注:为了方便理解下面的代码都是分行书写,如果一次拷贝在mysql可能报错,请一行一行拷贝,或者一次性拷贝后检查格式(如添加或删除空格)
举例说明,下面这段代码:
select sheng.id as sid,sheng.title as stitle,
shi.id as shiid,shi.title as shititle
from areas as sheng
inner join areas as shi on sheng.id=shi.pid;

自查询
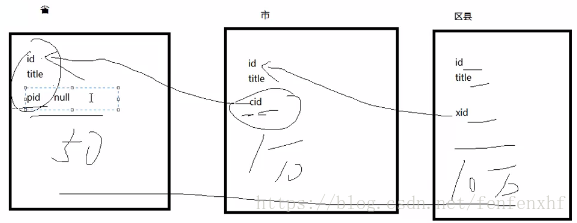
目的:当存在关系的几张表中数据结构比较像,而且数据量都不是很大时候,我们可以只建一张表,以减小数据库的开销,如图(截取的是网课的视频)
注:其中省表中pid是人为添加为null,保持和后面表结构的一致
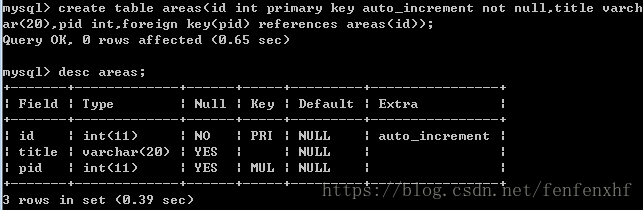
create table areas(
id int primary key auto_increment not null,
title varchar(20),pid int,
foreign key(pid) references areas(id)
);
导入脚本文件
source areas.sql;
注:这里没有数据集areas.sql,所以一下查询仅为代码演示
1.查询省的总数
select count(*) from areas where pid is null;
2.查询省的名称为山西省的所有城市
分析:
select * from areas as province where title=‘山西省’;
select * from areas where pid=(select id from areas where title=‘山西省’);
select * from areas as sheng inner join areas as shi on sheng.id=shi.pid
优化一下
select sheng.id as sid,sheng.title as stitle,
shi.id as shiid,shi.title as shititle
from areas as sheng
inner join areas as shi on sheng.id=shi.pid;
视图
目的:视图的本质就是对查询的一个封装,对于复杂的查询在多次使用后维护是一件非常麻烦的事情
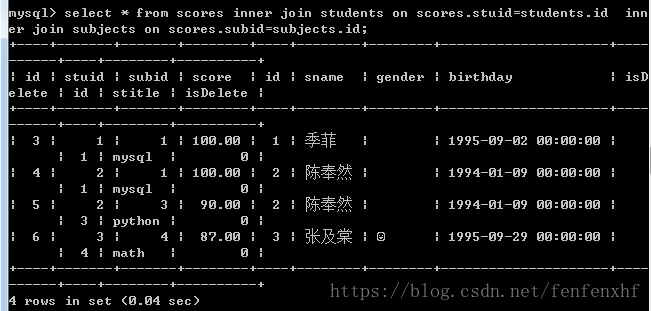
select * from scores
inner join students on scores.stuid=students.id
inner join subjects on scores.subid=subjects.id;
如果多个地方调用上面这段代码,我们就可以进行分装,方面后面的修改和维护
create view 视图名(一般以v_开头,以区别是封装的view)as select * from scores inner join students on scores.stuid=students.id inner join subjects on scores.subid=subjects.id;
create view v_stu_sub_sco as
select * from scores
inner join students on scores.stuid=students.id
inner join subjects on scores.subid=subjects.id;
这里报错:id列名重复
更改如下:

create view v_stu_sub_sco as
select students.*,scores.score,subjects.stitle from scores
inner join students on scores.stuid=students.id
inner join subjects on scores.subid=subjects.id;
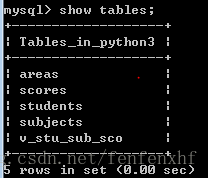
我们可以在tables的列表中看到 v_stu_sub_sco的视图
查询视图select * from v_stu_sub_sco;
后面要修改视图就用alter修改视图信息,比如:
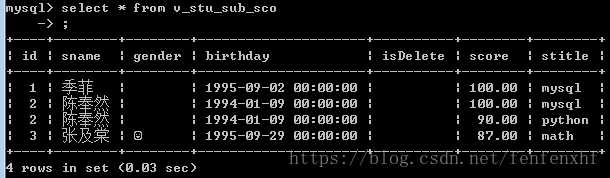
alter view v_stu_sub_sco as
select students.*,scores.score,subjects.stitle from scores
inner join students on scores.stuid=students.id
inner join subjects on scores.subid=subjects.id
where students.isDelete=0;
事务
目的:当使用多条sql语句,如果其中某条sql语句出错,则退出,保证业务逻辑的正确性
四大特性:原子性(事物的全部操作是不可分割的,要么不做要么做完);一致性(并行执行的事务与按某一顺序串行执行的结果一致);隔离性(事务执行不受其他事务的干扰,事务执行的中间结果对其他事务保持透明);持久性(对任意已提交的事务,系统必须保证该事务对数据库改变的结果不丢失即便数据库出现故障)
使用事务的情况:当数据被更改时(update,insert,delete)
注:表的类型必须是innodb(用的多)或bdb,才可以对此表使用事务
修改引擎:
alter table '表名' engine=innodb;
事务命令:
begin开启;commit提交;rollback回滚
事务的使用:先开启两个终端
1.首先终端1输入命令begin;
2.终端1输入更改数据的命令,如update students set sname='菲菲' where id=1;
注:这里在终端2查询数据select * from students;这里数据不变;但是在终端1查询数据select * from students;这里的数据是改变后的数据,但是并非物理内存上改变
3.输入命令commit;
如果要撤回操作则将第三步命令改为rollback也就是begin之后的操作都撤销
注:在第2步更改数据之后并没有改变物理内存,只是给了个临时空间,在第三步commit之后才会更改原始数据,也就是这里两个终端输入select * from students;结果都是改变后的数据
索引
目的:方便查找数据,主键和唯一索引都是索引可提高查询的速度
弊:增加索引会增加数据库的开销
选择列的数据类型:数据类型越小越好(能用bit就不用int);简单的数据类型更好(如整型比字符串开销更小);尽量避免NULL
注:在where后的条件尽量等式在前不等式在后,不然先出现了不等式,那么之后再建索引就不起作用了;尽量条件不用or,否则速度优化效果也不好,如:
where gender=1 and isDelete=0 and brithday>'1996-1-1';
查看索引:
show index from 表名;
创建索引:
create index 索引名 on 表名(列名(指定长度)); #如果是int就不用指定长度
删除索引:
drop index 索引名 on 表名;
接下来具体分析一下索引的使用过程:
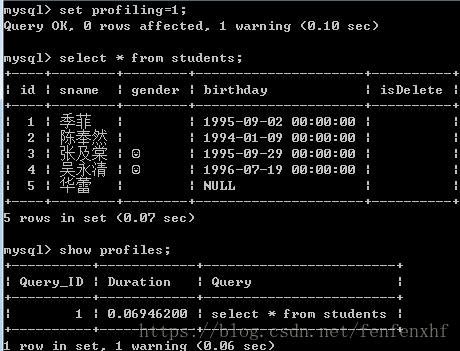
查看执行时间:
set profiling=1;#开启监测
select * from students;
show profiles;#查看执行时间
查看索引:
show index from students;
添加索引:
create index snameIndex on students(sname(10));
再执行命令select * from students;
再查看时间show profiles;
