引言
网络爬虫应用十分广泛,本篇针对金融领域,目的为根据用户输入的基金代码来爬取该基金自成立以来的每一天的基金净值以及涨跌幅等相关信息,用于后续数据分析或程序开发。
爬虫 与 Selenium
网络爬虫
爬虫技术在科学研究、Web安全、产品研发、舆情监控等领域可以做很多事情。
在数据挖掘、机器学习、图像处理等科学研究领域,如果没有数据,则可以通过爬虫从网上抓取;
在Web安全方面,使用爬虫可以对网站是至存在某一漏洞进行批量验证、利用。
在产品研发方面,可以采集各个商城物品价格,为用户提供市场最低价;
在奥情监控方面,可以抓取、分析新浪微博的数据,从而识别出基用户是否为水军
Selenium
对于访问 Web 时直接响应的数据(就是response内容可见),我们使用 urllib,requests 或 Scrapy 框架爬取。
对于一般的 JavaScript 动态渲染的页面信息(Ajax 加载),我们可以通过分析 Ajax 请求来抓取信息。
即使通过 Ajax 获取数据,但还有会部分加密参数,后期经过JavaScript 计算生成的内容,导致我们难以直接找到规律,如淘宝页面。
为了解决这些问题,我们可以直接使食拟浏览器运行的方式来实现信息获取。
在Pyhon中有许多模拟浏览器运行库,如:senum、Splash、PyW8、Ghost等。
一句话,你平时用鼠标是怎么打开浏览器,拖动鼠标和下拉框对话框,是怎么输入你想要搜索数据的,我们 selenium 就怎么完全给你复现一遍,90% 一模一样。
延伸
担心会错过最后的信息,所以将 后记&延伸 放到引言的下面,基金的净值走势其实一点开基金网查看就可以了,疫情之下的涨跌幅会比较大,平时最多也就大概在正负 2% 的区间,投资界有句话说得好:“ 投资 80% 看行为,20% 看技术,风险在人声鼎沸处,机会再无人问津时。” 只有持有得久,坐得住,能够坚持定期不定额的投资,摒弃喜涨厌跌的心理,才能看到赚钱的曙光。
我赚钱的秘诀之一在于能够做到不频繁的查看基金股票的涨跌,长期持有基金(1-1.5年)或股票(3-5年)。
------ 沃伦·巴菲特
亮点
而现实生活中,以招商中证白酒指数分级这只鸡金为例,早期做爬虫的时候获取了自其成立以来的历年来每一天的基金净值,已经分析得出该基金的 25% 分位点的基金净值约为 0.89,疫情之下大盘涨跌不定,2月3号刚开始一天就下跌了快 9%,而后报复性反弹。一个佛系投资朋友希望短期抄底,但又不想每天都上线查看,所以向我提出了以下业务需求。
业务需求
- 基金爬虫,我输入完整基金代码&希望生成的 csv 文件名,你给我把他历年来每一天的净值和涨跌幅扒下来
- 程序还需要自动实现数据分析功能,求出我希望的基金净值的分位点。
- 配合 Java/Python 等程序开发,如果该基金的净值一旦低于 25% ,30%,35% 分位点时,能在我电脑桌面实现提醒功能,提醒我近两三天可以上线查看要不要买入了。
一句话,实现基金买入和关注的桌面提醒程序提醒
因为利是钱全部没收,欢迎符号打赏巨款 10 万给我短期抄底。
这里只展示爬虫部分
用到的知识点
- Python 爬虫基础
- 库:csv,selenium
- 正则表达式,xpath 原理
实现效果 & 大体概览
程序概览(将各个函数用箭头收起来)
最多也不过 120 行
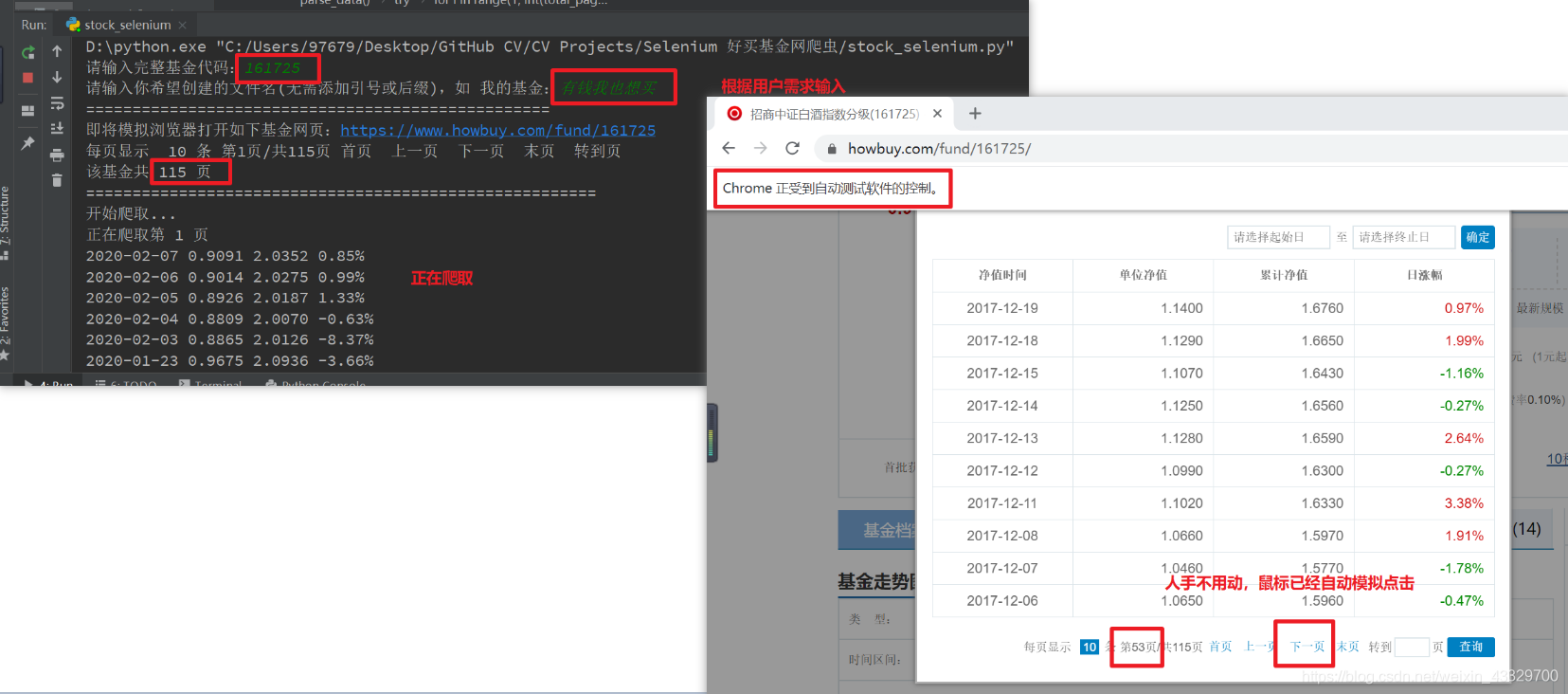
正在运行中的程序和自动打开并实现跟人手操作一模一样的浏览器。
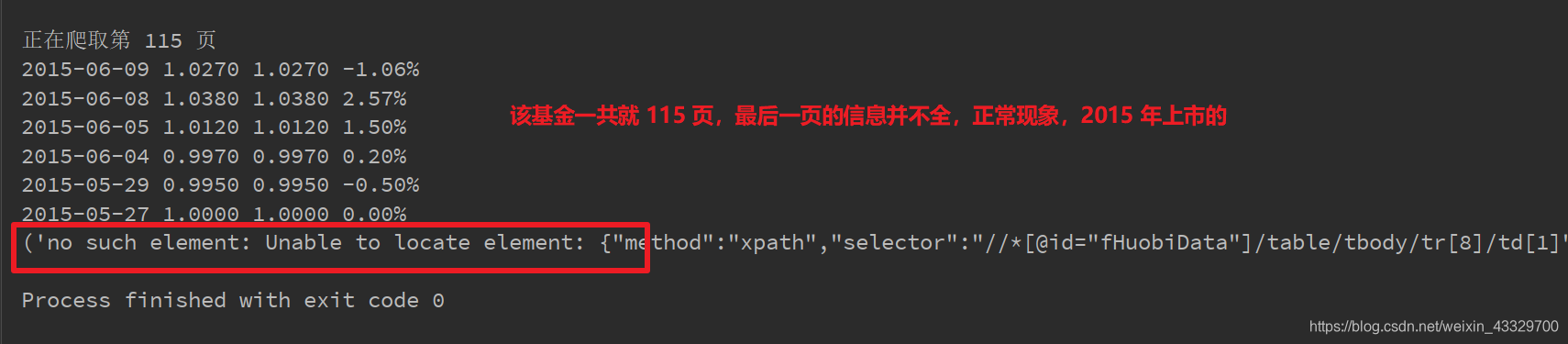
程序运行结束时
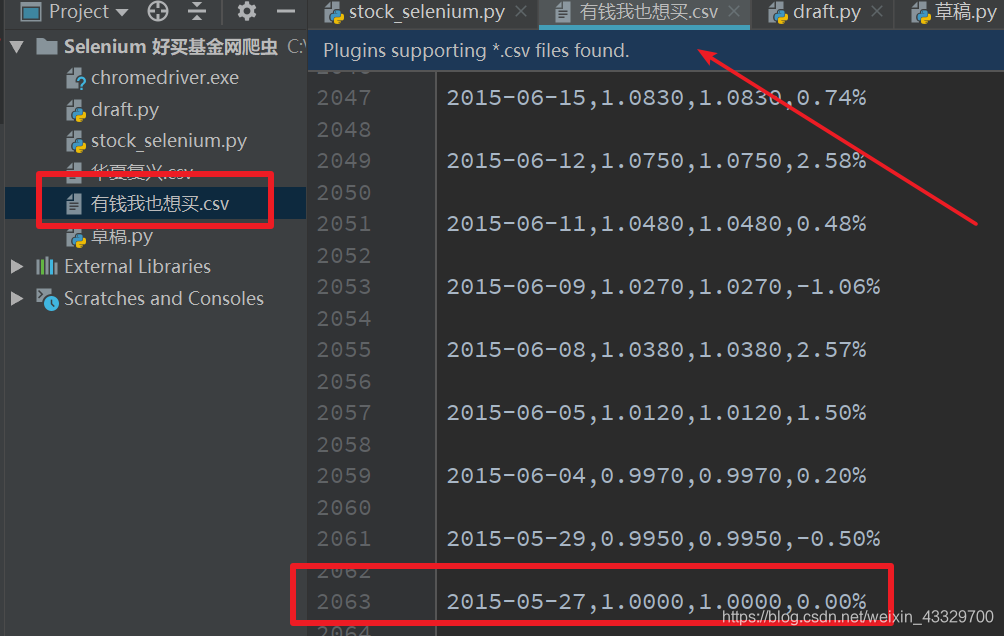
自动在当前目录生成了我希望生成的带有满满数据的文件。
代码阅读 & 函数拆解
createFile & writeFile 函数
parse_data 函数 part1:基础配置
这里有一个节省很多时间的亮点!

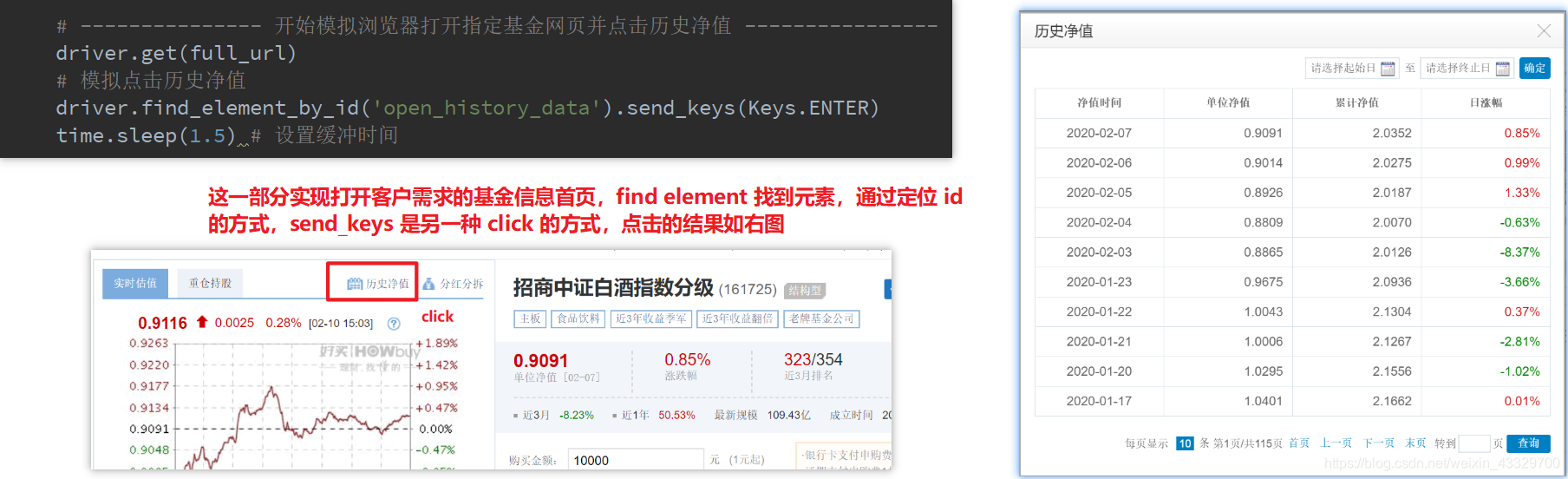
这一步省掉了模拟打开好买基金网首页,找到搜索框,输入数据,然后找到搜索二字,点击,点击以后还要选择需要的基金。真的太麻烦。
parse_data part2:开始模拟浏览器打开指定基金网页并点击历史净值
完整代码
需要自己配好在浏览器驱动 chromedriver,注释已经贼详细了。
from selenium import webdriver # 浏览器驱动
from selenium.webdriver.common.keys import Keys # 模拟浏览器点击时需要用
import time,csv
fieldnames = ['日期', '单位净值', '累计净值', '日涨幅']
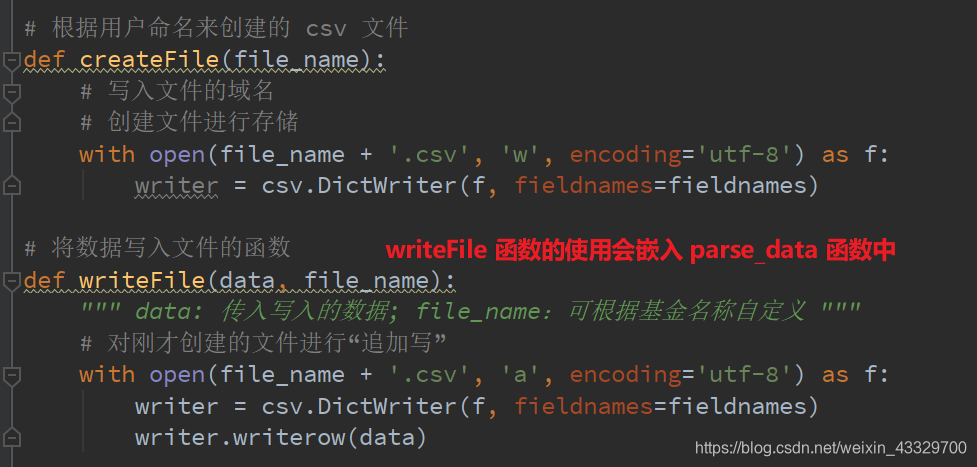
# 根据用户命名来创建的 csv 文件
def createFile(file_name):
# 写入文件的域名
# 创建文件进行存储
with open(file_name + '.csv', 'w', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
# 将数据写入文件的函数
def writeFile(data, file_name):
""" data: 传入写入的数据; file_name:可根据基金名称自定义 """
# 对刚才创建的文件进行“追加写”
with open(file_name + '.csv', 'a', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writerow(data)
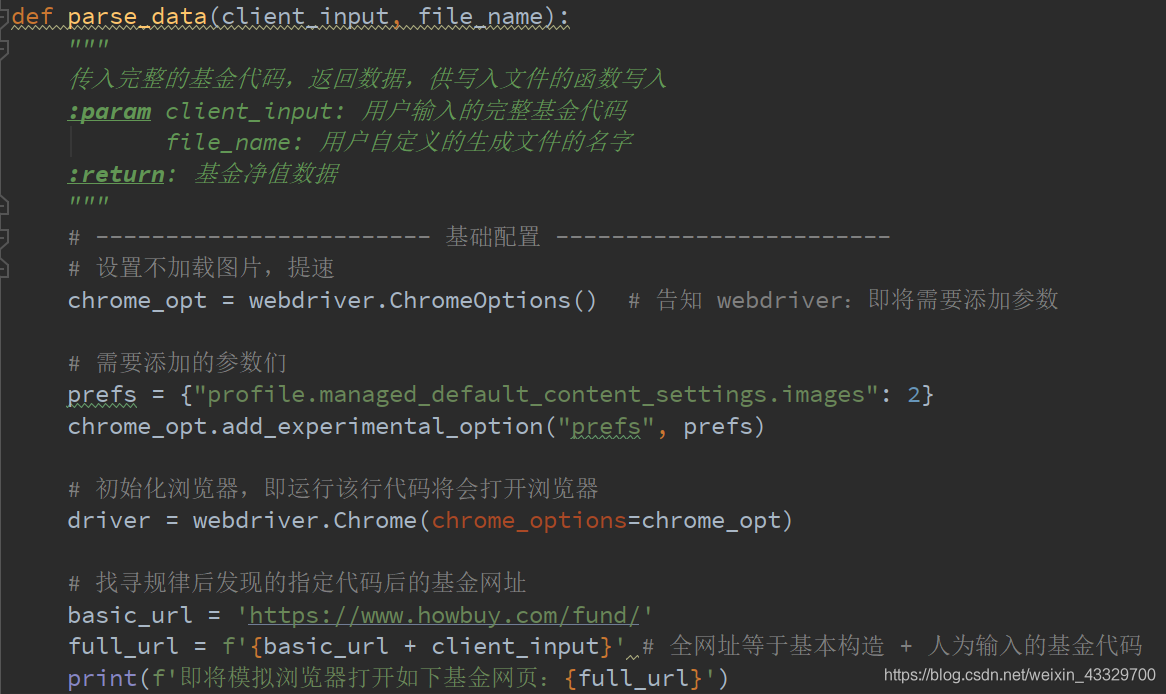
def parse_data(client_input, file_name):
"""
传入完整的基金代码,返回数据,供写入文件的函数写入
:param client_input: 用户输入的完整基金代码
file_name: 用户自定义的生成文件的名字
:return: 基金净值数据
"""
# ------------------------ 基础配置 ------------------------
# 设置不加载图片,提速
chrome_opt = webdriver.ChromeOptions() # 告知 webdriver:即将需要添加参数
# 需要添加的参数们
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_opt.add_experimental_option("prefs", prefs)
# 初始化浏览器,即运行该行代码将会打开浏览器
driver = webdriver.Chrome(chrome_options=chrome_opt)
# 找寻规律后发现的指定代码后的基金网址
basic_url = 'https://www.howbuy.com/fund/'
full_url = f'{basic_url + client_input}' # 全网址等于基本构造 + 人为输入的基金代码
print(f'即将模拟浏览器打开如下基金网页:{full_url}')
# --------------- 开始模拟浏览器打开指定基金网页并点击历史净值 ----------------
driver.get(full_url)
# 模拟点击历史净值
driver.find_element_by_id('open_history_data').send_keys(Keys.ENTER)
time.sleep(1.5) # 设置缓冲时间
# ------------------------- 激动人心的模拟爬取 ------------------------
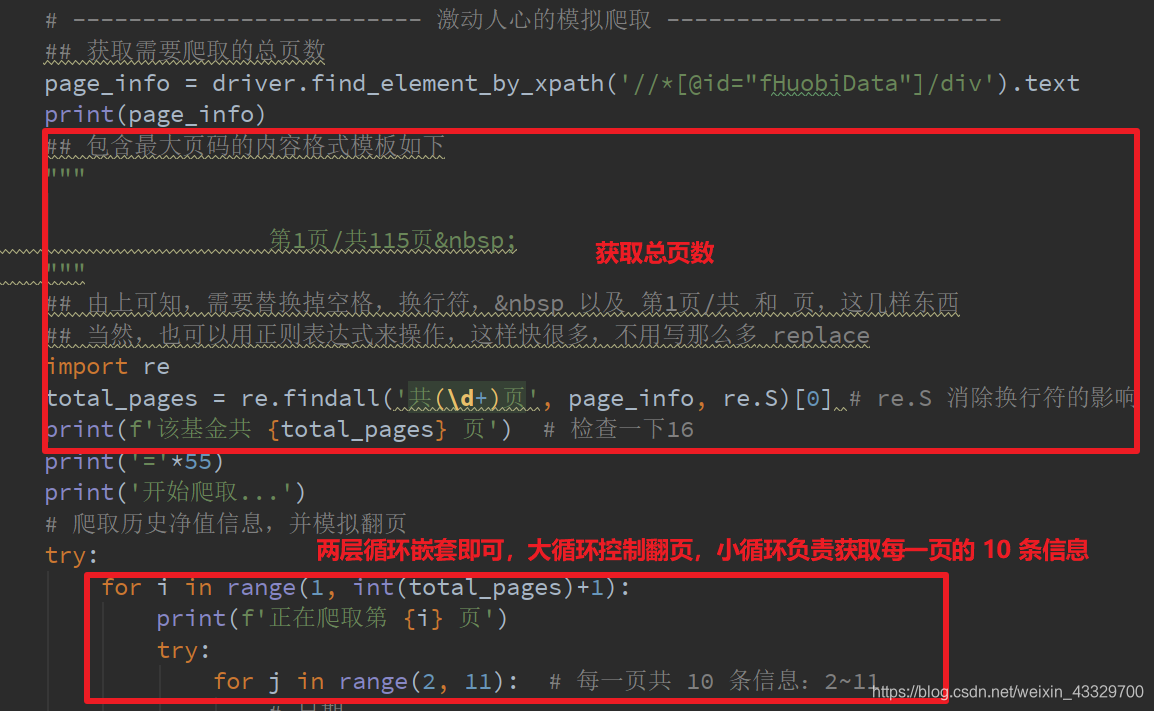
## 获取需要爬取的总页数
page_info = driver.find_element_by_xpath('//*[@id="fHuobiData"]/div').text
print(page_info)
## 包含最大页码的内容格式模板如下
"""
第1页/共115页
"""
## 由上可知,需要替换掉空格,换行符,  以及 第1页/共 和 页,这几样东西
## 当然,也可以用正则表达式来操作,这样快很多,不用写那么多 replace
import re
total_pages = re.findall('共(\d+)页', page_info, re.S)[0] # re.S 消除换行符的影响
print(f'该基金共 {total_pages} 页') # 检查一下16
print('='*55)
print('开始爬取...')
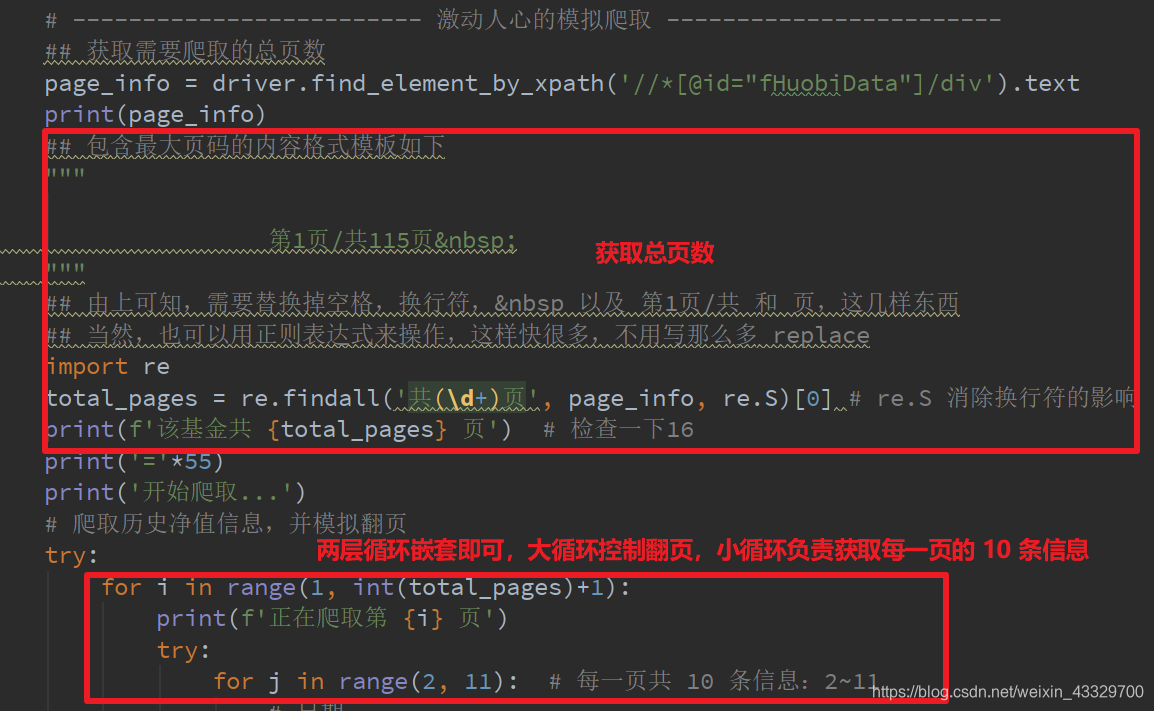
# 爬取历史净值信息,并模拟翻页
try:
for i in range(1, int(total_pages)+1):
print(f'正在爬取第 {i} 页')
try:
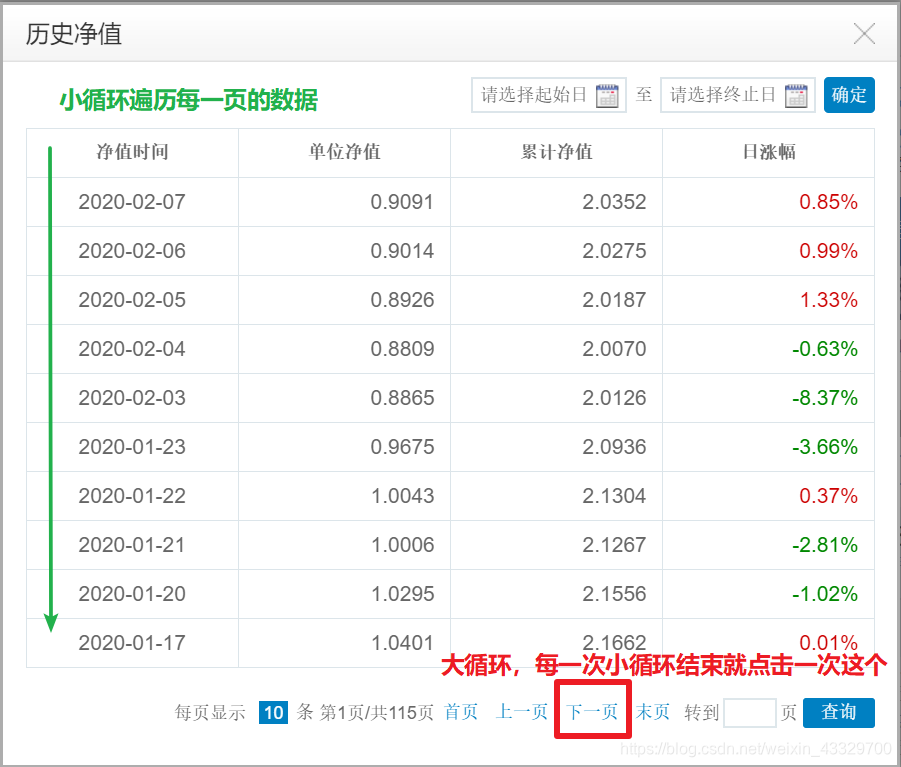
for j in range(2, 11): # 每一页共 10 条信息:2~11
# 日期
date_xpath = '//*[@id="fHuobiData"]/table/tbody/tr[{}]/td[1]'
date = driver.find_element_by_xpath(date_xpath.format(j)).text
# 单位净值
net_value_xpath = '//*[@id="fHuobiData"]/table/tbody/tr[{}]/td[2]'
net_value = driver.find_element_by_xpath(net_value_xpath.format(j)).text
# 累计净值
total_net_value_xpath = '//*[@id="fHuobiData"]/table/tbody/tr[{}]/td[3]'
total_net_value = driver.find_element_by_xpath(total_net_value_xpath.format(j)).text
# 日涨幅
daily_increase_xpath = '//*[@id="fHuobiData"]/table/tbody/tr[{}]/td[4]/span'
daily_increase = driver.find_element_by_xpath(daily_increase_xpath.format(j)).text
print(date, net_value, total_net_value, daily_increase)
## ---------------- 将爬取到的数据写入 csv 文件 ---------------------
data = {
'日期': date,
'单位净值': net_value,
'累计净值': total_net_value,
'日涨幅': daily_increase
}
# 写入数据
writeFile(data, file_name=file_name)
# 模拟点击下一页: 在大循环处模拟
driver.find_element_by_xpath('//*[@id="fHuobiData"]/div/a[3]').send_keys(Keys.ENTER)
time.sleep(1.5)
except Exception as e:
print(e.args)
continue
print('\n')
except Exception as e:
print(e.args) # 为分享方便,只是设置最简单的捕获异常,日后再说
# 调度爬虫的总函数
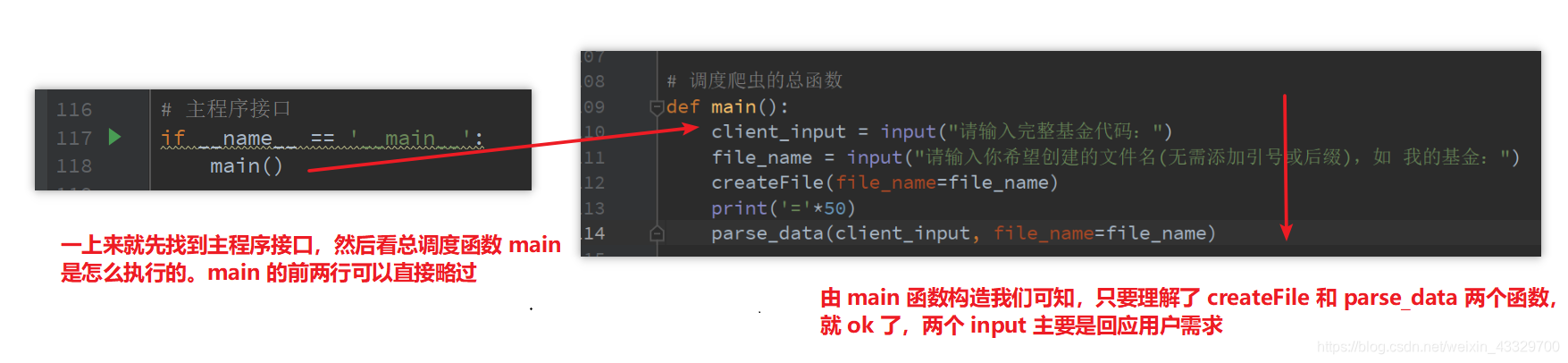
def main():
client_input = input("请输入完整基金代码:")
file_name = input("请输入你希望创建的文件名(无需添加引号或后缀),如 我的基金:")
createFile(file_name=file_name)
print('='*50)
parse_data(client_input, file_name=file_name)
# 主程序接口
if __name__ == '__main__':
main()
后记
理性投资,加油
