说明:
本文的宗旨是给一些接触了MapReduce,但是对MapReduce原理流程还不了解的人员,也包括笔者自己,那就一起来学习吧。
MapReduce的原理:
MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入
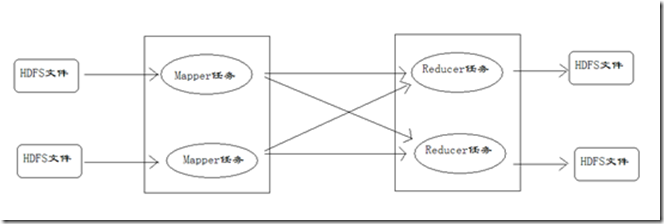
文本的数据记录:如文本的行就是以"键值对"的方式传入Map函数,然后Map函数对这些键值对进行处理(例:计算词频),然后输出到中间结果。
Map就是一个Java进程,它会读取HDFS,会把数据解析成很多的键值对,然后经过我们的Map方法处理后,转换成很多的键值对再输出。
整个Mapper的执行过程又可以分如下几步:
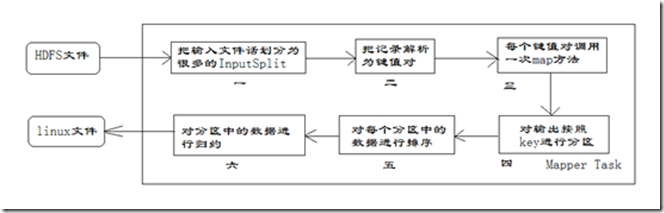
在上图中,把Mapper任务的运行过程分为六个阶段。
第一阶段是把输入文件按照一定的标准分片 (InputSplit),每个输入片的大小是固定的。默认情况下,输入片(InputSplit)的大小与数据块(Block)的大小是相同的。如果数据块(Block)的大小是默认值64MB,输入文件有两个,一个是32MB,一个是72MB。那么小的文件是一个输入片,大文件会分为两个数据块,那么是两个输入片,一共产生三个输入片。每一个输入片由一个Mapper进程处理,这里的三个输入片,会有三个Mapper进程处理。
第二阶段是对输入片中的记录按照一定的规则解析成键值对,有个默认规则是把每一行文本内容解析成键值对,这里的“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。
第三阶段是调用Mapper类中的map方法,在第二阶段中解析出来的每一个键值对,调用一次map方法,如果有1000个键值对,就会调用1000次map方法,每一次调用map方法会输出零个或者多个键值对。
第四阶段是按照一定的规则对第三阶段输出的键值对进行分区,分区是基于键进行的,比如我们的键表示省份(如北京、上海、山东等),那么就可以按照不同省份进行分区,同一个省份的键值对划分到一个区中。默认情况下只有一个区,分区的数量就是Reducer任务运行的数量,因此默认只有一个Reducer任务。
第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值 对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果 是<1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到本地的linux 文件中。
第六阶段是对数据进行归约处理,也就是reduce处理,通常情况下的Comber过程,键相等的键值对会调用一次reduce方法,经过这一阶段,数据量会减少,归约后的数据输出到本地的linxu文件中。本阶段默认是没有的,需要用户自己增加这一阶段的代码。
二、Reducer任务的执行过程详解
每个Reducer任务是一个java进程。Reducer任务接收Mapper任务的输出,归约处理后写入到HDFS中,可以分为如下图所示的几个阶段。
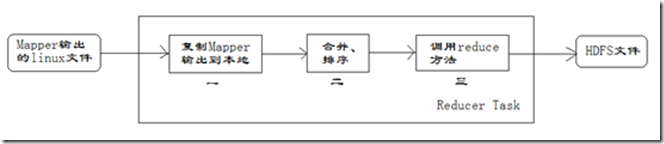
1、第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对,Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
2、第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据,再对合并后的数据排序。
3、第三阶段是对排序后的键值对调用reduce方法,键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到HDFS文件中。
三、键值对的编号
在对Mapper任务、Reducer任务的分析过程中,会看到很多阶段都出现了键值对,这里对键值对进行编号,方便理解键值对的变化情况,如下图所示。
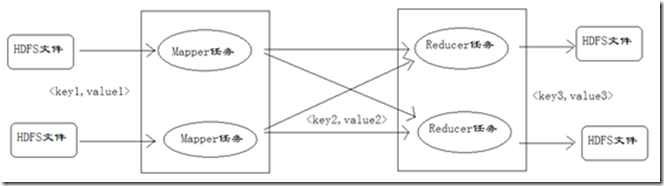
在上图中,对于Mapper任务输入的键值对,定义为key1和value1,在map方法中处理后,输出的键值对,定义为key2和value2,reduce方法接收key2和value2处理后,输出key3和value3。在下文讨论键值对时,可能把key1和value1简写 为<k1,v1>,key2和value2简写为<k2,v2>,key3和value3简写为<k3,v3>。
四、实例:
2014010216
2014010410
2012010609
2012010812
2012011023
2001010212
2001010411
2013010619
2013010812
2013011023
2008010216
2008010414
2007010619
2007010812
2007011023
2010010216
2010010410
2015010649
2015010812
2015011023比如:2010012325表示在2010年01月23日的气温为25度。现在要求使用MapReduce,计算每一年出现过的最大气温。
package com.abc.yarn;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Temperature {
/**
* 四个泛型类型分别代表:
* KeyIn Mapper的输入数据的Key,这里是每行文字的起始位置(0,11,...)
* ValueIn Mapper的输入数据的Value,这里是每行文字
* KeyOut Mapper的输出数据的Key,这里是每行文字中的“年份”
* ValueOut Mapper的输出数据的Value,这里是每行文字中的“气温”
*/
static class TempMapper extends
Mapper<LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 打印样本: Before Mapper: 0, 2000010115
System.out.print("Before Mapper: " + key + ", " + value);
String line = value.toString();
String year = line.substring(0, 4);
int temperature = Integer.parseInt(line.substring(8));
context.write(new Text(year), new IntWritable(temperature));
// 打印样本: After Mapper:2000, 15
System.out.println(
"======" +
"After Mapper:" + new Text(year) + ", " + new IntWritable(temperature));
}
}
/**
* 四个泛型类型分别代表:
* KeyIn Reducer的输入数据的Key,这里是每行文字中的“年份”
* ValueIn Reducer的输入数据的Value,这里是每行文字中的“气温”
* KeyOut Reducer的输出数据的Key,这里是不重复的“年份”
* ValueOut Reducer的输出数据的Value,这里是这一年中的“最高气温”
*/
static class TempReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
StringBuffer sb = new StringBuffer();
//取values的最大值
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
sb.append(value).append(", ");
}
// 打印样本: Before Reduce: 2000, 15, 23, 99, 12, 22,
System.out.print("Before Reduce: " + key + ", " + sb.toString());
context.write(key, new IntWritable(maxValue));
// 打印样本: After Reduce: 2000, 99
System.out.println(
"======" +
"After Reduce: " + key + ", " + maxValue);
}
}
public static void main(String[] args) throws Exception {
//输入路径
String dst = "hdfs://localhost:9000/intput.txt";
//输出路径,必须是不存在的,空文件加也不行。
String dstOut = "hdfs://localhost:9000/output";
Configuration hadoopConfig = new Configuration();
hadoopConfig.set("fs.hdfs.impl",
org.apache.hadoop.hdfs.DistributedFileSystem.class.getName()
);
hadoopConfig.set("fs.file.impl",
org.apache.hadoop.fs.LocalFileSystem.class.getName()
);
Job job = new Job(hadoopConfig);
//如果需要打成jar运行,需要下面这句
//job.setJarByClass(NewMaxTemperature.class);
//job执行作业时输入和输出文件的路径
FileInputFormat.addInputPath(job, new Path(dst));
FileOutputFormat.setOutputPath(job, new Path(dstOut));
//指定自定义的Mapper和Reducer作为两个阶段的任务处理类
job.setMapperClass(TempMapper.class);
job.setReducerClass(TempReducer.class);
//设置最后输出结果的Key和Value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//执行job,直到完成
job.waitForCompletion(true);
System.out.println("Finished");
}
}上面代码中,注意Mapper类的泛型不是java的基本类型,而是Hadoop的数据类型Text、IntWritable。我们可以简单的等价为java的类String、int。
代码中Mapper类的泛型依次是<k1,v1,k2,v2>。map方法的第二个形参是行文本内容,是我们关心的。核心代码是把行文本内容按照空格拆分,把每行数据中“年”和“气温”提取出来,其中“年”作为新的键,“温度”作为新的值,写入到上下文context中。在这里,因为每一年有多行数据,因此每一行都会输出一个<年份, 气温>键值对。
Before Mapper: 0, 2014010114======After Mapper:2014, 14
Before Mapper: 11, 2014010216======After Mapper:2014, 16
Before Mapper: 22, 2014010317======After Mapper:2014, 17
Before Mapper: 33, 2014010410======After Mapper:2014, 10
Before Mapper: 44, 2014010506======After Mapper:2014, 6
Before Mapper: 55, 2012010609======After Mapper:2012, 9
Before Mapper: 66, 2012010732======After Mapper:2012, 32
Before Mapper: 77, 2012010812======After Mapper:2012, 12
Before Mapper: 88, 2012010919======After Mapper:2012, 19
Before Mapper: 99, 2012011023======After Mapper:2012, 23
Before Mapper: 110, 2001010116======After Mapper:2001, 16
Before Mapper: 121, 2001010212======After Mapper:2001, 12
Before Mapper: 132, 2001010310======After Mapper:2001, 10
Before Mapper: 143, 2001010411======After Mapper:2001, 11
Before Mapper: 154, 2001010529======After Mapper:2001, 29
Before Mapper: 165, 2013010619======After Mapper:2013, 19
Before Mapper: 176, 2013010722======After Mapper:2013, 22
Before Mapper: 187, 2013010812======After Mapper:2013, 12
Before Mapper: 198, 2013010929======After Mapper:2013, 29
Before Mapper: 209, 2013011023======After Mapper:2013, 23
Before Mapper: 220, 2008010105======After Mapper:2008, 5
Before Mapper: 231, 2008010216======After Mapper:2008, 16
Before Mapper: 242, 2008010337======After Mapper:2008, 37
Before Mapper: 253, 2008010414======After Mapper:2008, 14
Before Mapper: 264, 2008010516======After Mapper:2008, 16
Before Mapper: 275, 2007010619======After Mapper:2007, 19
Before Mapper: 286, 2007010712======After Mapper:2007, 12
Before Mapper: 297, 2007010812======After Mapper:2007, 12
Before Mapper: 308, 2007010999======After Mapper:2007, 99
Before Mapper: 319, 2007011023======After Mapper:2007, 23
Before Mapper: 330, 2010010114======After Mapper:2010, 14
Before Mapper: 341, 2010010216======After Mapper:2010, 16
Before Mapper: 352, 2010010317======After Mapper:2010, 17
Before Mapper: 363, 2010010410======After Mapper:2010, 10
Before Mapper: 374, 2010010506======After Mapper:2010, 6
Before Mapper: 385, 2015010649======After Mapper:2015, 49
Before Mapper: 396, 2015010722======After Mapper:2015, 22
Before Mapper: 407, 2015010812======After Mapper:2015, 12
Before Mapper: 418, 2015010999======After Mapper:2015, 99
Before Mapper: 429, 2015011023======After Mapper:2015, 23
Before Reduce: 2001, 12, 10, 11, 29, 16, ======After Reduce: 2001, 29
Before Reduce: 2007, 23, 19, 12, 12, 99, ======After Reduce: 2007, 99
Before Reduce: 2008, 16, 14, 37, 16, 5, ======After Reduce: 2008, 37
Before Reduce: 2010, 10, 6, 14, 16, 17, ======After Reduce: 2010, 17
Before Reduce: 2012, 19, 12, 32, 9, 23, ======After Reduce: 2012, 32
Before Reduce: 2013, 23, 29, 12, 22, 19, ======After Reduce: 2013, 29
Before Reduce: 2014, 14, 6, 10, 17, 16, ======After Reduce: 2014, 17
Before Reduce: 2015, 23, 49, 22, 12, 99, ======After Reduce: 2015, 99
程序执行结果:

对分析的验证:从打印的日志中可以看出:
-
Mapper的输入数据(k1,v1)格式是:默认的按行分的键值对<0, 2010012325>,<11, 2012010123>...
-
Reducer的输入数据格式是:把相同的键合并后的键值对:<2001, [12, 32, 25...]>,<2007, [20, 34, 30...]>...
-
Reducer的输出数(k3,v3)据格式是:经自己在Reducer中写出的格式:<2001, 32>,<2007, 34>...
其中,由于输入数据太小,Map过程的第1阶段这里不能证明。但事实上是这样的。结论中第一点验证了Map过程的第2阶段:“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。另外,通过Reduce的几行
Before Reduce: 2001, 12, 10, 11, 29, 16, ======After Reduce: 2001, 29
Before Reduce: 2007, 23, 19, 12, 12, 99, ======After Reduce: 2007, 99
Before Reduce: 2008, 16, 14, 37, 16, 5, ======After Reduce: 2008, 37
Before Reduce: 2010, 10, 6, 14, 16, 17, ======After Reduce: 2010, 17
Before Reduce: 2012, 19, 12, 32, 9, 23, ======After Reduce: 2012, 32
Before Reduce: 2013, 23, 29, 12, 22, 19, ======After Reduce: 2013, 29
Before Reduce: 2014, 14, 6, 10, 17, 16, ======After Reduce: 2014, 17
Before Reduce: 2015, 23, 49, 22, 12, 99, ======After Reduce: 2015, 99可以证实Map过程的第4阶段:先分区,然后对每个分区都执行一次Reduce(Map过程第6阶段),对于Mapper的输出,前文中提到:如果没有Reduce过程,Mapper的输出会直接写入文件,于是我们把Reduce方法去掉(注释掉第95行即可),再执行,下面是控制台打印结果:
Before Mapper: 0, 2014010114======After Mapper:2014, 14
Before Mapper: 11, 2014010216======After Mapper:2014, 16
Before Mapper: 22, 2014010317======After Mapper:2014, 17
Before Mapper: 33, 2014010410======After Mapper:2014, 10
Before Mapper: 44, 2014010506======After Mapper:2014, 6
Before Mapper: 55, 2012010609======After Mapper:2012, 9
Before Mapper: 66, 2012010732======After Mapper:2012, 32
Before Mapper: 77, 2012010812======After Mapper:2012, 12
Before Mapper: 88, 2012010919======After Mapper:2012, 19
Before Mapper: 99, 2012011023======After Mapper:2012, 23
Before Mapper: 110, 2001010116======After Mapper:2001, 16
Before Mapper: 121, 2001010212======After Mapper:2001, 12
Before Mapper: 132, 2001010310======After Mapper:2001, 10
Before Mapper: 143, 2001010411======After Mapper:2001, 11
Before Mapper: 154, 2001010529======After Mapper:2001, 29
Before Mapper: 165, 2013010619======After Mapper:2013, 19
Before Mapper: 176, 2013010722======After Mapper:2013, 22
Before Mapper: 187, 2013010812======After Mapper:2013, 12
Before Mapper: 198, 2013010929======After Mapper:2013, 29
Before Mapper: 209, 2013011023======After Mapper:2013, 23
Before Mapper: 220, 2008010105======After Mapper:2008, 5
Before Mapper: 231, 2008010216======After Mapper:2008, 16
Before Mapper: 242, 2008010337======After Mapper:2008, 37
Before Mapper: 253, 2008010414======After Mapper:2008, 14
Before Mapper: 264, 2008010516======After Mapper:2008, 16
Before Mapper: 275, 2007010619======After Mapper:2007, 19
Before Mapper: 286, 2007010712======After Mapper:2007, 12
Before Mapper: 297, 2007010812======After Mapper:2007, 12
Before Mapper: 308, 2007010999======After Mapper:2007, 99
Before Mapper: 319, 2007011023======After Mapper:2007, 23
Before Mapper: 330, 2010010114======After Mapper:2010, 14
Before Mapper: 341, 2010010216======After Mapper:2010, 16
Before Mapper: 352, 2010010317======After Mapper:2010, 17
Before Mapper: 363, 2010010410======After Mapper:2010, 10
Before Mapper: 374, 2010010506======After Mapper:2010, 6
Before Mapper: 385, 2015010649======After Mapper:2015, 49
Before Mapper: 396, 2015010722======After Mapper:2015, 22
Before Mapper: 407, 2015010812======After Mapper:2015, 12
Before Mapper: 418, 2015010999======After Mapper:2015, 99
Before Mapper: 429, 2015011023======After Mapper:2015, 23
Finished控制台执行结果:
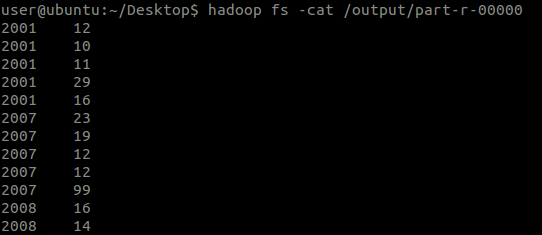
由于没有执行Reduce操作,因此这个就是Mapper输出的中间文件的内容了。从打印的日志可以看出:Mapper的输出数据(k2, v2)格式是:经自己在Mapper中写出的格式:<2010, 25>,<2012, 23>...从这个结果中可以看出,原数据文件中的每一行确实都有一行输出,那么Map过程的第3阶段就证实了。从这个结果中还可以看出,“年份”已经不是输入给Mapper的顺序了,这也说明了在Map过程中也按照Key执行了排序操作,即Map过程的第5阶段。