
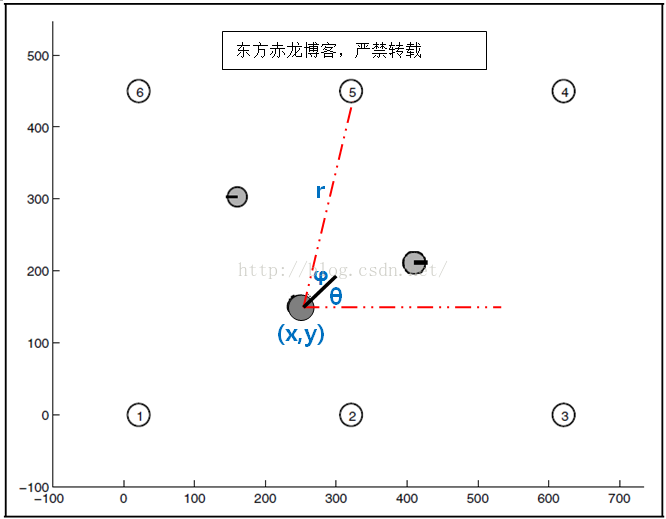

看到这里会问了,不是还有AR标签帮助测量定位吗?根据标签位置,距离和角度也可以算出坐标啊! 没错,但是还是那个老问题,这个测量结果也是有误差的,误差大小完全取决于传感器。
- 移动的速度和起点坐标 根据公式1算出来的坐标 x = (x,y) 有很大误差噪音
- AR标签测量的值 z=(r, φ) 有很大误差噪音
===========接下来开始讲概率矩阵数学===========
- 状态 x = 坐标 (x,y,θ)
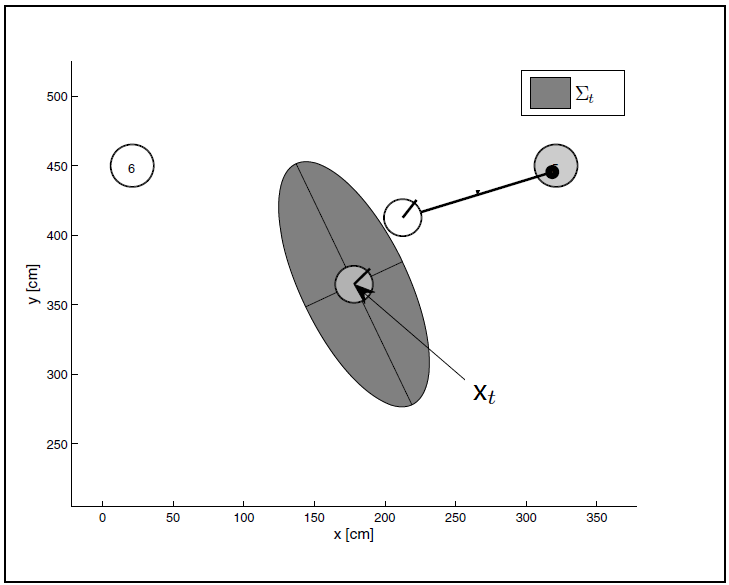
- 状态噪音Σ = 状态 x 的精确度
- 最优状态 μ 每个时刻卡尔曼滤波估算的最优坐标
- 状态转移控制量 u = 线速度和角速度(v, ω)
- 状态转移噪音 R 因为移动所增加的噪音
- 观测量 z = AR标签测量值 (r, φ)
- 观测量噪音 Q = AR标签传感器的噪音
- xt =At xt-1 +Bt ut 根据t-1的坐标和移动速度估计出在t时刻的坐标,也就是上面的公式一。这里At =1,Bt 就是时间间隔 Δt
- z =C x 状态量x 到观测量z 的映射关系。这里就是根据下面的三角函数计算出来的, C代表了状态映射矩阵。
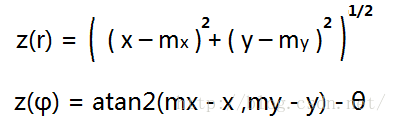
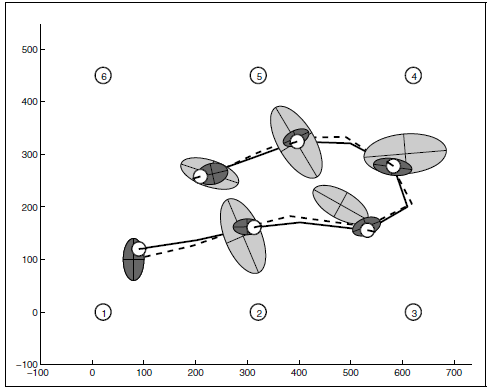
- t-1 到 t时刻的状态预测,得到前验概率
- 根据观察量对预测状态进行修正,得到后验概率,也就是最优值
 。为了便于记忆,我们一般化它为公式一:
。为了便于记忆,我们一般化它为公式一:
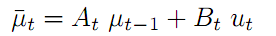
 。为了便于记忆,我们一般化它为公式二:
。为了便于记忆,我们一般化它为公式二:
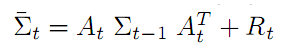
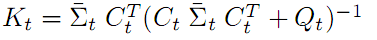
- 观测量 z 到状态量 x 的的变换矩阵,就是说 x = K z . 相当于2.1节提到的状态转移方程 z = C x 中 C 的逆矩阵。本文例子就相当于从地标AR标签的距离和角度反推出机器人的位置。
- 对观测量的可信度百分比。观测量可信度越高,也就是测量噪音Q相对于与状态预测噪音
2.3.3 后验值修正
既然预测不准确,那就用测量后验值去修正它。先修正状态值x,就是公式四:
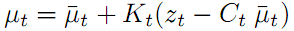 正确,那它观测到AR标签时的距离和角度对应的值就是
正确,那它观测到AR标签时的距离和角度对应的值就是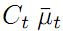 ,可视为预测观测值。而
,可视为预测观测值。而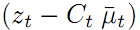 则代表预测观测值与实际观测值的差距。乘上卡尔曼增益K,就得到了修正量。修正量加上预测值就是修正值或最优值。假设为0,就是说预测AR标签位置和观测到的AR标签位置完全一样,那公式四返回就是预测状态坐标值,和直观常识吻合的非常完美。假设的值比较大,就是说预测AR标签位置和观测到的AR标签位置差别很大,那根据卡尔曼增益K中的百分比信息的小或大,公式四就返回值靠近预测值或靠近测量值多一些,和实际物理意义吻合的还是非常完美。
则代表预测观测值与实际观测值的差距。乘上卡尔曼增益K,就得到了修正量。修正量加上预测值就是修正值或最优值。假设为0,就是说预测AR标签位置和观测到的AR标签位置完全一样,那公式四返回就是预测状态坐标值,和直观常识吻合的非常完美。假设的值比较大,就是说预测AR标签位置和观测到的AR标签位置差别很大,那根据卡尔曼增益K中的百分比信息的小或大,公式四就返回值靠近预测值或靠近测量值多一些,和实际物理意义吻合的还是非常完美。
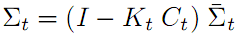
修正后的噪音Σt 其值要比预测噪音
和感测噪音Q都要小。这样直观上也容易理解,滤波后的状态噪音最小,所以最优。
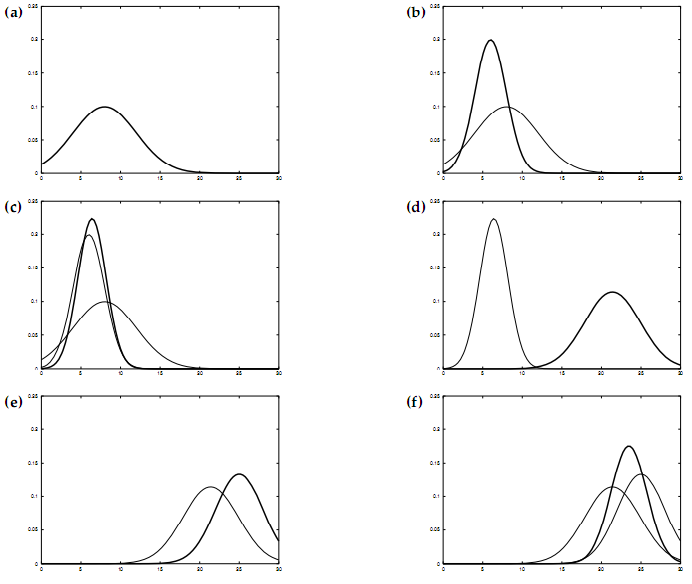
3 科尔曼滤波的条件和扩展卡尔曼滤波
- xt = At xt-1 + Bt ut 根据t-1的坐标和移动速度估计出在t时刻的坐标,也就是上面的公式一。这里At =1,Bt 就是时间间隔 Δt
- z = C x 状态量x 到观测量z 的映射关系。这里就是根据下面的三角函数计算出来的, C代表了状态映射矩阵。
参考知行合一
这部分主要是通过对第一部分中提到的匀加速小车模型进行位移预测。
先来看看状态方程能建立准确的时候,状态方程见第一部分分割线以后内容,小车做匀加速运动的位移的预测仿真如下。
clc
clear all
close all
% 初始化参数
delta_t=0.1; %采样时间
t=0:delta_t:5;
N = length(t); % 序列的长度
sz = [2,N]; % 信号需开辟的内存空间大小 2行*N列 2:为状态向量的维数n
g=10; %加速度值
x=1/2*g*t.^2; %实际真实位置
z = x + sqrt(10).*randn(1,N); % 测量时加入测量白噪声
Q =[0 0;0 9e-1]; %假设建立的模型 噪声方差叠加在速度上 大小为n*n方阵 n=状态向量的维数
R = 10; % 位置测量方差估计,可以改变它来看不同效果 m*m m=z(i)的维数
A=[1 delta_t;0 1]; % n*n
B=[1/2*delta_t^2;delta_t];
H=[1,0]; % m*n
n=size(Q); %n为一个1*2的向量 Q为方阵
m=size(R);
% 分配空间
xhat=zeros(sz); % x的后验估计
P=zeros(n); % 后验方差估计 n*n
xhatminus=zeros(sz); % x的先验估计
Pminus=zeros(n); % n*n
K=zeros(n(1),m(1)); % Kalman增益 n*m
I=eye(n);
% 估计的初始值都为默认的0,即P=[0 0;0 0],xhat=0
for k = 9:N %假设车子已经运动9个delta_T了,我们才开始估计
% 时间更新过程
xhatminus(:,k) = A*xhat(:,k-1)+B*g;
Pminus= A*P*A'+Q;
% 测量更新过程
K = Pminus*H'*inv( H*Pminus*H'+R );
xhat(:,k) = xhatminus(:,k)+K*(z(k)-H*xhatminus(:,k));
P = (I-K*H)*Pminus;
end
figure
plot(t,z);
hold on
plot(t,xhat(1,:),'r-')
plot(t,x(1,:),'g-');
legend('含有噪声的测量', '后验估计', '真值');
xlabel('Iteration');
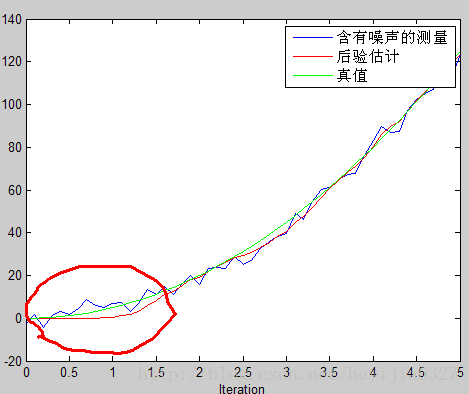
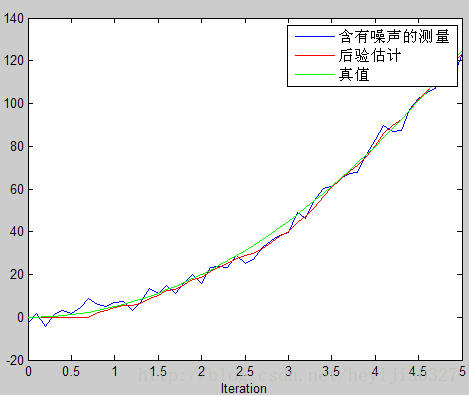
绿线为真实值,蓝色的为噪声很大的测量值,红线为估计值。由此可以看出卡尔曼滤波确实相当犀利,提供了一个顺滑的最优的估计。并请注意代码中,特地使得估计是从第9个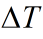
但这里请注意图像中画红圈部分,由于一开始你预测值为0,而实际上不是(它已经运动9个时间间隔了),所以估计出的效果不好。在这里回忆前面讨论过的K值大小和估计的关系,既然预测不准,那么一开始我就先相信测量呗。这就涉及估计值误差协方差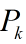
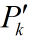
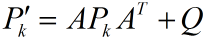
它又和估计误差协方差矩阵
修改初值P=[2 0;0 2],估计图像如下,可以看到初始估计明显改进了。(两幅图中,测量值相同,只改变了P)。这幅图中红色水平线那部分是前9个时间段,你还没开始雷达追踪,所以是水平的为0。
好了,到第二个问题,当状态方程建立不正确的又会怎样呢?实际应用中很多时候我们不能建立正确的状态方程。
我们假设建立的状态方程如下:
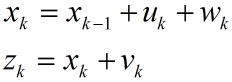
转换矩阵A,B,H都等于1.这个模型明显是不正确的。
注意这个时候的系统噪声,就不单单只是系统内部产生的,还包括你建立状态方程的不正确性。你建立的越不正确,根据你模型进行的预测就不正确,从这个角度来说,相当于你的噪声增大了。所以这个时候系统噪声W的方差应该增大。理解这一点,对改进实际估计效果有好处。接下来通过对比不同的W方差值设定给出对比,贴出这部分仿真如下。
clc
clear
close all
% 初始化参数
delta_t=0.1;
t=0:delta_t:5;
g=10;%加速度值
n_iter = length(t); % 序列的长度
sz = [n_iter, 1]; % 信号需开辟的内存空间大小
x=1/2*g*t.^2;
x=x';
z = x + sqrt(10).*randn(sz); % 测量时加入测量白噪声
Q = 0.9; % 过程激励噪声方差
%注意Q值得改变 待会增大到2,看看效果。对比看效果时,修改代码不要改变z的值
R = 10; % 测量方差估计,可以改变它来看不同效果
% 分配空间
xhat=zeros(sz); % x的后验估计
P=zeros(sz); % 后验方差估计
xhatminus=zeros(sz); % x的先验估计
Pminus=zeros(sz); % 先验方差估计
K=zeros(sz); % Kalman增益
% 估计的初始值
xhat(1) = 0.0;
P = 1.0;
for k = 2:n_iter %
% 时间更新过程
xhatminus(k) = xhat(k-1);
Pminus(k) = P(k-1)+Q;
% 测量更新过程
K(k) = Pminus(k)/( Pminus(k)+R );
xhat(k) = xhatminus(k)+K(k)*(z(k)-xhatminus(k));
P(k) = (1-K(k))*Pminus(k);
end
figure
plot(t,z);
hold on
plot(t,xhat,'r-')
plot(t,x,'g-');
legend('含有噪声的测量', '后验估计', '真值');
xlabel('Iteration');
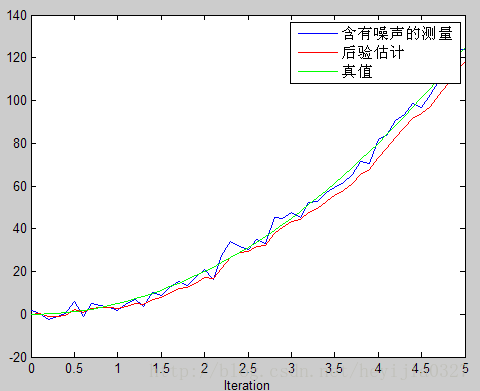
两个图中测量值是一样的,只是第二图中将系统噪声方差Q增大到2。对比可以看出,特别是图像后半段,图(b)比图(a)效果更接近真实值。
至此,从推导到应用接近尾声了,但我在这里还有一个问题就是,你随便给的x的预测初值,模型建立也不正确,kalman filter 竟然依然这么犀利,那么他收敛性怎么证明呢?写这文章的时候,笔者没有看详细的数学证明,但是由前面说到的kalman filter和数值分析里递推求解方程组时用的Gauss-Seidel 迭代法,两者真的很相近,于是我直观的认为卡尔曼的收敛性和Gauss-Seidel 一样。Gauss-Seidel迭代法里权重的选取能使得递推收敛真实值,因此卡尔曼滤波里增益K的每次计算就是卡尔曼收敛的重要保证。