# Copyright (c)2018, 东北大学软件学院学生
# All rightsreserved
# 文件名称:justForTest.py
# 作 者:孔云
#问题描述:网络爬虫解决乱码
# coding:utf-8
import requests
url="http://www.baidu.com"
r=requests.get(url)
print("使用编码:",r.encoding)
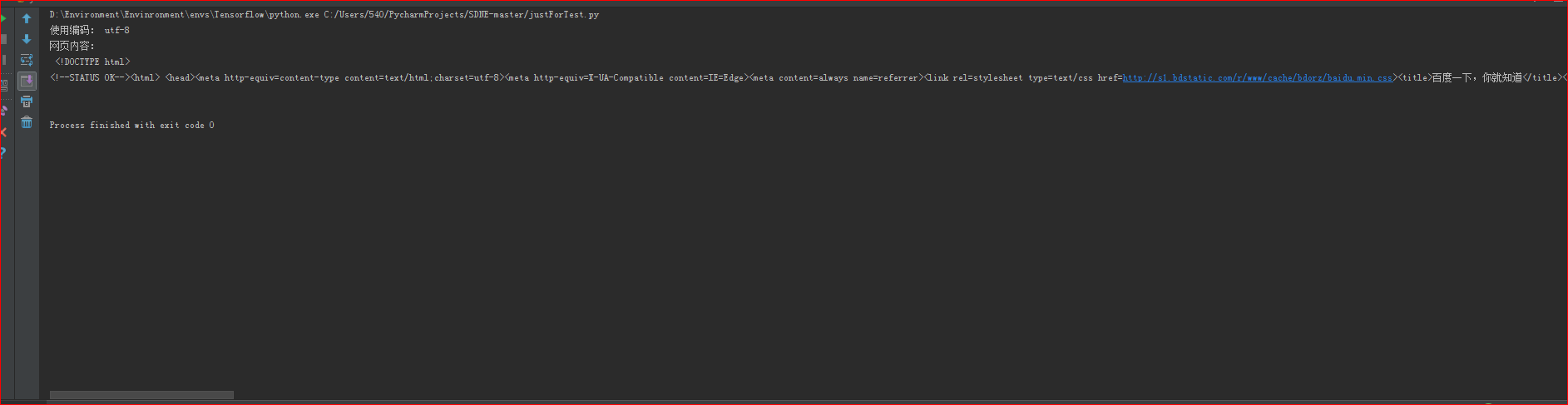
print("网页内容:\n",r.text)运行结果如下:

由结果图知,上面代码爬取的网页内容存在乱码,如蓝色框所示,解决办法如下:
import requests
def getHtmlText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()#如果状态不是200,引发HttpError异常
r.encoding=r.apparent_encoding#备选编码作为使用编码
print("使用编码:",r.encoding)
return r.text
except:
return "产生异常"
if __name__=="__main__":
url="http://www.baidu.com"
print("网页内容:\n",getHtmlText(url))运行结果如下:
由上述运行结果知,乱码得到解决。