版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/xinzhi8/article/details/77427345
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
论文下载地址:https://arxiv.org/abs/1506.01497

理解:
以前用Selective search生成建议框,一张图片根据像素,纹理等特征生成n多大小不一建议框,然后对框一个一个分类。这里是有弊端的,第一,一张图片产生成千上万建议框是非常耗时间的。第二,每个建议框都要分m类,更加耗时。
如下图:

RPN(Region Proposal Network ):RPN是一个全卷积网络,在每个位置同时预测目标边界和objectness得分。RPN是端到端训练的,生成高质量区域建议框,用于Fast R-CNN来检测。通过一种简单的交替运行优化方法,RPN和Fast R-CNN可以在训练时共享卷积特征。他的特点是将生成的建议框一起进行分类,而不是一个个分类,大大节省建议框的生成时间。

在目标检测中取得的进步都是由区域建议方法和基于区域的卷积神经网络(R-CNN)取得的成功来推动的。基于区域的CNN在刚提出时在计算上消耗很大,幸好后来这个消耗通过建议框之间共享卷积大大降低了。最近的Fast R-CNN用非常深的网络实现了近实时检测的速率,注意它忽略了生成区域建议框的时间。现在,建议框是最先进的检测系统中的计算瓶颈。
区域建议方法典型地依赖于消耗小的特征和经济的获取方案。选择性搜索(Selective Search, SS)是最流行的方法之一,它基于设计好的低级特征贪心地融合超级像素。与高效检测网络相比,SS要慢一个数量级,Fast R-CNN利用了GPU,而区域建议方法是在CPU上实现的,这个运行时间的比较是不公平的。一种明显提速生成建议框的方法是在GPU上实现它,这是一种工程上很有效的解决方案。本文中,我们改变了算法——用深度网络计算建议框——这是一种简洁有效的解决方案,建议框计算几乎不会给检测网络的计算带来消耗。为了这个目的,我们介绍新颖的区域建议网(Region Proposal Networks, RPN),它与最先进的目标检测网络共享卷积层。在测试时,通过共享卷积,计算建议框的边际成本是很小的 。我们观察发现,基于区域的检测器例如Fast R-CNN使用的卷积(conv)特征映射,同样可以用于生成区域建议。我们紧接着这些卷积特征增加两个额外的卷积层,构造RPN:第一个层把每个卷积映射位置编码为一个短的(例如256-d)特征向量,第二个层在每个卷积映射位置,输出这个位置上多种尺度和长宽比的k个区域建议的objectness得分和回归边界(k=9是典型值)。
区域建议方法典型地依赖于消耗小的特征和经济的获取方案。选择性搜索(Selective Search, SS)是最流行的方法之一,它基于设计好的低级特征贪心地融合超级像素。与高效检测网络相比,SS要慢一个数量级,Fast R-CNN利用了GPU,而区域建议方法是在CPU上实现的,这个运行时间的比较是不公平的。一种明显提速生成建议框的方法是在GPU上实现它,这是一种工程上很有效的解决方案。本文中,我们改变了算法——用深度网络计算建议框——这是一种简洁有效的解决方案,建议框计算几乎不会给检测网络的计算带来消耗。为了这个目的,我们介绍新颖的区域建议网(Region Proposal Networks, RPN),它与最先进的目标检测网络共享卷积层。在测试时,通过共享卷积,计算建议框的边际成本是很小的 。我们观察发现,基于区域的检测器例如Fast R-CNN使用的卷积(conv)特征映射,同样可以用于生成区域建议。我们紧接着这些卷积特征增加两个额外的卷积层,构造RPN:第一个层把每个卷积映射位置编码为一个短的(例如256-d)特征向量,第二个层在每个卷积映射位置,输出这个位置上多种尺度和长宽比的k个区域建议的objectness得分和回归边界(k=9是典型值)。
我们的RPN是一种全卷积网络(fully-convolutional network, FCN),可以针对生成检测建议框的任务端到端地训练。为了统一RPN和Fast R-CNN[5]目标检测网络,我们提出一种简单的训练方案,即保持建议框固定,微调区域建议和微调目标检测之间交替进行。这个方案收敛很快,最后形成可让两个任务共享卷积特征的标准网络。 我们在PASCAL VOC检测标准集上评估我们的方法, fast R-CNN结合RPN的检测准确率超过了作为强大基准的fast R-CNN结合SS的方法。同时,我们的方法没有了SS测试时的计算负担,对于生成建议框的有效运行时间只有10毫秒。利用[19]中网络非常深的深度模型,我们的检测方法在GPU上依然有5fps的帧率(包括所有步骤),因此就速度和准确率(PASCAL VOC 2007上是73.2%mAP,PASCAL VOC 2012上是70.4%)而言,这是一个实用的目标检测系统。

RPN过程:
一张图片进来,经过卷积核生成特征图片feature map,特征图上每个点产生k个建议框,对建议框做Rol pooling到相同的固定大小,最后分类。
如下图:

建议框的产生原理:
一张图片经过卷积核产生特征图,那么特征图上的每个点应该对应原始图的某块区域,比如原始图pooling了4次,那么特征图的每个点对应着原始图16x16区域(2x2x2x2=16),既然一个点对应一个区域,那么区域是有大小方向的,论文中给出的比例是 1:1 , 1:2 , 2:1,大小是:128,256,和512。那么每个点对应的区域是9种情况,则一张50x50的特征图有50x50x9种框。
这就是RPN的优势之处,在卷积核之后产生建议框。
为什么不在卷积核之前产生建议框呢?采用RPN,则一张图片经过一次卷积网络产生特征图,在特征图上生成建议框,再分类。假设在卷积之前就做好50x50x9种框,则要有50x50x9张图片经过卷积网络产生特征图,再分类。RPN的计算速度明显快很多。而且RPN的框是在卷积核之后产生的,则这些建议框共享一个神经网络,而不是每个框对应一个神经网络。
图例:


ROL pooling:
传统的神经网络是通过卷积层链接全连接层,卷积核的大小是固定的,为什么是固定的,因为卷积层是通过权重矩阵链接全连接层的,如果权重矩阵大小变化了,反向传播跟新梯度损失就没法跟新了。那么RPN产生的9种尺度不同的建议框经过卷积层一定会产生不同的特征图,这样就不能链接全连接层了。
这时候便需要ROL pooling,通过设置滑动窗口的大小与步长肯定是能够是不同尺寸的图固定成同样大小的

损失函数
为了训练RPN,我们给每个anchor分配一个
二进制的标签
。我们分配
正标签
给两类anchor:
(i)与某个ground truth(GT)包围盒有最高的IoU(Intersection-over-Union,交集并集之比)重叠的anchor(也许不到0.7)
(ii)与任意GT包围盒有大于0.7的IoU交叠的anchor。注意到一个GT包围盒可能分配正标签给多个anchor。我们分配
负标签
给与所有GT包围盒的IoU比率都低于0.3的anchor。非正非负的anchor对训练目标没有任何作用。
有了这些定义,我们遵循Fast R-CNN[5]中的多任务损失,最小化目标函数。我们对一个图像的损失函数定义为

这里,i是一个mini-batch中anchor的索引,Pi是anchor i是目标的预测概率。如果anchor为正,GT标签Pi* 就是1,如果anchor为负,Pi* 就是0。ti是一个向量,表示预测的包围盒的4个参数化坐标,ti* 是与正anchor对应的GT包围盒的坐标向量。 分类损失*Lcls是两个类别的对数损失
有了这些定义,我们遵循Fast R-CNN[5]中的多任务损失,最小化目标函数。我们对一个图像的损失函数定义为
这里,i是一个mini-batch中anchor的索引,Pi是anchor i是目标的预测概率。如果anchor为正,GT标签Pi* 就是1,如果anchor为负,Pi* 就是0。ti是一个向量,表示预测的包围盒的4个参数化坐标,ti* 是与正anchor对应的GT包围盒的坐标向量。 分类损失*Lcls是两个类别的对数损失
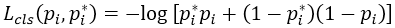 。对于
回归损失*,我们用
。对于
回归损失*,我们用
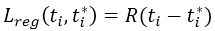 来计算,其中R是[5]中定义的鲁棒的损失函数(smooth L1)。
来计算,其中R是[5]中定义的鲁棒的损失函数(smooth L1)。
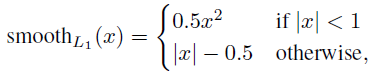
Pi* Lreg这一项意味着只有正anchor(Pi* =1)才有回归损失,其他情况就没有(Pi* =0)。cls层和reg层的输出分别由{pi}和{ti}组成,这两项分别由Ncls和Nreg以及一个平衡权重λ归一化(早期实现及公开的代码中,λ=10,cls项的归一化值为mini-batch的大小,即Ncls=256,reg项的归一化值为anchor位置的数量,即Nreg~2,400,这样cls和reg项差不多是等权重的。
对于回归,我们学习[6]采用4个坐标:
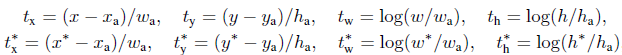
x,y,w,h指的是包围盒中心的(x, y)坐标、宽、高。变量x,xa,x*分别指预测的包围盒、anchor的包围盒、GT的包围盒(对y,w,h也是一样)的x坐标。可以理解为从anchor包围盒到附近的GT包围盒的包围盒回归。
无论如何,我们用了一种与之前的基于特征映射的方法[7, 5]不同的方法实现了包围盒算法。在[7, 5]中,包围盒回归在从任意大小的区域中pooling到的特征上执行,回归权重是所有不同大小的区域共享的。在我们的方法中,用于回归的特征在特征映射中具有相同的空间大小(nxn)。考虑到各种不同的大小,需要学习一系列k个包围盒回归量。每一个回归量对应于一个尺度和长宽比,k个回归量之间不共享权重。因此,即使特征具有固定的尺寸/尺度,预测各种尺寸的包围盒仍然是可能的。