NR,NF}' passwd
awk -F ':' '{print FILENAME}' passwd
2.awk内置参数应用
例子1.显示/etc/passwd每行的行号,每行的列数,
对应行的用户名(print,printf)
awk -F ':' '{print "Line:"NR,"Col:"NF,"USER:"$1}' passwd
awk -F ':' '{printf("Line:%3s Col:%s User:%s\n",NR,NF,$1)}' passwd #3表示字符占位为3个格子,能让打印出来的样子更整齐
例子2.显示/etc/passwd中用户ID大于100的行号和用户名(if...else...)
awk -F ':' '{if ($3>100) print "Line:"NR,"USER:"$1}' passwd
(验证 awk -F ':' '{if ($3>100) print "Line:"NR,"UID:"$3,"USER:"$1}' passwd)
例子3.在服务器log中找出“Error”的发生日期
sed '/Error/p' fresh.log | awk '{print $1}'
awk '/Error/{print $1}' fresh.log
3.awk逻辑判断式
~,!~ :匹配正则表达式
==,!=,<,>:判断逻辑表达式
awk -F ':' '$1~/^m.*/{print $1}' passwd #将以m开头的用户名打印出来
awk -F ':' '$1!~/^m.*/{print $1}' passwd #将所有不是以m开头的用户名打印出来
awk -F ':' '$3>100{print $1,$3}' passwd #将用户id大于100的用户名和用户id打印出来
awk -F ':' '$3<100{print $1,$3}' passwd #将用户id小于100的用户名和用户id打印出来
awk -F ':' '$3==100{print $1,$3}' passwd #将用户id等于100的用户名和用户id打印出来
awk -F ':' '$3!=100{print $1,$3}' passwd #将用户id不等于100的用户名和用户id打印出来
4.awk扩展格式
command扩展
BEGIN{print "start"}pattern{commands}END{print "end"}
例子1.制表显示/etc/passwd每行的行号,每行的列数,对应行的用户名
awk -F ':' 'BEGIN{print "Line Col User"}{print NR,NF,$1}END{print "------------"FILENAME"------------"}' passwd
综合
例子:假设现在有一个mysql的脚本act_ge.sql,需要将values后面逗号分隔的第一列和第五列提取出来
INSERT INTO "JBIT_TEST"."ACT_GE_BYTEARRAY" VALUES ('641953', '1', 'assigneeList', NULL, HEXTORAW('ACED0005737200136A6176612E7574696C2E41727261794C6973747881D21D99C7619D03000149000473697A657870000000017704000000017400043738383778'), NULL, NULL);
INSERT INTO "JBIT_TEST"."ACT_GE_BYTEARRAY" VALUES ('290442', '1', 'assigneeList', NULL, HEXTORAW('ACED0005737200136A6176612E7574696C2E41727261794C6973747881D21D99C7619D03000149000473697A657870000000017704000000017400043839303078'), NULL, NULL);
INSERT INTO "JBIT_TEST"."ACT_GE_BYTEARRAY" VALUES ('641954', '1', 'assigneeList', NULL, HEXTORAW('ACED0005737200136A6176612E7574696C2E41727261794C6973747881D21D99C7619D03000149000473697A657870000000017704000000017400043738383778'), NULL, NULL);
INSERT INTO "JBIT_TEST"."ACT_GE_BYTEARRAY" VALUES ('293765', '1', 'assigneeList', NULL, HEXTORAW('ACED0005737200136A6176612E7574696C2E41727261794C6973747881D21D99C7619D03000149000473697A657870000000017704000000017400043738383778'), NULL, NULL);
INSERT INTO "JBIT_TEST"."ACT_GE_BYTEARRAY" VALUES ('293764', '1', 'assigneeList', NULL, HEXTORAW('ACED0005737200136A6176612E7574696C2E41727261794C6973747881D21D99C7619D03000149000473697A657870000000017704000000017400043738383778'), NULL, NULL);grep '"JBIT_TEST"."ACT_GE_BYTEARRAY" VALUES' act_ge.sql | sed -n 's/.*VALUES (\(.*\));.*/\1/p' | awk -F ', ' '{print "lid "$1" xml" $5}'补充:
只获取括号内的字符:
echo 'abc(defgh)igk' | sed -n 's/.*(\(.*\)).*/\1/p'前面获取eth0的ip还能写成
ifconfig eth0 | sed -n 's/.*inet addr:\([0-9.]\+\).*/\1/p'