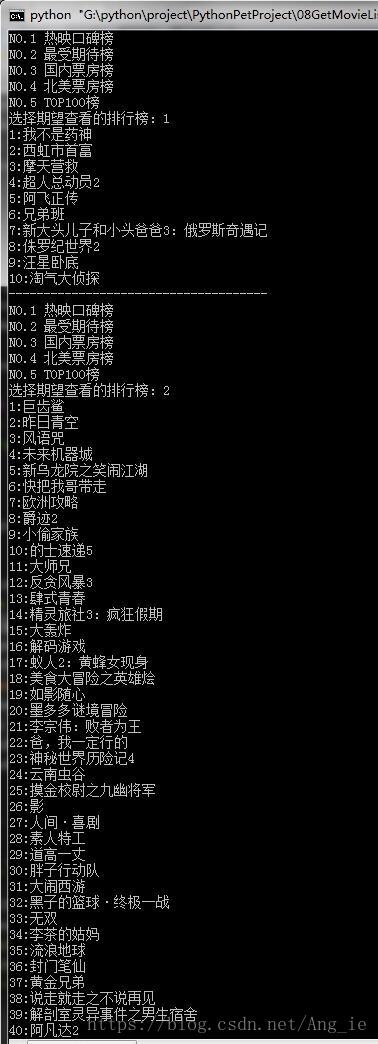
简述
这次打算写一个爬虫系列,一边也想好好总结巩固学习的知识,一边做总结笔记,方便以后回忆。这次我们使用Python3和正则表达式来爬取一个简单html页面信息,就从猫眼电影的排行榜单开始吧。如果读到这篇文章的是位大神,期望您能不吝赐教,指正错误,如果您是小白,咋们可以一同探讨学习,共同进步。下面咋们开始.....
分析
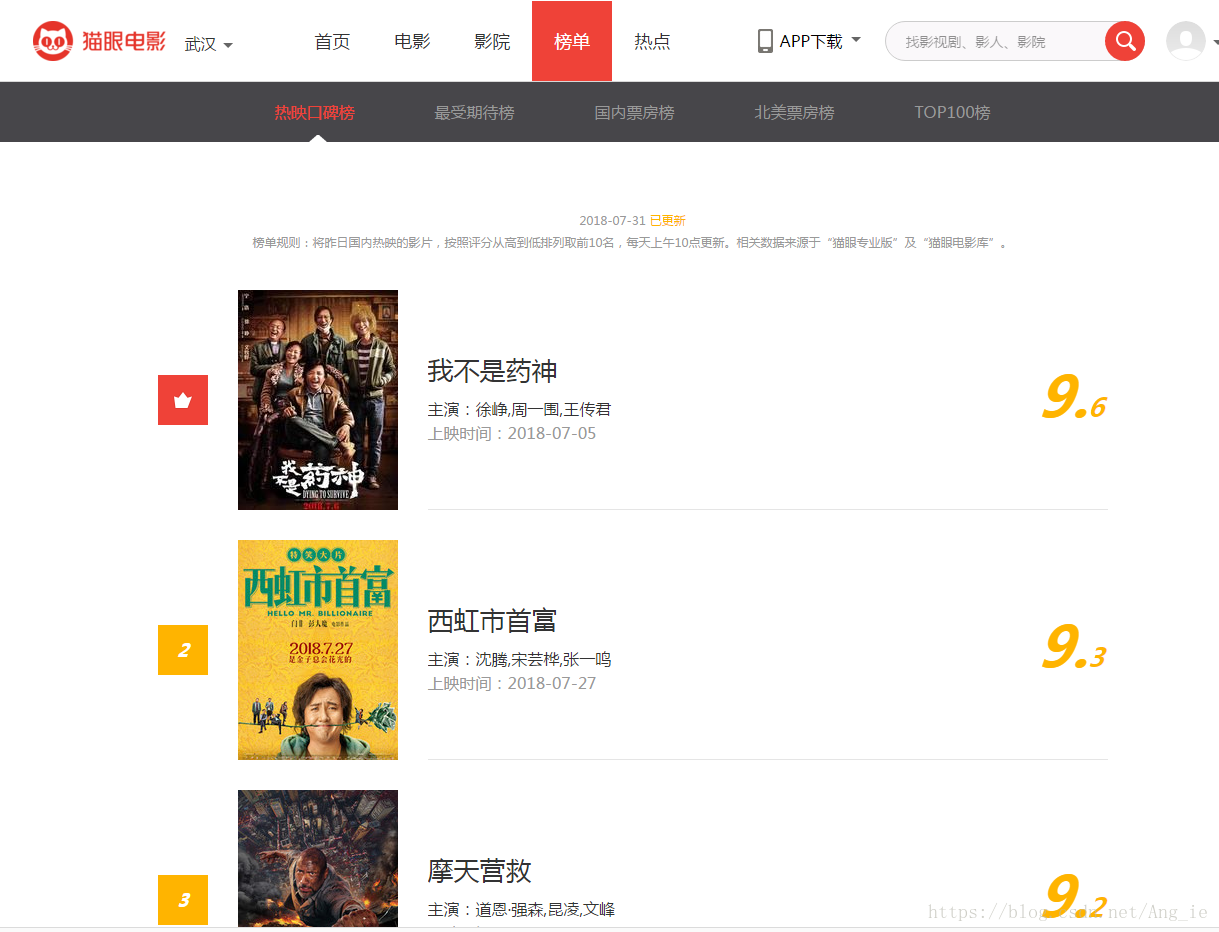
首先使用浏览器登录到猫眼电影页面,点击上面的“榜单”字样,下面可以看到“热映口碑榜”、“最受期待榜”、“国内票房榜”、“北美票房榜”和“Top100榜”。这次我们把这些个排行榜全部都爬取下来,并且根据自己的选择,期望显示获得哪个排行榜,开始动刀子,第一步当然是打开浏览器的开发者工具,按F5刷新一遍,可以看到下图:
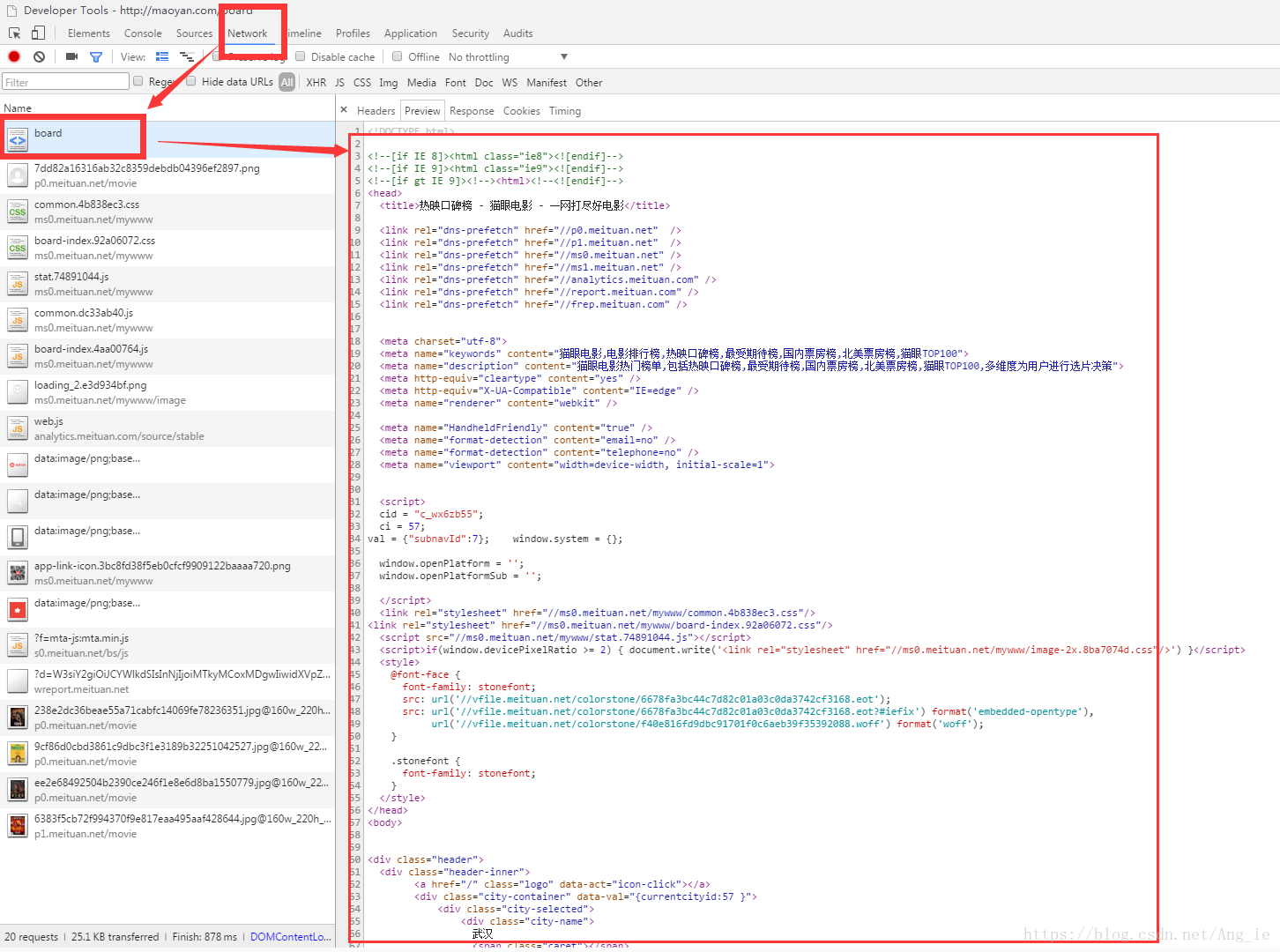
看到右边的preview就是整个页面的html主体数据,主要分析一下这个页面的html结构,将我们需要的信息提取出来即可,我们往下翻,可以看到信息如下
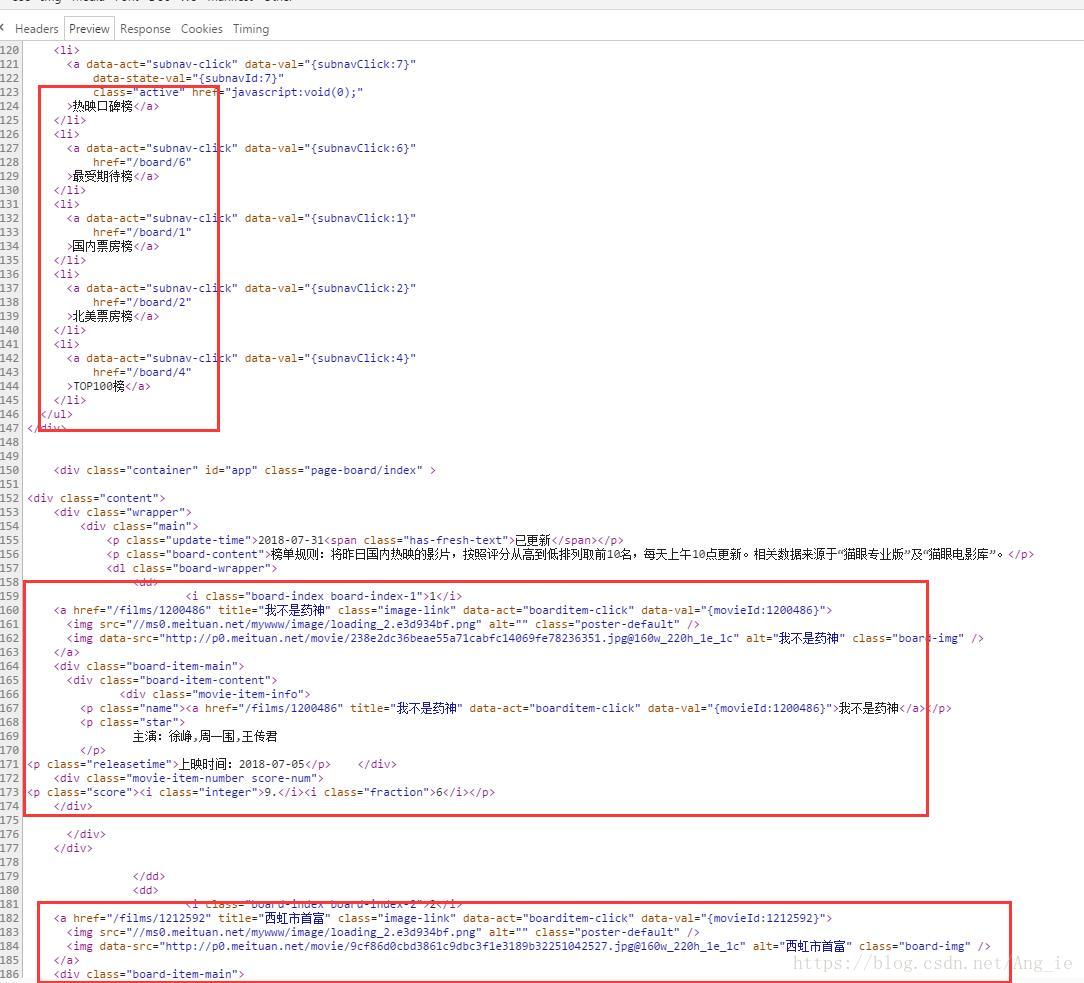
最上面那些个各种“榜”正是我们需要的榜单,这时候在观察分析一下这些个“榜”节点的情况:
<a data-act="subnav-click" data-val="{subnavClick:1}" href="/board/1">国内票房榜</a>再对应着点击每一个榜单查看其相应的url,可以发现:
Top100榜:http://maoyan.com/board/4
北美票房榜:http://maoyan.com/board/2
国内票房榜:http://maoyan.com/board/1
最受期待榜:http://maoyan.com/board/6
热映口碑榜:http://maoyan.com/board/7
可以知道,每个榜单的url都是最后的那个数字不同,对应相应的榜单。这个数字正好就是上面提到的a节点中的data-val这个属性后的那个数字,或者是href中的“/board/1”,这样就得到了我们第一部分所需的数据,即每一个榜单 url= http://maoyan.com/board/ + <对应数字>,现在就是想办法将数字提取出来就可以了,这时候就是正则表达式上场的时候了:

这里获取的是a节点中的data-val数字,当然也可以获取href属性,使用的正则表达式为:
<a d.*?subnavClick:(\d).*?>(.*?)</a>
这样就将榜单的名字和数字都一一对应的爬取下来了,相应的代码为:
#获取当前可以查看哪些排行榜
def getAllTopList(url):
NO = 1
response = requests.get(url, headers = header)
if response.status_code == 200:
allTop = re.findall('<a d.*?subnavClick:(\d).*?>(.*?)</a>' ,response.text, re.S)
for movie in allTop:
print('NO.' + str(NO) + ' ' + movie[1])
NO += 1
return allTop榜单列表有了,这时候就需要将该页面现有的排行榜信息爬取下来,在preview中可以看到电影的信息放在<dd></dd>节点中,我们就直接查找dd节点中的数据,可以看到电影名字在title属性中:
<a href="/films/1200486" title="我不是药神" class="image-link" data-act="boarditem-click" data-val="{movieId:1200486}">这时候可以再编辑一个函数用于获取当前页面的所有电影名字和排序:
#获取一个页面的信息
def getOnePage(url):
response = requests.get(url, headers=header)
if response.status_code == 200:
allTop = re.findall('<dd>.*?board-index-(\d+).*?title="(.*?)".*?/p>.*?</dd>', response.text, re.S)
return allTop,response.text有些榜单一页信息放不下,这时候就需要判断当前页面是否有第二页并且请求下一页的页面,获取数据:
#判断是否有,并返回下一页的页码
def judgeNextPage(text):
result = re.search('style="cursor: default".*?<li>[ ]+<a class="page_(\d+)".*?"(\?offset=\d+)".*?下一页</a>', text, re.S)
if result == None:
return None
else:
return (result.group(1),result.group(2))
#根据选择的显示出相应的排行榜
def showTopList(url, urlNum):
newUrl = url + '/' + urlNum[0]
response = requests.get(newUrl, headers=header)
TOPINFO,htmlText = getOnePage(newUrl)
pageInfo = judgeNextPage(htmlText)
while pageInfo != None:
nextPageUrl = newUrl + pageInfo[1]
topInfo,htmlText = getOnePage(nextPageUrl)
TOPINFO += topInfo
pageInfo = judgeNextPage(htmlText)
for x in TOPINFO:
print(x[0] + ':' + x[1])编码
这里是所有的代码,一眼看上去都是正则表达式:
import re
import requests
import time
topURL = 'https://maoyan.com/board'
header = {
'User-Agent': 'Mozilla / 5.0(Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
#获取当前可以查看哪些排行榜
def getAllTopList(url):
NO = 1
response = requests.get(url, headers = header)
if response.status_code == 200:
allTop = re.findall('<a d.*?subnavClick:(\d).*?>(.*?)</a>' ,response.text, re.S)
for movie in allTop:
print('NO.' + str(NO) + ' ' + movie[1])
NO += 1
return allTop
#获取一个页面的信息
def getOnePage(url):
response = requests.get(url, headers=header)
if response.status_code == 200:
allTop = re.findall('<dd>.*?board-index-(\d+).*?title="(.*?)".*?/p>.*?</dd>', response.text, re.S)
return allTop,response.text
#判断是否有,并返回下一页的页码
def judgeNextPage(text):
result = re.search('style="cursor: default".*?<li>[ ]+<a class="page_(\d+)".*?"(\?offset=\d+)".*?下一页</a>', text, re.S)
if result == None:
return None
else:
return (result.group(1),result.group(2))
#根据选择的显示出相应的排行榜
def showTopList(url, urlNum):
newUrl = url + '/' + urlNum[0]
response = requests.get(newUrl, headers=header)
TOPINFO,htmlText = getOnePage(newUrl)
pageInfo = judgeNextPage(htmlText)
while pageInfo != None:
nextPageUrl = newUrl + pageInfo[1]
topInfo,htmlText = getOnePage(nextPageUrl)
TOPINFO += topInfo
pageInfo = judgeNextPage(htmlText)
for x in TOPINFO:
print(x[0] + ':' + x[1])
if __name__ == '__main__':
while True:
topList = getAllTopList(topURL)
select = int(input('选择期望查看的排行榜:'))
if select <= len(topList):
showTopList(topURL, topList[select - 1])
print('-------------------------------------')