一.全连接层:
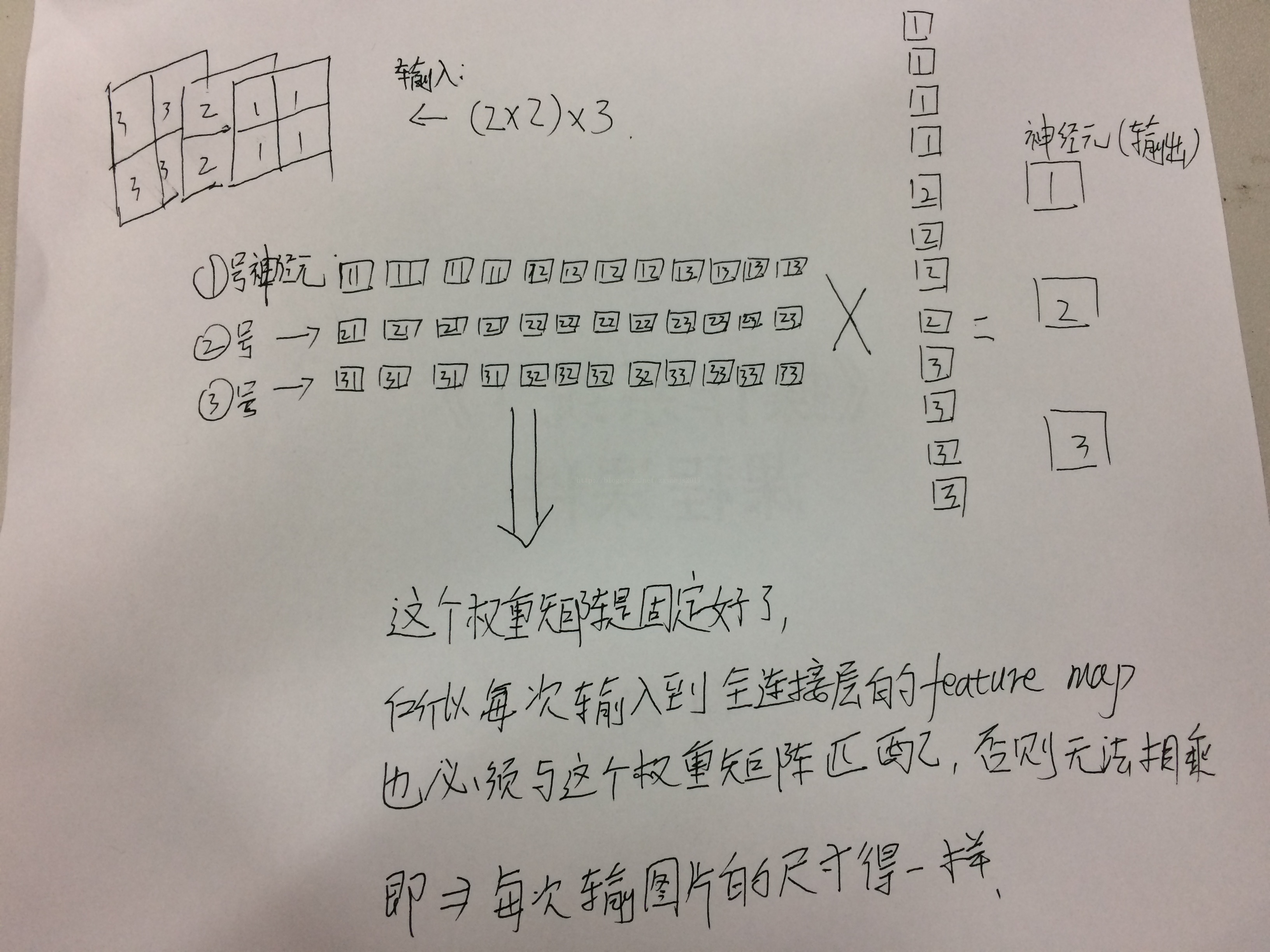
全连接层需要把输入拉成一个列项向量,如下图所示:
比如你的输入的feature map是2X2,那么就需要把这个feature map 拉成4X1的列向量,如果你的feature map 的channels是3,也就是你的输入是3X2X2,也就是相当于有了12个像素点,你就需要把feature map 拉成12X1的列向量,这时候,再乘一个权重,这个权重要把12个像素点都包含进去,所以这个权重的矩阵形式应该是1X12,所以经过一个全连接层后的输出就是1X12X12X1=1X1,这时候需要看你的需要多少个1X1的神经元了,如果是3个的话,那么输出就是3X(1X12X12X1)=3X(1X1).这个3在权重矩阵中代表3行,即每一行与输入相乘,得到一个输出:
二.卷积层:转载:https://www.cnblogs.com/zf-blog/p/6075286.html
卷积层就相当于一个卷积核,对于传送过来的feature map进行局部窗口滑动,无论你输入的feature map多大(不能小于卷积核的大小),都不会对卷积造成影响:
卷积神经网络(CNN)由输入层、卷积层、激活函数、池化层、全连接层组成,即INPUT-CONV-RELU-POOL-FC
(1)卷积层:用它来进行特征提取,如下:
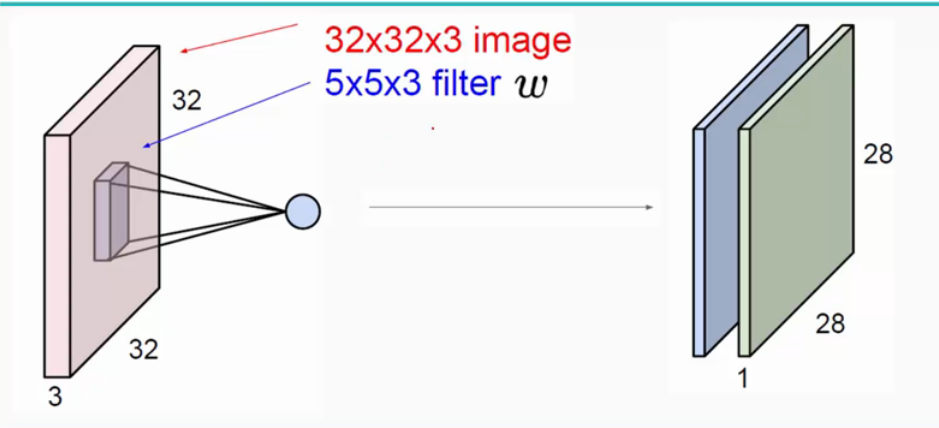
输入图像是32*32*3,3是它的深度(即R、G、B),卷积层是一个5*5*3的filter(感受野),这里注意:感受野的深度必须和输入图像的深度相同。通过一个filter与输入图像的卷积可以得到一个28*28*1的特征图,上图是用了两个filter得到了两个特征图;
三.卷积层与全连接层的区别:
从上面可以看出,全连接层的权重矩阵是固定的,即每一次feature map的输入过来必须都得是一定的大小(即与权重矩阵正好可以相乘的大小),所以网络最开始的输入图像尺寸必须固定,才能保证传送到全连接层的feature map的大小跟全连接层的权重矩阵匹配。
卷积层就不需要固定大小了,因为它只是对局部区域进行窗口滑动,所以用卷积层取代全连接层成为了可能,看我这一节:深度学习---之全卷积神经网络取代全连接层--用于图像分割