题目:有关属性离散化算法CACC的再次补充说明
在《贝叶斯网络结构学习之连续参数处理方法》中,开篇就提到“首先必须说明:严格来说,这不是一篇完整的文档,因为文档最后并没有给出确定的结果,至少个人不认为文档引用的几个程序一定是正确的。”,在上一篇《有关属性离散化算法CACC的补充说明》给出了一个肯定性的回答:文中提到的两个CACC实现版本中Julio Zaragoza的实现代码是正确的,但由于Julio Zaragoza的代码也得不到原论文中Table 6的结果,上一篇中给出了原因,一步一步地分析了要想得到Table 6的结果的实际算法与论文中描述的CACC算法的微小差异。
本篇补充说明主要是继续分析网友Guangdi Li分享的CACC的代码与原论文【Tsai C J, Lee C I, Yang W P. A discretization algorithm based on Class-Attribute Contingency Coefficient[J]. Information Sciences, 2008,178(3):714-731.】的差异之处,以复现原论文中Table 6的结果,用来离散化Table 2的Age数据集,而实际上网友Guangdi Li分享的CACC的代码只需要少量的修改就可以得到原文献中Table 6的结果。


下面,先给出修改的测试代码和修改的CACC代码,然后再逐行分析。
因为网友Guangdi Li分享的CACC的代码使用方法与Julio Zaragoza的实现代码有很大不同,所以先给出以Table 2为数据集、能用来测试Guangdi Li代码的测试代码ControlCenter.m(不同于网上公布的代码):
%ControlCenter.m
clear all;close all;clc;
contdata = [3,1; % here 1 (in the second column) stands for class 'Care'
5,1; % 2 stands for class 'Edu' and 3 stands for class 'Work'.
6,1;
15,2;
17,2;
21,2;
35,3;
45,3;
46,3;
51,2;
56,2;
57,2;
66,1;
70,1;
71,1];
OriginalData = zeros(size(contdata,1),4);
OriginalData(:,1) = contdata(:,1);
OriginalData(:,2) = (contdata(:,2)==1);
OriginalData(:,3) = (contdata(:,2)==2);
OriginalData(:,4) = (contdata(:,2)==3);
% one feature variable, three class labels.
% 1. Input variables include the traget database with continuous data, named
% as "OriginalData", the other database is the number of class variables.
% 2. Output variables include the processed database named as
% "DiscretData", the other is "DiscretizationSet" saving the used
% intervals.
[ DiscretData,DiscretizationSet1 ] = CACC_Discretization( OriginalData, 3 )
然后,给出网友Guangdi Li分享的CACC的代码CACC_Discretization修改版本,而实际上只修改了五处(第37行/第83行/第85行/第118行/第124行,所有行号与原代码均对应),且只有三处是有意义的修改(第83行和第85行实际上是为了输出显示Table 6中的Cutting point和Maximum cacc两列):
function [ DiscreData,DiscretizationSet ] = CACC_Discretization( OriginalData, C )
%Paper: Cheng-Jung Tsai , Chien-I. Lee , Wei-Pang Yang, A discretization
%algorithm based on Class-Attribute Contingency Coefficient, Information Sciences: an International Journal, v.178 n.3, p.714-731, February, 2008
%1 Input: Dataset with i continuous attribute, M examples and S target classes;
%2 Begin
%3 For each continuous attribute Ai
%4 Find the maximum dn and the minimum d0 values of Ai;
%5 Form a set of all distinct values of A in ascending order;
%6 Initialize all possible interval boundaries B with the minimum and maximum
%7 Calculate the midpoints of all the adjacent pairs in the set;
%8 Set the initial discretization scheme as D: {[d0,dn]}and Globalcacc = 0;
%9 Initialize k = 1;
%10 For each inner boundary B which is not already in scheme D,
%11 Add it into D;
%12 Calculate the corresponding cacc value;
%13 Pick up the scheme D?with the highest cacc value;
%14 If cacc > Globalcacc or k < S then
%15 Replace D with D?
%16 Globalcacc = cacc;
%17 k = k + 1;
%18 Goto Line 10;
%18 Else
%19 D?= D;
%20 End If
%21 Output the Discretization scheme D?with k intervals for continuous attribute Ai;
%22 End
% This code is implemented by Guangdi Li, 2009/06/04
% OriginalData is organized as F1,F2,...,Fm,C1,C2,...,Cn
F = size( OriginalData,2 ) - C ;
M = size( OriginalData,1 );
DiscreData = zeros( M,C+F );
DiscreData( :,F+1:F+C ) = OriginalData( :,F+1:F+C );
% Assume the maximum number of interval is M/(3*C)
MaxNumF = 4;%MaxNumF = floor(M/(3*C));
% Save all the discretization intervals, which is saved in column
DiscretizationSet = zeros( MaxNumF,F );
for p = 1:F
% Step 1
%Dn = max( OriginalData( :,p )); % the maximum boundary
%Do = min( OriginalData( :,p )); % the minimum boundary
SortedInterval = unique( OriginalData( :,p ) );
if length(SortedInterval) == 1 % all values are equal
DiscretizationSet( 1,p )= SortedInterval;
DiscreData( :,p ) = zeros(M,1);
continue;
end
B = zeros( 1,length( SortedInterval )-1 );
Len = length( B );
for q = 1:Len
B( q ) = ( SortedInterval( q ) + SortedInterval( q+1 ) )/ 2;
end
%B
D = zeros( 1,MaxNumF ); % D save all discretizations for variable Fi
%D( 1 ) = Do; D( 2 ) = Dn;
GlobalCACC = -Inf;
%B
%p
%Step 2
k=0; % save the number of discretizations in D, the initiate state is 2
while true
CACC = - Inf; Local = 0;
for q = 1:Len
if isempty( find( D( 1:k )==B(q), 1 ) ) == 1
DTemp = D;
DTemp( k+1 ) = B( q );
DTemp( 1:( k+1 ) ) = sort( DTemp( 1:( k+1 ) ) );
CACCValue = CACC_Evaluation( OriginalData,C,p,DTemp( 1:( k+1 ) ) );
if CACC < CACCValue
CACC = CACCValue;
Local= q;
end
end
end
%Local
%CACC
%GlobalCACC
if GlobalCACC < CACC && k < MaxNumF
GlobalCACC = CACC;disp(['GlobalCACC=',num2str(GlobalCACC)]);
k = k + 1;
D( k ) = B( Local );disp(['Cutting point=',num2str(B(Local))]);
D( 1:k ) = sort( D( 1:k ) );
elseif k <= MaxNumF && k <= C && Local ~= 0
k = k + 1;
D( k ) = B( Local );
D( 1:k ) = sort( D( 1:k ) );
else
break;
end
end
DiscretizationSet( 1:k,p )= D( 1:k )';
% do the discretization process according to intervals in D.
DiscreData( :,p ) = DiscretWithInterval( OriginalData,C,p,D( 1:k ) );
end
end
function CACCValue = CACC_Evaluation( OriginalData, C, Feature, DiscretInterval )
%Paper: Kurgan, L. and Cios, K.J. (2002). CAIM Discretization Algorithm, IEEE Transactions of Knowledge and Data Engineering, 16(2): 145-153
% OriginalData is organized as F1,F2,...,Fm,C1,C2,...,Cn
M = size( OriginalData,1 );
k = length( DiscretInterval );
[ DiscretData,QuantaMatrix ] = DiscretWithInterval( OriginalData,C,Feature,DiscretInterval );
%Discrete the continuous data upon OriginalData
%QuantaMatrix
% Compute the value of CAIM via quanta matrix and equation (sum maxr/Mr)/n
RowQuantaMatrix = sum( QuantaMatrix,2 );
ColumnQuantaMatrix = sum( QuantaMatrix,1 );
CACCValue = 0 ;
for p = 1:C
for q = 1:k+1%for q = 1:k
if RowQuantaMatrix( p ) > 0 && ColumnQuantaMatrix( q ) > 0
CACCValue = CACCValue + ( QuantaMatrix( p,q ) )^2/( RowQuantaMatrix( p )*ColumnQuantaMatrix( q )) ;
end
end
end
CACCValue = M*( CACCValue-1 )/log(k+2);CACCValue = sqrt(CACCValue/(CACCValue+M));%CACCValue = M*( CACCValue-1 )/log2(k+1) ;
end
function [ DiscretData,QuantaMatrix ] = DiscretWithInterval( OriginalData,C,Column,DiscretInterval )
% C is the number of class variables.
M = size( OriginalData,1 );
k = length( DiscretInterval );
F = size( OriginalData,2 ) - C;
DiscretData = zeros( M,1 );
%Discrete the continuous data upon OriginalData
for p = 1:M
for t = 1:k
if OriginalData( p,Column ) <= DiscretInterval( t )
DiscretData( p ) = t-1;
break;
elseif OriginalData( p,Column ) > DiscretInterval( k )
DiscretData( p ) = k;
end
end
end
%OriginalData( :,Column )
%Quanta matrix
CState = C;
FState = length( DiscretInterval ) + 1;
QuantaMatrix = zeros( CState,FState );
for p = 1:M
for q = 1:C
if OriginalData( p,F+q ) == 1
Row = q;
Column = DiscretData( p )+1;
QuantaMatrix( Row,Column ) = QuantaMatrix( Row,Column ) + 1;
end
end
end
%QuantaMatrix
end接下来开始解释几处修改。
首先说测试代码对数据集的修改,这是因为网友Guangdi Li分享的CACC的代码实际上是面向多标记(multi-label)数据集写的(有关多标记学习可以搜索相关文献,超出了本篇文档的范围),要将它直接用到multi-class的数据集要将数据集的类别一维进行变换,函数CACC_Discretization的输入参数C在多标记数据集中指的是标记个数,如果放到multi-class数据集中就是指的类别个数,但有个问题是multi-class数据集的类别一般就存储成一维即可,比如测试代码中的contdata的第二列即为类别信息,共有三个类别,这时若想使用CACC_Discretization则要将每个类别均单独存储成一维,属于该类别的则该维为1反之为0,测试代码中以下三行即完成类别信息的这个转换(如果看不明白本段叙述,那就运行测试代码ControlCenter.m,对比contdata和OriginalData即可):
OriginalData(:,2) = (contdata(:,2)==1);
OriginalData(:,3) = (contdata(:,2)==2);
OriginalData(:,4) = (contdata(:,2)==3);然后解释对函数的几处修改:
第37行原来的代码是:
MaxNumF = floor(M/(3*C));针对原论文Table 2的Age数据集肯定是有问题的,因为M为数据集包含的数据个数,因此M=15,而C为类别个数即C=3,这时MaxNumF=1,而MaxNumF的意思是最多能对原来的连续属性切几刀(切一刀离散化为两个值,切两刀离散化为三个值,以此类推),这里我们不去探讨应该如何设置MaxNumF,我们的目标是复现Table 6中的结果,因为我们知道Table 6中将原连续属性离散化为5个值,即切4刀,因此这里简单将MaxNumF设为4,当然设大于4的值也没问题,自己可以尝试一下的。
第83行和第85行的代码就是为了显示Table 6中的Cutting point和Maximum cacc两列,因此就不作过多解释了,不需要显示的话把我添加的disp语句删掉就是了。
第118行原来的代码是:
for q = 1:k这里的k是在第106行得到的:k = length( DiscretInterval );,而DiscretInterval指的是切刀的位置,我刚才说了切一刀离散化为两个值,切两刀离散化为三个值,以此类推,因此切刀的位置比最终离散化的值的个数少一个;而第117行至第123行是在根据quanta matrix(详见原论文Table 1,即代码中的QuantaMatrix)计算CACC值:

第117行的for p = 1:C是可以遍历quantamatrix的所有行的,但第118行的for q = 1:k却无法遍历quantamatrix的所有列,原因前面说了:切刀的位置比最终离散化的值的个数少一个,因此这里应该修改为for q = 1:k+1,如此才能遍历quantamatrix。
第124行的修改最大,将原来的一条命令修改为了两条。第124行原来代码是:
CACCValue = M*( CACCValue-1 )/log2(k+1) ;为了更好的解释,先给出原论文中计算CACC的过程:

接下来开始解释。首先要弄明白,第117行至第123行实际计算的是:
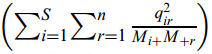
如果将第118行修改正确后这是没问题的,但第124行原来的代码“CACCValue = M*(CACCValue-1 )/log2(k+1) ;”可以很容易地看出实际是打算计算式(4)中的y’:
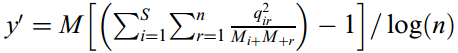
当然与y’也有一定的差异,因为原论文中的log是以e为底的而不是以2为底的。在上一篇《有关属性离散化算法CACC的补充说明》中我们说过了,若想得到Table 6的结果,这里除以的不能是log(n),而应该是log(n+1),到底谁对谁错我们不去争论,我们的目标是根据Table 2的数据集得到Table 6的离散化结果。因此,第124行原来的代码应该修改为“CACCValue =M*( CACCValue-1 )/log(k+2);”,这只是得到了y’,要想得到式(4)的CACC就需要再加一句“CACCValue = sqrt(CACCValue/(CACCValue+M));”,到此就修改完了。
运行测试代码ControlCenter.m,可以得到输出结果:
GlobalCACC=0.50446
Cutting point=10.5
GlobalCACC=0.64735
Cutting point=61.5
GlobalCACC=0.66117
Cutting point=28
GlobalCACC=0.72626
Cutting point=48.5
DiscretData =
0 1 0 0
0 1 0 0
0 1 0 0
1 0 1 0
1 0 1 0
1 0 1 0
2 0 0 1
2 0 0 1
2 0 0 1
3 0 1 0
3 0 1 0
3 0 1 0
4 1 0 0
4 1 0 0
4 1 0 0
DiscretizationSet1 =
10.5000
28.0000
48.5000
61.5000
观察输出结果可以发现,GlobalCACC和Cutting point与原论文Table 6一样,Table 2的连续年龄属性离散化为0/1/2/3/4五个值(离散化为0~4和离散化为1~5并没有区别,每个数字仅是代表一个符号而已,如果你愿意,也可以离散化为10/20/30/40/50也没问题的)。注意DiscretData的后三列,即为将原Table 2中的Target class转换后的类别,其中第二列指类别Care,第三列指类别Edu,第四列指类别Work。
综上所述,网友Guangdi Li分享的CACC的代码CACC_Discretization有三处错误:一是MaxNumF的设置有问题,本文档只是想复现Table 6的结果,简单将其设置为4,若想用到其它数据集,还须自己设置一个上限;二是第118行循环变量q的范围设置导致无法遍历quanta matrix矩阵;三是第124行实际只计算了y’而并不是CACC值,并且对数的底设成了2。除了这三处错误,还有一个大家在使用时要特别注意的就是multi-class的类别那一维展成多维,每一个类别值对应一维,这一点非常重要!