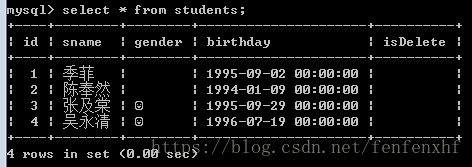
以下的所有查询基于这个表来做
查询☆☆☆
查询的基本语法
select * form 表名;
注:*表示查询所有的列;select后面的列名可以用as另取别名,如果要查询多个类列那么列与列之间要用逗号隔开
select id,sname from students; #这里只是显示结果,结果物理不存在的
消除重复行
在select后选择的列前用distinct可以消除重复行
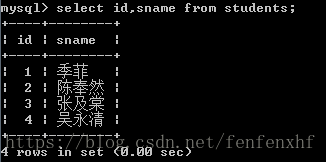
select distinct gender from students; #结果如下:
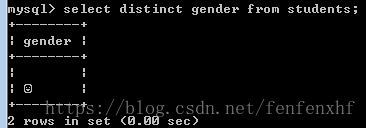
select distinct id,gender from students;#结果如下:这里的id和gender组成的两列都是不重复的
条件
select * from 表名 where 条件;
比较运算符:
大于>;大于等于>=;小于<;小于等于<=;不等于!=或<>
select * from students where id>3; #查询编号大于3的学生
select * from students where sname!='季菲'; #查询姓名不等于季菲的学生
逻辑运算符:
and;or;not
select * from students where id>3 and gender=0;#查询编号大于3的女同学
select * from students where id<4 or isDelete=0;#
模糊查询:
关键字(like)
%表示任意多个字符,_表示任意一个字符
select * from students where sname like '陈%'; #查询姓陈的学生信息
select * from students where sname like '陈_';#查询姓陈的但是名字只有两个字的学生信息
select * from students where sname like '陈%' or '%菲'; #查询结果如下:只显示or的第一个条件
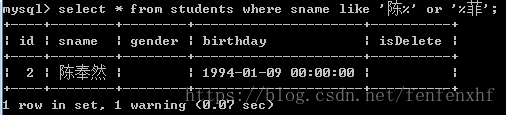
select * from students where sname like '陈%' or sname like '%菲'; #查询结果如下:
范围查询:
in表示在一个不连续的范围内查询
select * from students where id in(1,3,8);#查询id为1或3或8的学生
between…and…表示在一个连续的范围内查询
select * from students where id between 3 and 8;#查询id在3-8之间的学生
注:一旦遇到between后面最近的and是和前面的between是一对的
select * from students where id between 3 and 8 and gender=1; ##查询id在3-8之间以及性别为男的学生
判空或非空:
注:null和’ ‘这是不一样的,其中null是没有分配内存的,但是’ '是分配内存的
以下操作用如下表
判空select * from 表名 where 列名 is null;
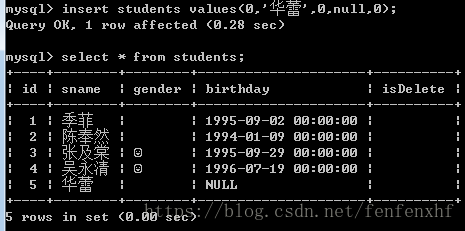
select * from students where birthday is null; #结果如下:
判非空select * from 表名 where 列名 is not null;

select * from students where birthday is not null and gender=0; #查询填写了生日的女生
优先级
小括号>not>比较运算符>逻辑运算符
逻辑运算符中and>or
注:可以用小括号来改变优先级
聚合
count(*) 表示计算总行数,括号中写’*'或者列名,结果相同
select count(*) from students; #查询学生表的总行数
max(列名)表示求此列的最大值;min(列名)表示求此列的最小值;sum(列名)表示求此列的和;avg(列名)表示求此列的平均值
select max(id) from students where gender=0;#查询女生编号的最大值
select min(id) from students where isDelete=0;#查询未删除学生的最小编号
select sum(id) from students where gender=1;#查询男生的编号之和
select avg(id) from students where isDelete=0 and gender=1;#查询未删除男生编号的平均值
注:聚合返回的结果不会返回原始数据,只会返回聚合结果
分组
按照字段分组,表示此字段相同的数据会被分到一个组中,分组后只能查询出相同的数据列,对于有差异的数据无法显示在结果中;可以对分组后的数据进行聚合运算,语法:
select 列1,列2,聚合... from 表名 group by 列1,列2,列3...
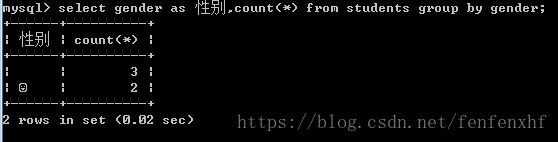
select gender as 性别,count(*) from students group by gender; #查询男女分别的总数
分组后的数据筛选
select 列1,列2,聚合... from 表名 group by 列1,列2,... having 列1,...聚合...
select gender as 性别,count(*) from students group by gender having 性别=1; #查询上图结果集中男生的总数
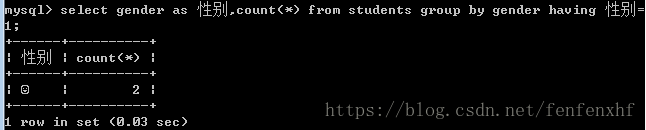
select gender as 性别,count(*) from students group by gender having count(*)>2; #查询上图结果集中总数大于2的
注:where是对原始数据集进行筛选,而having是对分组后的数据集(group by)进行筛选
排序
select * from 表名 order by 列1 asc|desc,列1 asc|desc,...
注:#desc降序,asc升序,默认asc;
将 行数据按照列1进行排序,如果某些列1的值相同时,则按照列2排序,以此类推
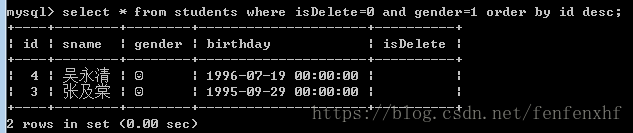
select * from students where isDelete=0 and gender=1 order by id desc; #未删除男生学生信息按照降序排列
分页
当数据量过大时,在一页中查看数据是一件非常麻烦的事情
select * from 表名 limit start,count #从start开始(start索引从0开始),获取count条数据;
注:limit的start是0开始,是不管id的
select * from students limit 0,2; #查看头两条数据
select * from students limit 1,2;#查看从第1条数据开始后的两条数据
已知:每个显示m条数据,当前是第n页(n>=1),代码如下:
select * from students limit (n-1)*m,m; #start=(n-1)*m,count=m