卷积神经网络可以分为离散卷积神经网络和连续卷积神经网络。
卷积是计算机视觉、图像处理、数字信号、人工智能等很多领域里常用的算法。比如,它可以在图像处理中用于钝化一幅图片,这时我们运用的是二维均值离散卷积。。卷积减弱了原来图片中的噪声,但也降低了图片的清晰度。
连续卷积公式:
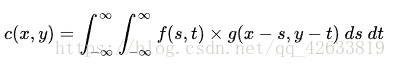
简单地说明:
c(x,y):神经网络输出矩阵;
f(s,t):权值矩阵,在一些书上叫做滤波器,或者掩膜;不同的滤波器不同的作用;
g(x-s,y-t):输入矩阵;
这式子的含义是:遍览从负无穷到正无穷的全部 s 和 t 值,把 g 在 (x-s, y-t) 上的值乘以 f 在 (s, t) 上的值之后再“加和”到一起(积分意义上),得到 c 在 (x, y) 上的值。
离散卷积神经网络:

公式的意思是,以(x,y)为中心,对输入矩阵距离中心(-s,-y)的值进行加权计算,然后将计算得到的值放在(x,y)的位置上,以此类推,计算下一个数。在这里我们把dertx,derty看作1。
卷积的过程大致如下:把权值矩阵的中心元素对准输入矩阵的第一个元素,把权值矩阵与输入矩阵重合的对应元素相乘相加,再把结果写入输出矩阵的第一个元素;然后把权值矩阵移动到输入元素的第二个元素,同样把所有重合元素相乘相加后写入对应的输出矩阵的第二个元素;重复这样的操作直到权值矩阵移过了所有的输入矩阵元素。权值矩阵的值事实上是每一次求和时输入元素的权,即矩阵中每个元素的周围元素对它影响的程度,加权求和即将这种影响施加到了正在计算的元素。可以想见,如果权值矩阵只有中心元素为1,其他元素都是零,则卷积之后输出矩阵与输入矩阵是等同的。
注意:
1.F 是上下左右翻转后再与 G 对准的。因为卷积公式中 F(s, t) 乘上的是 G(x-s, y-t) 。比如 F(-1, -1) 乘上的是 G(7, 7) ;
2,.如果 F 的所有值之和不等于 1.0,则 C 值有可能不落在 [0, 255] 区间内,那就不是一个合法的图像灰度值。所以如果需要让结果是一幅图像,就得将 F 归一化——令它的所有位置之和等于 1.0 ;
3.对于 G 边缘上的点,有可能它的周围位置超出了图像边缘。此时可以把图像边缘之外的值当做 0 。或者只计算其周围都不超边缘的点的 C 。这样计算出来的图像就比原图像小一些。在上例中是小了一圈,如果 F 覆盖范围更大,那么小的圈数更多。
不同的滤波器有不同的作用,如果随机产生一个权值矩阵,那么会有不同的效果,但是,不能对应每一个功能设计一个滤波器,这样的工作量就有点大了,所以,人们不经会想,如果不是由人来设计一个滤波器,而是从一个随机滤波器开始,根据某种目标、用某种方法去逐渐调整它,直到它接近我们想要的样子,可行么?这就是卷积神经网络(Convolutional Neural Network, CNN)的思想了。可调整的滤波器是 CNN 的“卷积”那部分;如何调整滤波器则是 CNN 的“神经网络”那部分。
要达到这个目的,首先准备一个从目标函数采样的包含若干“输入-输出对”的集合——训练集。把训练集的输入送给神经网络,得到的输出肯定不是正确的输出。因为一开始这个神经网络的行为是随机的。
把一个训练样本输入给神经网络,计算输出与目标输出的(向量)差的模平方(自己与自己的内积)。再把全部 n 个样本的差的模平方求平均,得到 e :
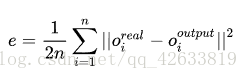
e 称为均方误差 mse 。全部输出向量和目标输出向量之间的距离(差的模)越小,则 e 越小。e 越小则神经网络的行为与想要的行为越接近。我们目标是使 e 变小。在这里 e 可以看做是全体权值和偏置值的一个函数。这就成为了一个无约束优化问题。如果能找到一个全局最小点,e 值在可接受的范围内,就可以认为这个神经网络训练好了。它能够很好地拟合目标函数。这里待优化的函数也可以是 mse 外的其他函数,统称 Cost Function,都可以用 e 表示。
在 卷积神经网络 中,这样的滤波器层叫做卷积层。一个卷积层可以有多个滤波器,每一个叫做一个 channel 。图像是二维信号。信号也可以是其他维度的,比如一维、三维乃至更高维度。那么滤波器相应的也有各种维度。回到二维图像的例子,实际上一个卷积层面对的是多个 channel 的 “一摞” 二维图像。