版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/GY_Grace/article/details/72863632
因为项目内容中涉及自动生成文本摘要的功能,因此学习了一下TextRank算法实现摘要提取。
1.介绍一下TextRank算法
TextRank算法的思想是,拟定一个通用的评分标准,给文本中的每一个句子打分,所得分数就是该句子的权重,最后得到权重排名靠前的几个句子,构成最终的文本摘要。这就是所谓的TextRank自动生成摘要。
TextRank对每一个句子的打分思想由PageRank的迭代思想衍生而来,公式如下:
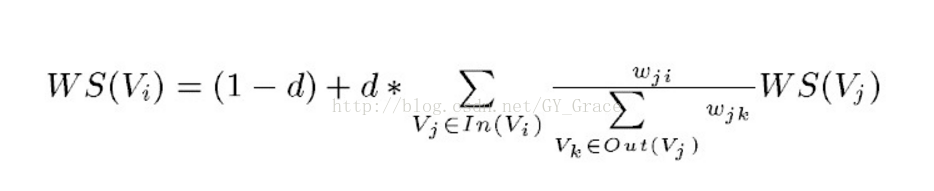
在这个公式中,WS(i)表示第i个句子的权重,右侧的求和表示的是每一个句子对所在文本的贡献程度。求和部分的分子wji表示两个句子j和i的相似程度,分母则是文本中相对应的部分的句子的权重之和,WS(Vj)表示上次迭代j的权重。
从整个公式可以看出这是一个反复迭代的过程。
由于wji需要计算两个句子的相似程度,因此这里我们需要引入另外的相似度算法,通常推荐使用BM25,这是目前已知的计算结果较为准确的算法之一。
这个公式中的d是一个常数,称为阻尼系数,通常在算法中我们取其值为0.85,当然也可以根据实际的情况进行调整。
2.TextRank算法的Java实现
2.1首先需要声明相关的变量
/** * 阻尼系数(DampingFactor),一般取值为0.85 */ final double d = 0.85f; /** * 最大迭代次数 */ final int max_iter = 200; final double min_diff = 0.001f; /** * 文档句子的个数 */ int D; /** * 拆分为[句子[单词]]形式的文档 */ List<List<String>> docs; /** * 排序后的最终结果 score <-> index */ TreeMap<Double, Integer> top; /** * 句子和其他句子的相关程度 */ double[][] weight; /** * 该句子和其他句子相关程度之和 */ double[] weight_sum; /** * 迭代之后收敛的权重 */ double[] vertex; /** * BM25相似度 */ BM25 bm25;
扫描二维码关注公众号,回复:
3297385 查看本文章

2.2 实现文本切割成句子
List<String> sentences = new ArrayList<String>(); if (document == null) return sentences; for (String line : document.split("[\r\n]")) { line = line.trim();//去掉字符串的首尾空格 if (line.length() == 0) continue; for (String sent : line.split("[,,.。::“”??!!;;]")) { sent = sent.trim(); if (sent.length() == 0) continue; sentences.add(sent); } }
2.3 使用开源jar包对中文文本进行分词,并获得分词结果
List<String> sentenceList = spiltSentence(document);//用,。”“等标点将文本切割成了短句 List<List<String>> docs = new ArrayList<List<String>>(); for (String sentence : sentenceList) { List<Term> termList = ToAnalysis.parse(sentence);//使用开源的ansj对句子进行分词 List<String> wordList = new LinkedList<String>(); for (Term term : termList) { if (shouldInclude(term)) { wordList.add(term.getRealName()); } } docs.add(wordList); } TextRankSummary textRankSummary = new TextRankSummary(docs); int[] topSentence = textRankSummary.getTopSentence(size); List<String> resultList = new LinkedList<String>(); for (int i : topSentence) { resultList.add(sentenceList.get(i)); } return resultList;
2.4 运用公式计算出每个句子的权重并进行排序
int cnt = 0; for (List<String> sentence : docs) { double[] scores = bm25.simAll(sentence);//计算相似度 System.out.println(Arrays.toString(scores)); weight[cnt] = scores; weight_sum[cnt] = sum(scores) - scores[cnt]; // 减掉自己,自己跟自己肯定最相似 vertex[cnt] = 1.0; ++cnt; } for (int _ = 0; _ < max_iter; ++_) { double[] m = new double[D]; double max_diff = 0; for (int i = 0; i < D; ++i) { m[i] = 1 - d; for (int j = 0; j < D; ++j) { if (j == i || weight_sum[j] == 0) continue; m[i] += (d * weight[j][i] / weight_sum[j] * vertex[j]); } double diff = Math.abs(m[i] - vertex[i]); if (diff > max_diff) { max_diff = diff; } } vertex = m; if (max_diff <= min_diff) break; } // for (int i = 0; i < D; ++i) { top.put(vertex[i], i); }
2.5 设置想要获取的目标摘要长度,并根据排序结果取出摘要
Collection<Integer> values = top.values(); size = Math.min(size, values.size()); int[] indexArray = new int[size]; Iterator<Integer> it = values.iterator(); for (int i = 0; i < size; ++i) { indexArray[i] = it.next(); } return indexArray;
以上就是对TextRank算法的学习内容的概括。