1,Hadoop的解释
广义上的:以hadoop软件为主的生态圈,包括什么:sqoop,hive,Mahout等等
狭义上的:就是hadoop三剑客,hdfs,mapreduce,yarn,这仨
2,apache项目
说到hadoop不能不提apache基金会,这个基金会就牛逼囉,有非常多的开源项目,包括我们的hadoop,spark,hive,flink等等。而他们的网址都很统一的,就是xxx.apache.org,比如:hadoop.apache.org,spark.apache.org等等
3,hadoop软件
hadoop又分为三个阶段或者我们说三个版本,分别是;
hadoop 1.x
hadoop 2.x
hadoop 3.x
现在的最新版本是hadoop 3.x版本,但是在生产上我们还是使用hadoop 2.x这个版本,虽然hadoop现在是3.x和2.x都在同时更新,但新版本还不知道有什么坑,企业就很少这样去躺坑了。
而接下来的课程当中我们都使用的是hadoop-2.6.0-cdh5.7.0这个版本,这里可能有人问为什么是cdh版本呢,我们后面细讲。
首先,我们先了解下hadoop那三剑客
hdfs 用于存储大数据的分布式文件系统,说得通俗一点就是,这个货在hadoop当中是充当存储的角色的
mapreduce 分布式计算框架,这个货就是用于计算的,分为map端和reduce端,后面我们再详细地了解其内在的功能
yarn 资源调度器,其负责资源和作业的调度管理,毕竟几十台机子,数据和计算的节点也不一定在同一个地方,所以需要协调执行的过程。
现在我们说下为什么我们使用cdh版本的,故事是这样的:apache将hadoop开源后就不理了,有时候有一些bug则要等到下一个版本才能解决,cdh这个商业公司就将apache开源的hadoop源码拿过来,解决掉一些bug添加了一些新功能,再说成是他自己的版本就行了。所以说其实cdh的hadoop和apache的hadoop也没有什么区别的,只是我们生产上使用cdh的版本而已。
后面我将简单地介绍一下hadoop中的hdfs地配置。
1,创建一个用于管理hadoop的用户
在生产当中,我们都是专项专管的,mysql的管理有一个mysqladmin这个的用户,而hadoop也有一个专门的用户
用root用户创建一个hadoop用户,useradd hadoop,并在这个用户的家目录下创建几个文件夹,app,source,software,data
切换到app文件夹下使用wget命令来下载hadoop的二进制包,
wget http://archive-primary.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz
然后解压 tar -xzvf hadoop2.6.0-cdh5.7.0.tar.gz
接着配置jdk1.7,之前我们配置了jdk1.8的,但这里可能版本问题,我们使用jdk1.7就行了,也是配置到环境变量里面,至于是全局的还是个人的都可以,但是要注意和之前的jdk1.8的兼容问题,JAVA_HOME=/usr/java/jdk1.7xxx的了。
2,修改hadoop的配置文件
然后到/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop这个目录下,把hadoop-env.sh,core-site.xml和hdfs-site.xml这三个配置文件修改了,具体如下:
hadoop-env.sh这个文件
export JAVA_HOME=你java的安装目录,这里就是告诉hadoop你的java在哪里
export HADOOP_PREFIX=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0,这里是明确hadoop的安装目录,其实也可以不写的
core-site.xml这个文件
将<configuraiong></configuration>这个删了,把我这个copy上去就好了
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:9000</value>
</property>
</configuration>
注意这里的hadoop001是我的主机hostname,你要把你的hostname写上去,至于端口号就不用改了
hdfs-site.xml这个文件
将<configuraiong></configuration>这个删了,把我这个copy上去就好了
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
就是说将副本系数标志成1。
配置hadoop的环境变量,一般就在hadoop这个用户的个人环境变量文件中配就行了。
3,ssh无密码登陆
如果是初次使用的话就直接在hadoop的家目录上输入命令:ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa,如果不是的话就rm -rf .ssh 将这个文件夹删除再输入前面的命令。然后 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys,将你本机的公钥放到 ~/.ssh/authorized_keys这个文件里面,在本机ssh你的本机,如果可以无密码登陆就ok了
这个.ssh文件夹下的情况:
total 12
-rw-rw-r-- 1 hadoop hadoop 606 Sep 19 23:16 authorized_keys
-rw------- 1 hadoop hadoop 668 Sep 19 23:16 id_dsa
-rw-r--r-- 1 hadoop hadoop 606 Sep 19 23:16 id_dsa.pub
4,初始化hdfs
切换到/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/bin下,输入命令hdfs namenode -format来初始化你的namenode节点。
内容非常多我就截取了开始的一部分
5,启动hdfs的进程
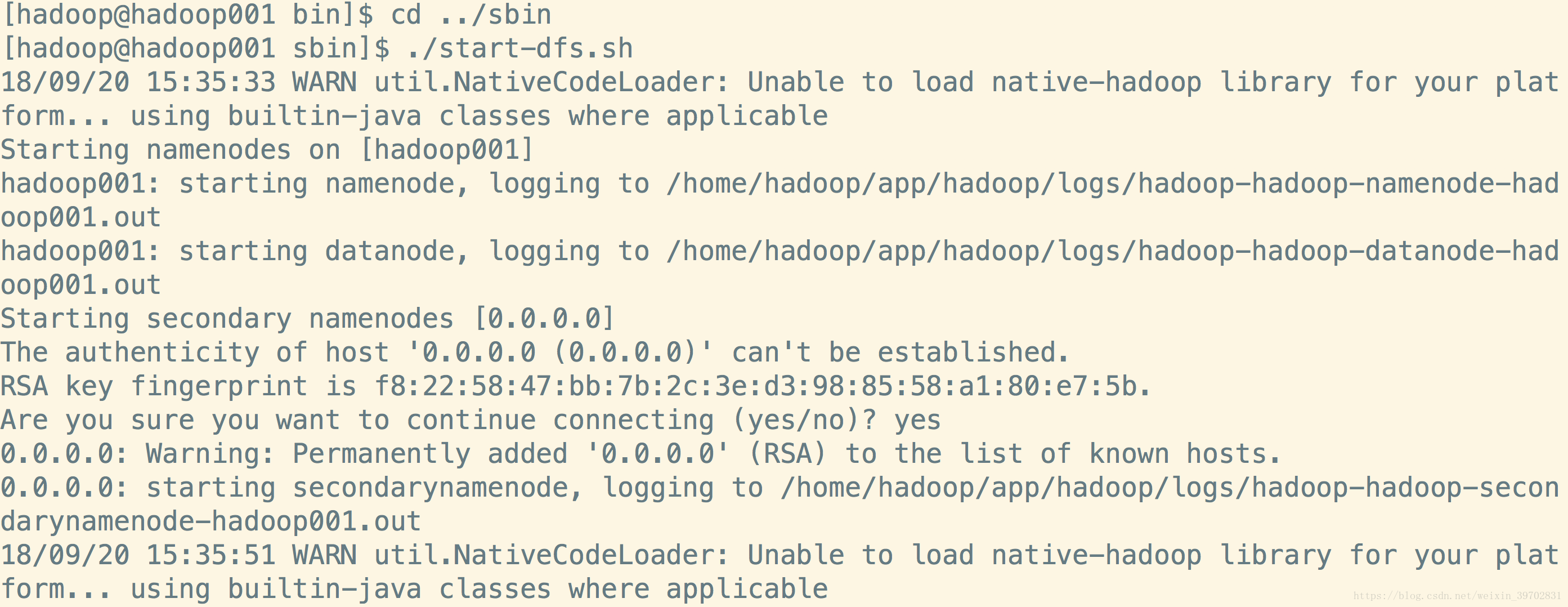
切换到/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/sbin下,输入命令./start-dfs.sh,看到这样的输入就是对的了:
注意图片中我已经将hadoop-2.6.0-cdh5.7.0重命名为hadoop了,所以路径名称上有所不同
然后输入命令jps来查看进程,这个查看进程和ps -ef有什么区别呢?jps是用来查看与java有关的进程的,你要是用ps -ef 也是可以查看到hadoop相关的进程的,就是太多了不好找

这样就好了,然后我们可以在web浏览器中输入主机的ip或者hostname加端口号50070来查看hadoop的overview

完成了一个简单的hdfs的配置,后面我们将会详细地了解每一个配置文件内容参数,以及配置yarn和maoreduce。