上一篇博客中我们已经完成了hdfs的部署,现在我们开始部署yarn了。
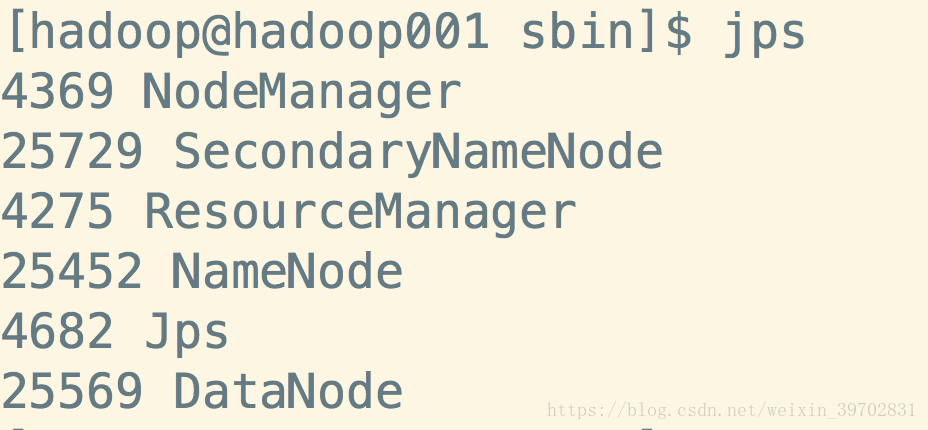
我们先使用jps命令来查看下现在与java相关的进程:

这里NameNode以后简称为NN,DataNode简称为DN,而SecondaryNameNodel简称为SNN。
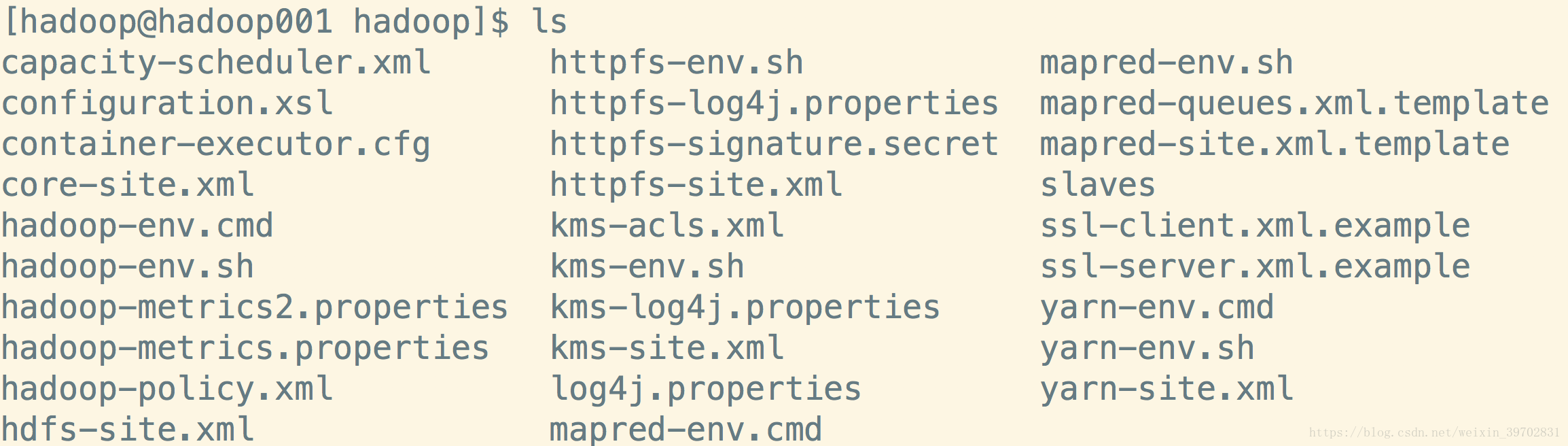
我们先切换到hadoop目录下的etc文件夹下的hadoop文件夹,在这里我们可以看到有这些文件
我们先来配置yarn-site.xml这个文件,我们需要配置的参数如下:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

保存退出即可
接着我们来配置mapred-site.xml这个配置文件,但是细心的小伙伴会发现在etc/hadoop下是没有这个文件的,只有mapred-site.xml.temmapred-site.xml.template这个文件的,说明一下这个是mapred-site.xml的一个副本,我们要做的就是将其cp一份为mapred-stie.xml,然后在这个cp的副本中修改配置参数可以了

要配置的参数为:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

同样是保存退出就好了
最后我们切换到hadoop下的sbin目录,使用start-yarn.sh这个shell脚本就可以启动yarn了

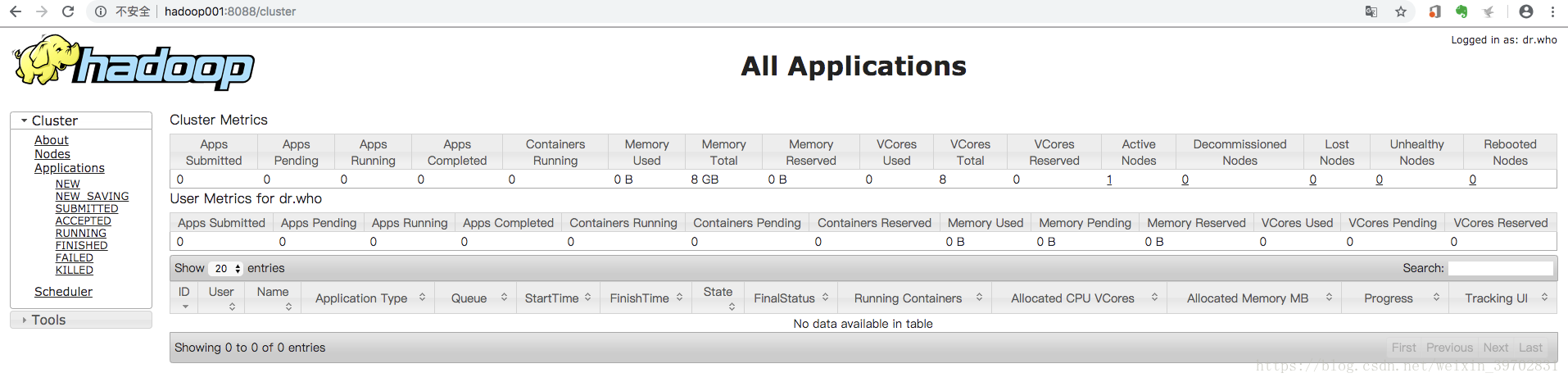
然后我们使用jps命令,我们就会发现进程多了两个,分别是NodeManager和ResourceManager。
而yarn这个进程的端口号是8088,我们可以通过这个端口号来查看yarn的web界面来了解yarn上面的app的情况