前言
本人目前是大二的小萌新,这是初次接触网络爬虫,若是本文有解释不当之处,还望多多海涵。
我们诚邀各地有志之士加入我们的代码学习群交流:871352155(无论你会C/C++还是Java,Python还是PHP......有兴趣我们都欢迎你的加入,不过还请各位认真填写加群信息。群内目前多为大学生,打广告的先生女士就请不要步足了。我们希望有远见卓识的前辈能为即将步入社会的初犊提出建议指引方向。)
什么是网络爬虫?
网络爬虫是一种很厉害的工具,通俗点说就是一种照相机,把别人的正常公开出来的美丽‘’风景“(数据)记录下来,引为己用。不过切记在爬取前要看一下所爬取页面的robots协议勿要随心所欲(查看robots协议的方法,就是在你想要爬取的页面后面加上robots.txt,Eg:https://www.baidu.com/robots.txt),毕竟别人不想给你,你也不能张手就要,是吧。
网络爬虫的基本流程
基本上就是一种模拟浏览器打开页面,再获取页面中我们所需要的那部分内容的形式。众所周知,我们查看网页的元素的控制台是按键盘的F12,这样我们就可以看到本页面的HTML,CSS,JS信息,而我们的爬虫就是向浏览器地址发送请求然后返回这些页面基本信息进行自己设定好的过滤(毕竟你也不可能什么都要,那多费内存)后并保存的过程。
爬虫工具
最最基本的恐怕就是我们的Request库了,比较大众化,通俗易懂。这里我为萌新们介绍下北京理工大学的嵩天老师的课程https://www.bilibili.com/video/av9784617?from=search&seid=12990039280936736739老师授课简单清晰明了。不过呢,今天我要介绍的并不是request库的方法,而是另外一种很强大的爬虫库叫做Selenium,这个库给我的感觉就像是就真的像是一个人在操作浏览器然后复制粘贴信息。
实例
1.安装方法
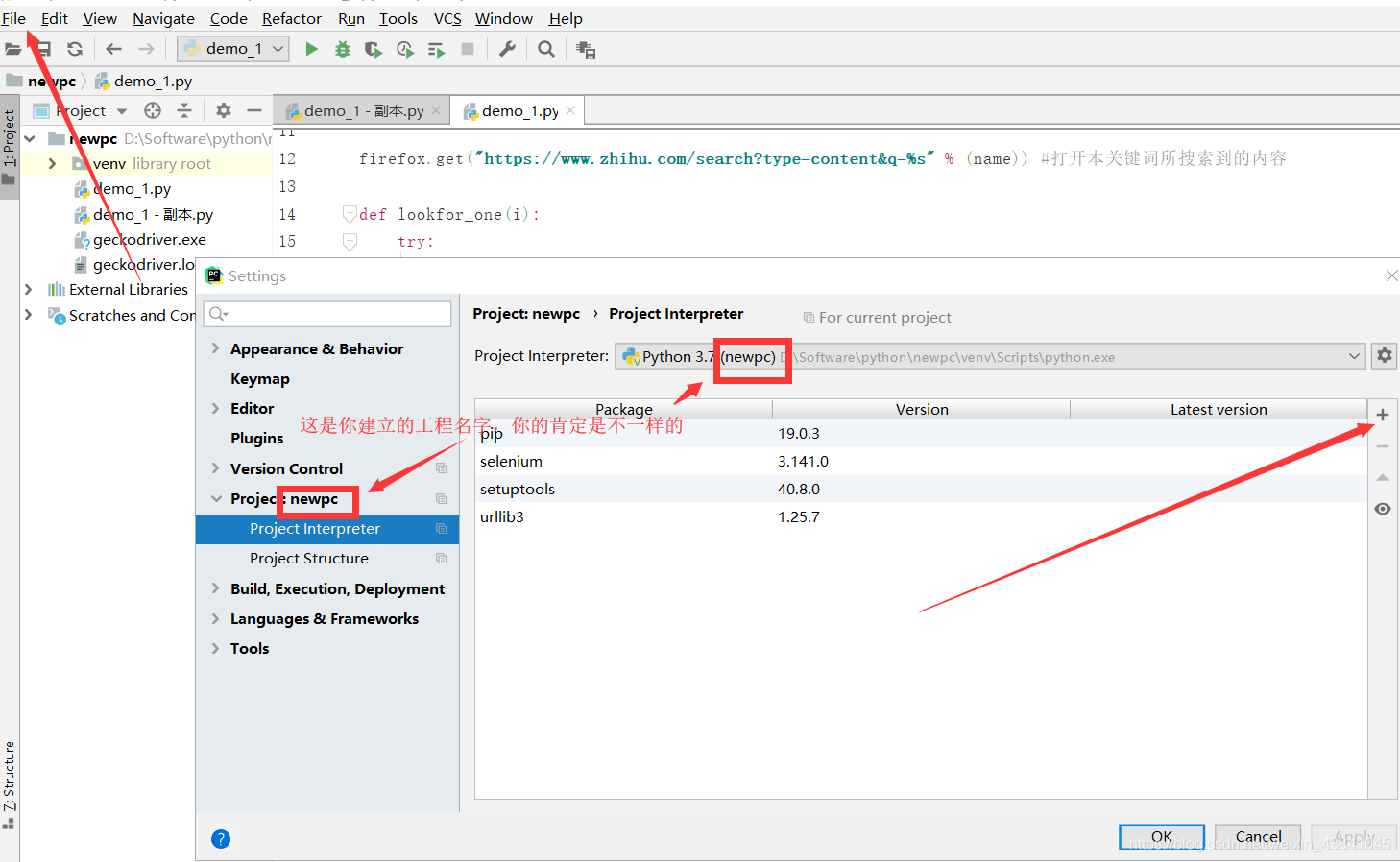
打开cmd后,输入pip install selenium。如果你是用pycharm,左上角的File找到setting,然后在Project:XXX里面有个Project Interpreter,你会看见右边有一堆是你已经安装好的库,然后点击更靠右的+写上selenium点击install package
2.驱动器安装
这个selenium是需要一种工具,他才可以模拟人的操作,我这里用的是火狐的驱动。
1.chromedriver驱动的下载地址如下:http://chromedriver.storage.googleapis.com/index.html
2.Firefox的驱动geckodriver 下载地址:https://github.com/mozilla/geckodriver/releases/
3.IE的驱动IEdriver 下载地址:http://www.nuget.org/packages/Selenium.WebDriver.IEDriver/
3.实例开始
3.1
介绍:我的这个实例功能概况下就是,通过输入一些关键词然后到知乎网上爬取关于这个关键词的多数文章中的评论信息。
3.2.1
既然你下载了这个包,总不可能不引用吧,之所以引用了time这个包,后面会解释。不过还有个前提,我这个是基于了火狐浏览器,想改成其他浏览器的话......换成其他浏览器的驱动就行。
from lib2to3.pgen2 import driver
from selenium import webdriver
from selenium.webdriver.firefox.firefox_profile import FirefoxProfile
from selenium.webdriver.common.keys import Keys
import time3.2.2
前期工作,三个输入(1.你想要的的关键词文章。2.你想要多少关于这个关键词下的文章。3.文章下的评论最少多少字,太少字的评论选择pass掉)
firefox = webdriver.Firefox() #打开浏览器
name=str(input('输入搜索知乎的关键词:')) #'政务app使用意向'
times=int(input('输入你要查询的条数:'))
need_lenth=int(input('输入你想爬取到的评论最少字数:')) #限制评论长度
firefox.get("https://www.zhihu.com/search?type=content&q=%s" % (name)) #打开本关键词所搜索到的内容
3.2.3
本函数是为了找到关键词下的数量文章后记录下他的相应链接。
find_element_by_css_selector是通过定位他css中的属性来定位相应的标签
find_element_by_tag_name是通过直接定位到标签名字来定位,不过因为一个页面很多时候标签会重复用,除非你已经成功定位到一个小的循环板块再用这个定位法会比较好。否则我建议还是先用上面那种定位法,毕竟标签即使相同,他们的属性或多或少有点不一样吧。
firefox.implicitly_wait()是一种让程序自己休息的函数,因为是模拟人嘛,人总有反应时间,不休息下就去找东西,会不会不太正常。
get_attribute()是确定好标签后,从里面取出链接的函数。
对了,解释下为什么要用try而不是while和for,因为知乎嘛,或多或少存在一些广告朋友,他们自带的CSS属性是与众不同的,用while和for的话很容易就Error了。用try的话,不合适的直接Pass掉,也不会取广告的信息。
def lookfor_one(i):
try:
div = firefox.find_element_by_css_selector('[data-za-detail-view-path-index="%d"]' % i)
#firefox.execute_script("arguments[0].scrollIntoView();", div)
firefox.implicitly_wait(3)
h2 = div.find_element_by_tag_name('h2')
a = h2.find_element_by_tag_name('a')
span = a.find_element_by_tag_name('span').text
print(span)#每条信息的标题
href = a.get_attribute('href') # 定位每条信息的链接地址
time.sleep(3)
return href
except:
pass3.2.4
page_down是我自行写的一种类人操作,因为知乎不像其他什么网站是翻页的,他是下拉才会出新结果。但是你一直往后拉呀,有可能他就卡住不拉了,而我们人的正常操作就是一边拉一边网上提一下,然后不要忘了拉了之后还要等一会哈,万一你家网卡或者CPU罢工了,那就Error了(发生这种事大家也不想的嘛ToT)
def page_down():#根据查询条数页面下滑,每10条数据下滑1次底部
for j in range(int(times/10)):
firefox.execute_script('window.scrollTo(0,document.body.scrollHeight-100)') # 滑到距离底部100px
firefox.implicitly_wait(3)
firefox.execute_script('window.scrollTo(0,document.body.scrollHeight-500)') #防止一下滑到底部也不更新
firefox.execute_script('window.scrollTo(0,document.body.scrollHeight)') # 类人操作,上下多滑几次
time.sleep(3)3.2.5
这个函数是把所有取得到的地址存储到一个数组中,(当然你要存字典或者元组我也拦不住你QwQ)
def get_all_href():#获取你想要的所有文章链接地址
all_href=[]
page_down()#获取之前先拉几次
for i in range(0,times):
all_href.append(lookfor_one(i))#将所有链接地址存放在数组中
print(all_href)
return all_href3.2.6
Come on到我们的主函数先生登场了,之前我不是说了存储到数组中有的时候他会有广告嘛,存进来后自然就是None,当然我们在循环函数中这个None自然就要请他退群咯。然后我们进入正确的链接后,要事先尝试打开下“更多问题“,不然很多评论会被埋没在不得伯乐的忧郁中,而爬取不到哟。Of course,有很多的文章他们可能因为某些原因而无人问津从而导致没有评论(像我这种博客写得不尽人意一样),所以我们也用try,把没有评论的兄弟给PASS掉。来到有评论的文章里面判断下他说的话长度是否低于你的期望(当然你修改下也是可以改成限制在多少字数内),改成(new_span)<need_lenth的话好理解吧,就是超过多少字数的不要,说白了就是你知道的太多了,得拖出去PASS了。最后后,切记要firefox.quit()关闭浏览器,你一直开着做什么呢?和流量过不去干什么?
for i in get_all_href():#主函数,获取评论
if i!=None:
firefox.get(i)#打开链接地址
try:#尝试打开”更多问题“,若没有则执行下一步
click_question=firefox.find_element_by_css_selector('[class="QuestionMainAction ViewAll-QuestionMainAction"]')
click_question.click()
except:
pass
try:#尝试抓取评论信息,若无评论则执行下一步
first_div=firefox.find_element_by_css_selector('[class="Question-mainColumn"]')
j = 0
while True:
try:#循环所有评论
new = first_div.find_element_by_css_selector('[data-za-index="%d"]' % j)
new_span = new.find_element_by_css_selector('[class="RichText ztext CopyrightRichText-richText"]').text#定位评论文本
if len(new_span)>need_lenth:#比较文本长度是否在自己需要范围内
print(new_span)
else:
pass
j += 1
except:
break
except:
pass
time.sleep(3)
else:
pass#如果地址为None,可能是广告或者电子书之类
firefox.quit()#关闭浏览器后序
喜欢用HTML做成礼物或者贺卡等的朋友详情请看我的B站合集https://www.bilibili.com/video/av84894004不定时更新
