一 综述
驱动浏览器,解决js渲染问题
二 使用细节
1 声明浏览器对象
webdriver.Chrome()
2 访问页面
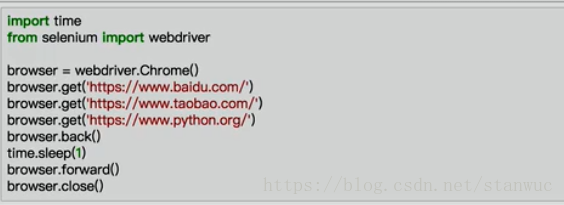
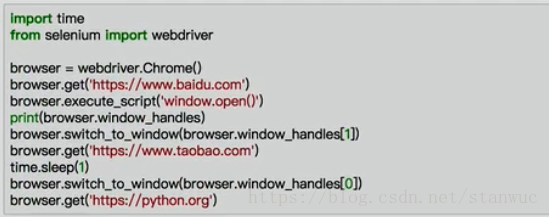
brower.get(' ')
3 查找元素
单个元素

多个元素

4 元素交互操作

5 交互动作
动作附加到动作练中串行执行

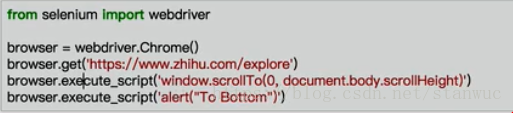
6 执行JS
扫描二维码关注公众号,回复:
3268895 查看本文章

7 获取元素信息
- 获取属性:input.get_attribute('class')
- 获取文本:input.text
- 获取ID、位置、标签名和大小等信息:input.id / size / tag_name / location
8 Frame处理
frame搭建的框架,每一个frame里都是一个page,需要进行切换

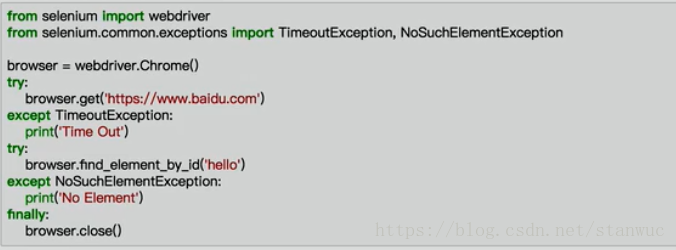
9 等待:确保元素加载完成
隐式等待:找到元素不等待,没找到继续等待,超出时间报异常

显式等待