【原创】Liu_LongPo 转载请注明出处
【CSDN】http://blog.csdn.net/llp1992
卡尔曼滤波器是一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。而且由于观测包含系统的噪声和干扰的影响,所以最优估计也可看做是滤波过程。
卡尔曼滤波器的核心内容就是5条公式,计算简单快速,适合用于少量数据的预测和估计。
下面我们用一个例子来说明一下卡尔曼算法的应用。
假设我们想在有一辆小车,在 t 时刻其速度为 Vt ,位置坐标为 Pt,ut 表示 t 时刻的加速度,那么我们可以用Xt表示 t 时刻的状态,如下:
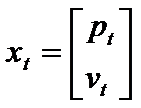
则我们可以得到,由t-1 时刻到 t 时刻,位置以及速度的转换如下:
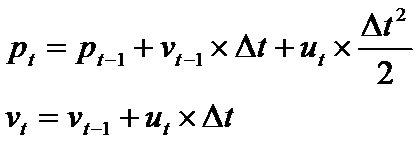
用向量表示上述转换过程,如下:
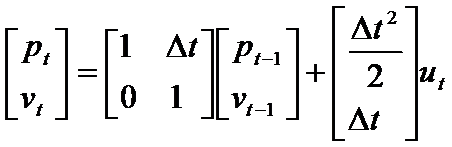
如下图:
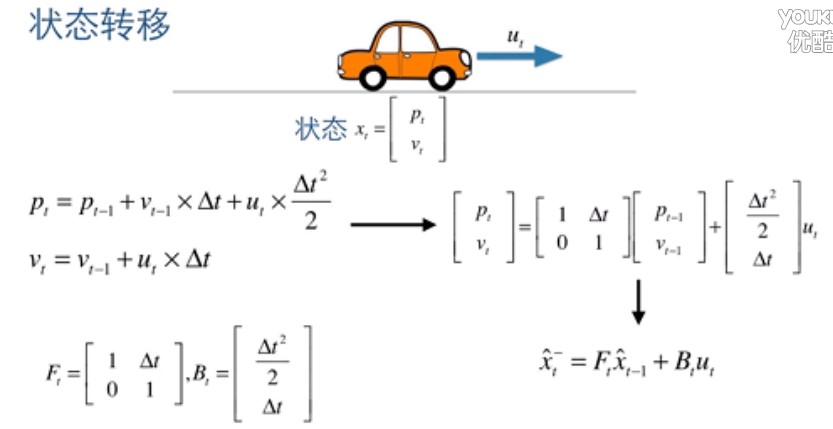
那么我们可以得到如下的状态转移公式:
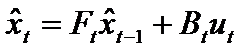 (1)
(1)
其中矩阵 F 为状态转移矩阵,表示如何从上一状态来推测当前时刻的状态,B 为控制矩阵,表示控制量u如何作用于当前矩阵,上面的公式 x 有顶帽子,表示只是估计值,并不是最优的。
有了状态转移公式就可以用来推测当前的状态,但是所有的推测都是包含噪声的,噪声越大,不确定越大,协方差矩阵用来表示这次推测带来的不确定性
协方差矩阵
假设我们有一个一维的数据,这个数据每次测量都不同,我们假设服从高斯分布,那么我们可以用均值和方差来表示该数据集,我们将该一维数据集投影到坐标轴上,如下图:
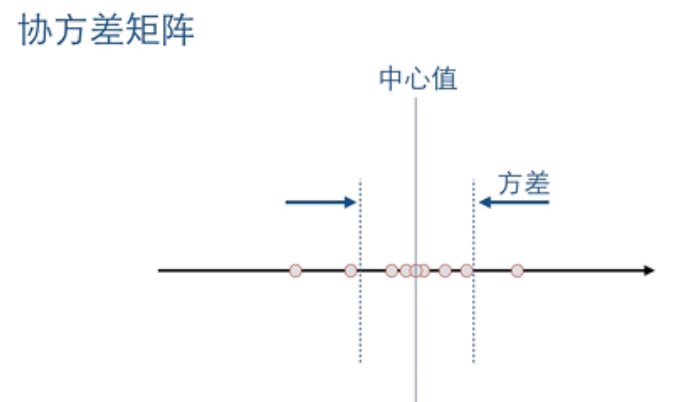
可以看到,服从高斯分布的一维数据大部分分布在均值附近。
现在我们来看看服从高斯分布的二维数据投影到坐标轴的情况,如下图:
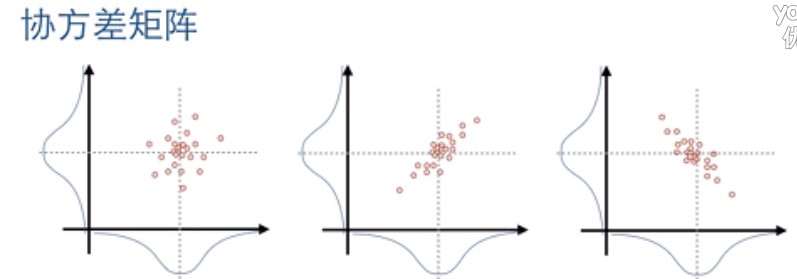
二维数据比一维数据稍微复杂一点,投影后有3种情况,分别是:
左图:两个维的数据互不相关;
中图:两个维的数据正相关,也就是 y 随着 x 的增大而增大(假设两个维分别为 x 和 y)
右图:两个维的数据负相关,也就是 y 随着 x 的增大而减小。
那怎么来表示两个维的数据的相关性呢?答案就是协方差矩阵。
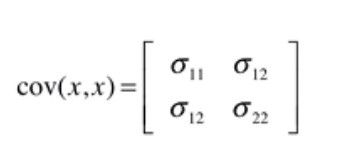
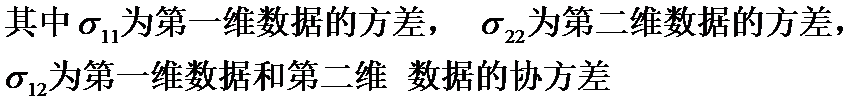
状态协方差矩阵传递
在公式(1)之中,我们已经得到了状态的转移公式,但是由上面可知,二维数据的协方差矩阵对于描述数据的特征是很重要的,那么我们应该如何更新或者说传递我们的二维数据的协方差矩阵呢?假如我们用 P 来表示状态协方差,即
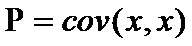
那么加入状态转换矩阵 F ,得到
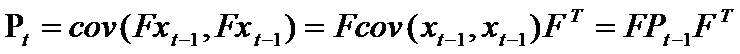 (2)
(2)
也即:

因此我们便得到了协方差的转换公式。
现在我们得到了两个公式,运用这两个公式能够对现在状态进行预测。按照我们的正常思路来理解,预测结果不一定会对嘛,肯定有误差。而且在我们大多数回归算法或者是拟合算法中,一般思路都是先预测,然后看看这个预测结果跟实际结果的误差有多大,再根据这个误差来调整预测函数的参数,不断迭代调整参数直到预测误差小于一定的阈值。
卡尔曼算法的迭代思想也类似,不过这里根据误差调整的是状态 X 。
在这里,我们的实际数据就是 Z, 如下图:
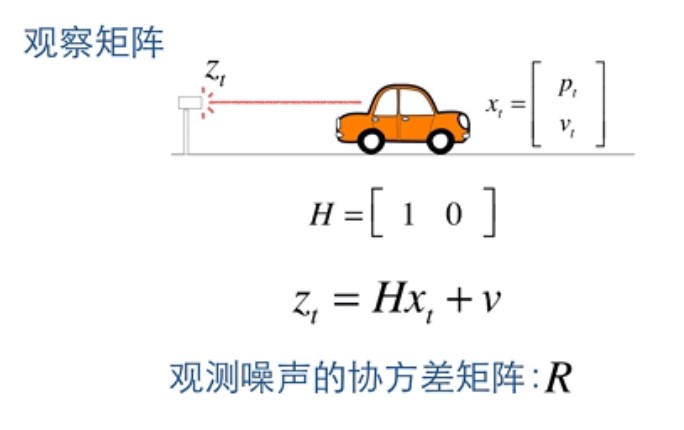
其中,矩阵 H 为测量系统的参数,即观察矩阵,v 为观测噪声, 其协方差矩阵为R
那么我们的状态更新公式如下:
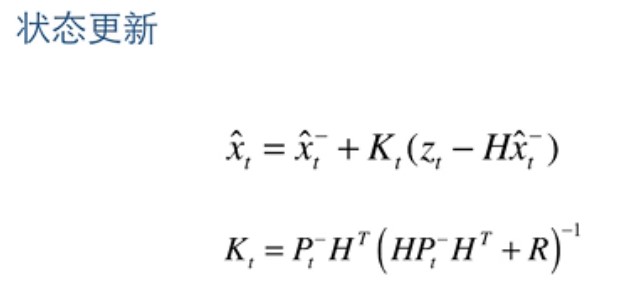
其中K 为卡尔曼系数, Z-Hx 则为残差,也就是我们说的,预测值与实际值的误差。
K的作用:
1.K 权衡预测协方差P和观察协方差矩阵R那个更加重要,相信预测,残差的权重小,相信观察,残差权重大,由 K 的表达是可以退出这个结论
2,将残差的表现形式从观察域转换到状态域(残差与一个标量,通过K 转换为向量),由 状态 X 的更新公式可得到该结论。
至此,我们已经得到了 t 状态下的最优估计值 Xt。但为了能让我们的迭代算法持续下去,我们还必须更新状态协方差的值。
状态协方差的更新

以上就是卡尔曼滤波算法的思想,只有简单的 5 条公式,总结如下:
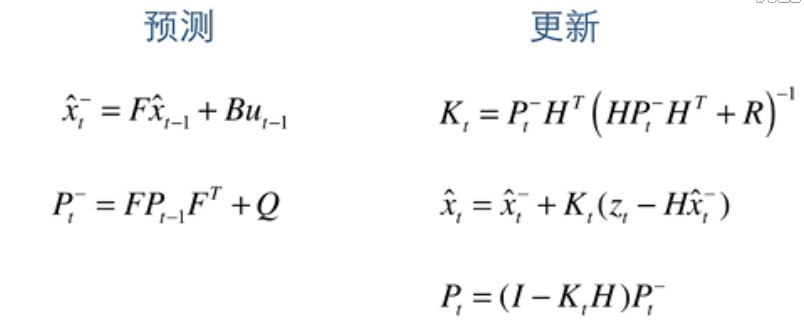
Matlab 实现
function kalmanFiltering
%%
clc
close all
%%
%
% Description : kalmanFiltering
% Author : Liulongpo
% Time:2015-4-29 16:42:34
%
%%
Z=(1:2:200); %观测值 汽车的位置 也就是我们要修改的量
noise=randn(1,100); %方差为1的高斯噪声
Z=Z+noise;
X=[0 ; 0 ]; %初始状态
P=[1 0;0 1]; %状态协方差矩阵
F=[1 1;0 1]; %状态转移矩阵
Q=[0.0001,0;0 , 0.0001]; %状态转移协方差矩阵
H=[1,0]; %观测矩阵
R=1; %观测噪声协方差矩阵
figure;
hold on;
for i = 1:100
%基于上一状态预测当前状态
X_ = F*X;
% 更新协方差 Q系统过程的协方差 这两个公式是对系统的预测
P_ = F*P*F'+Q;
% 计算卡尔曼增益
K = P_*H'/(H*P_*H'+R);
% 得到当前状态的最优化估算值 增益乘以残差
X = X_+K*(Z(i)-H*X_);
%更新K状态的协方差
P = (eye(2)-K*H)*P_;
scatter(X(1), X(2),4); %画点,横轴表示位置,纵轴表示速度
end
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
Matlab效果
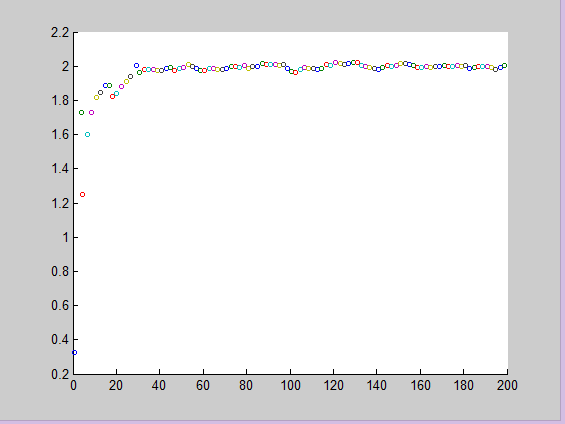
其中 x 轴为位置,y轴为速度。
在代码中,我们设定x的变化是 1:2:200,则速度就是2,可以由上图看到,值经过几次迭代,速度就基本上在 2 附近摆动,摆动的原因是我们加入了噪声。
接下来来看一个实际例子。
我们的数据为 data = [149.360 , 150.06, 151.44, 152.81,154.19 ,157.72];
这是运用光流法从视频中获取角点的实际x轴坐标,总共有6个数据,也就是代表了一个点的连续6帧的x轴坐标。接下来这个例子,我们将实现用5帧的数据进行训练,然后预测出第6帧的x轴坐标。
在上一个matlab例子中,我们的训练数据比较多,因此我们的初始状态设置为[0,0],也就是位置为0,速度为0,在训练数据比较多的情况下,初始化数据为0并没有关系,因为我们在上面的效果图中可以看到,算法的经过短暂的迭代就能够发挥作用。
但在这里,我们的训练数据只有5帧,所以为了加快训练,我们将位置状态初始化为第一帧的位置,速度初始化为第二帧与第一帧之差。
测试代码:
KF.m
function [predData,dataX] = KF(dataZ)
%%
%
% Description : kalmanFiltering
% Author : Liulongpo
% Time:2015-4-29 16:42:34
%
%%
Z = dataZ';
len = length(Z);
%Z=(1:2:200); %观测值 汽车的位置 也就是我们要修改的量
noise=randn(1,len); %方差为1的高斯噪声
dataX = zeros(2,len);
Z=Z+noise;
X=[Z(1) ; Z(2)-Z(1) ]; %初始状态 分别为 位置 和速度
P=[1 0;0 1]; %状态协方差矩阵
F=[1 1;0 1]; %状态转移矩阵
Q=[0.0001,0;0 , 0.0001]; %状态转移协方差矩阵
H=[1,0]; %观测矩阵
R=1; %观测噪声协方差矩阵
%figure;
%hold on;
for i = 1:len
%基于上一状态预测当前状态
% 2x1 2x1
X_ = F*X;
% 更新协方差 Q系统过程的协方差 这两个公式是对系统的预测
% 2x1 2x1 1x2 2x2
P_ = F*P*F'+Q;
% 计算卡尔曼增益
K = P_*H'/(H*P_*H'+R);
% 得到当前状态的最优化估算值 增益乘以残差
X = X_+K*(Z(i)-H*X_);
%更新K状态的协方差
P = (eye(2)-K*H)*P_;
dataX(:,i) = [X(1);X(2)];
%scatter(X(1), X(2),4); %画点,横轴表示位置,纵轴表示速度
end
predData = F*X;
end- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
testKF.m
function testKF
%%
clc
close all
%%
%data = load('D:\\a.txt');
%data = [149.360 , 150.06, 151.44, 152.81,154.19,157.72,157.47,159.33,153.66];
data = [149.360 , 150.06, 151.44, 152.81,154.19 ,157.72];
[predData , DataX] = KF(data');
error = DataX(1,:) - data;
i = 1:length(data);
figure
subplot 311
scatter(i,data,3),title('原始数据')
subplot 312
scatter(i,DataX(1,:),3),title('预测数据')
subplot 313
scatter(i,error,3),title('预测误差')
predData(1)
%{
scatter(i,error,3);
figure
scatter(i,data,3)
figure
scatter(i,predData(1,:),3)
%}
end- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
测试效果:
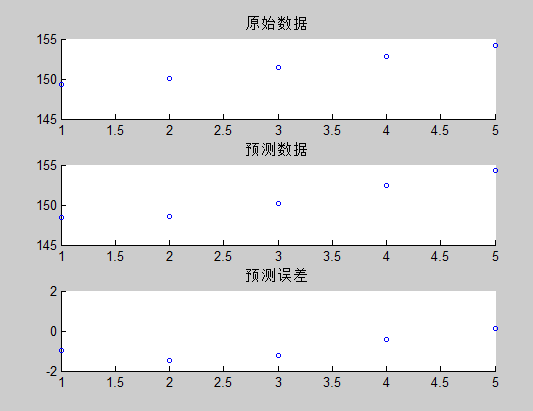
预测结果为: 155.7493 ,跟实际结果 157.72 仅有1.9 的误差,可以看到,卡尔曼滤波器算法对于少量数据的预测效果还是挺不错的。当然,预测位置的同时,我们也得到了预测速度。