1、grep
可以使用grep 命令可以进行过滤搜索
aaa.txt 的内容
2018-11-26
hello world!
hadoop01 bigdata
192.168.136.138
2018-09-21
2018-09-12 spark scala
从aaa.txt中搜索一个固定的词语,通过结果可以看出每次搜索,只要有这个词语,就会把一整行都显示出来
(1) grep “2018-11-26” aaa.txt
(2)cat aaa.txt | grep “2018”
结果
2018-11-26
2018-09-21
2018-09-12 spark scala
使用正则表达式进行搜索
grep “[0-9]{4}-[0-9]{2}-[0-9]{2}” aaa.txt
这里是使用正则表达式对文本内容进行搜索,搜索的格式xxxx-xx-xx (x的范围在0-9) \是进行转义
结果:
2018-11-26
2018-09-21
2018-09-12 spark scala
使用正则搜索 ip格式的数据 (不太准确,可能会出现999.999.999.999,这个根本就不可能是IP)
grep “[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}” aaa.txt
192.168.136.138
取反
这里/etc/passwd是存放一些用户的信息,
想要找在这里搜索出普通用户,通过观察发现 用户信息都是/bin/bash 结束
使用grep先搜索到 /bin/bash ,再使用grep -v " root" 把是root用户的删除,
grep “/bin/bash” /etc/passwd | grep -v “root”
结果:
bigdata: x: 500:500::/home/bigdata:/bin/bash
2、cut
可以使用cut对数据进行切分
cut命令默认切分时是按照\t进行切分,也可以自己设定切分的字符,通过-F,下面汇聚一些具体的例子
student.txt 的数据, 分隔符是\t
id name gender mark
01 zh man 70
02 ty woman 77
02 ym woman 80
03 cx woman 80
(1) 取出数据中的第三列 ,
cut -f 3 student.txt
gender
man
woman
woman
woman(2) 取出1到3 列
cut -f 1-3 student.txt
(3)取出第1、第3列
cut -f 1,3 student.txt
只取出普通用户的用户名
在grep取反时,使用了以下的一部分命令,使用 cut 按 : 进行切分,再取出第一个,也就是普通用户名
grep “/bin/bash” /etc/passwd | grep -v “root” | cut -f 1 -d “:”
结果:
bigdata01
cut 虽然可以进行切分,但是却存在一些问题,就比如你的要的字符之间不是一个分隔符,而是多个分隔符,那么使用cut是不行的。但是我们可以通过使用awk做到这个要求
就比如下面的df-h 如果想要取出Avail ,他们每个字段之间是不确定个数的空格,使用cut是不行的

使用df -h | cut -f 2 -d " " 最后没有结果

3、awk
awk切割的默认是 空白字符,包括空格、\t等
在awk命令的输出中支持print和printf命令,print和c、java不同,print默认是会进行换行的,但是linux中是不支持print的。printf是不会进行换行,是标准格式输出命令
awk操作:
awk ‘条件1{动作1}条件2{动作2}{动作3}…’ 文件名
条件:
一般使用关系表达式作为条件
如x > 10 判断变量x 是是否大于 10
动作
1、格式化输出
2、流程控制语句
默认是切割空白符,取出每行的第2、4列,注意如果在使用\n 、\t时 要用双引号引着
awk ‘{printf $2 “\t” $ 4 “\n”}’ student.txt

使用awk 命令 把 df -h中的每一行进行切分(类似java中\s,切割空白字符),再取出Avail对应的字段的列,但是把Avail去掉
df -h | awk ‘{print $4}’ | grep -v “Avail”

制定分割符:
取出 /etc/passwd文件中的普通用户
grep “/bin/bash” /etc/passwd | awk ‘BEGIN{FS=":"}{printf $1 “\n”}’
或者 -F 可以指定分隔符
grep “/bin/bash” /etc/passwd | awk -F “[:]” ‘{printf $1 “\n”}’
或者
grep “/bin/bash” /etc/passwd | awk -F : ‘{printf $1 “\n”}’
想要使用多个分割符时,以逗号 冒号 空格 为分割符
echo “ab dd,dd:KK” | awk -F “[,: ]” ‘{printf $1 “\t” $2 “\t” $3 “\t” $4 “\n”}’
注意: 在使用非空格作为分割符时,如果使用
grep “/bin/bash” /etc/passwd | awk ‘{FS=":"}{printf $1 “\n”}’
结果如下,并不会对数据的第一行进行切分,所以要在动作前加上BEGIN,或者使用-F进行切分
root: x:0:0:root:/root:/bin/bash
bigdata

多个分割符

‘条件 {动作}’
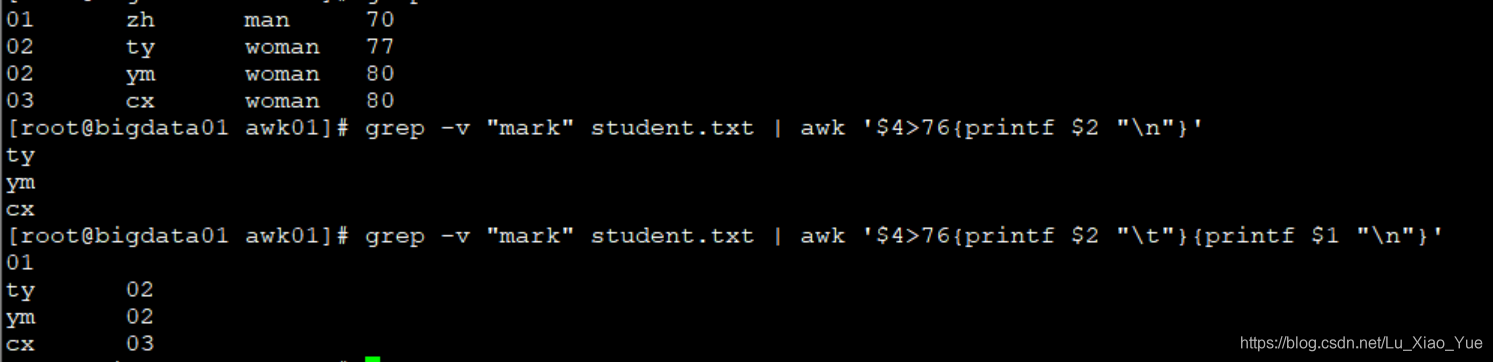
grep -v “mark” student.txt | awk ‘$4>76{printf $2 “\n”}’
取出成绩大于76 的同学的名字

对于 ‘条件1{动作1}{动作2}’ 这种类型的
是一个条件对应一个动作,当动作前面没有条件时,那么这个动作可以不满足任何条件
就拿下面的例子来说,先选出成绩大于76的学生的姓名,这是一组条件和动作,接着又打印学号, 可以看到成绩大于76的学生一共有3个,打印出来的姓名有3个,但是学号有4个,所以一个动作只需要满足它所对应的条件即可
BEGIN END
加不加BEGIN的差别:
不加BEGIN
awk ‘{printf “aaaa” “\t”}{printf $1 “\t” $2 “\n”}’ student.txt
加BEGIN
awk ‘BEGIN{printf “aaaa” “\t”}{printf $1 “\t” $2 “\n”}’ student.txt
加END
加上BEGIN时 第一个动作只会打印一遍,不加BEGIN,第一个动作和第二个动作执行的次数一样,加END是把第一动作放到最后执行且只执行一遍



4、sed
sed是一种几乎包括在所有UNIX平台(包括Linux)的轻级流量编辑器,sed主要是用来将数据进行选区、替换、删除、新增的命令
sed[选项] ‘[动作]’ 文件名
选项:
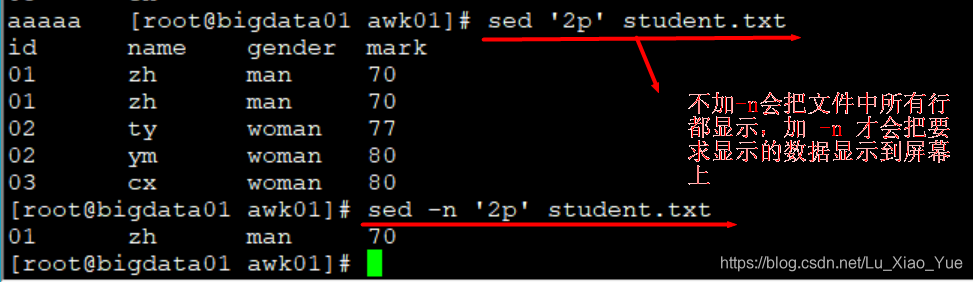
-n : 一般sed命令会把所有的数据输出到屏幕,如果加入此选择则只会把进过处理的sed命令的行输出到屏幕。
-e : 允许对输入数据应用多条sed命令编辑
-i : 用sed的修改结果直接修改读取数据的文件,而不是在屏幕上输出
-a : 追加,在当前行后添加一行或多行数据
-i : 插入,在当前行前插入一行或多行。
-d : 删除删除指定行
-p : 打印,输出指定的行
-s : 字符串替换,用一个字符串替换另一个字符串,格式为"行范围s/旧字符串/新字符串/g"
查看第二行的数据
sed -n ‘2p’ student.txt
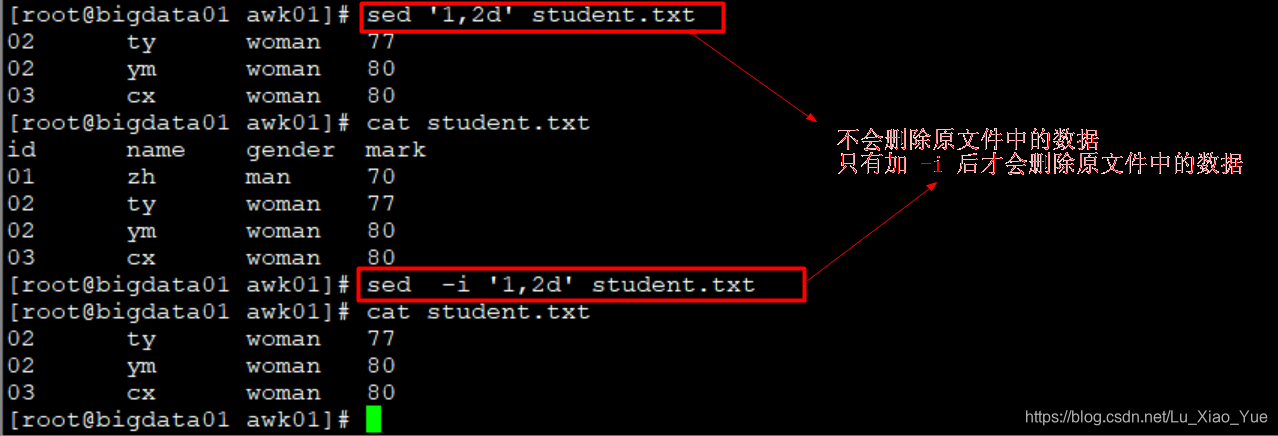
删除指定行的数据
sed ‘1,2d’ student.txt 不会删除原数据,把结果打印到屏幕上
sed -i ‘1,2d’ student.txt 会删除原数据
增加数据
指定行后增加数据
sed ‘2a 01\tty\twoman\t76’ student.txt
sed -i ‘2a 01\tty\twoman\t76’ student.txt
指定行后增加数据
sed ‘2i 06\tnn\twoman\t76’ student.txt
sed -i ‘2i 06\tnn\twoman\t76’ student.txt

在指定行前加数据

替换
替换指定行(如果想修改原文件 在sed 后加 -i即可)
sed -i ‘2c 06\tkk\twoman\t77’ student.txt 替换第二行的内容
替换指定字符串
sed ‘3s/03/04/g’ student.txt
替换多个字符串 使用 -e
sed -e ‘2s/06/01/g;3s/01/03/g’ student.txt
2s 和 3s 分别表示要替换的行,后面跟的都是老字符串 新字符串
替换多个字符串并修改原文件 使用-ne
sed -ie ‘1s/02/01/g;2s/01/02/g’ student.txt


