使用python验证码识别来爆破网站后台
在我的上一篇博客中,讲解了我用python来识别验证码的原理,对于有些人来说,他可能并不想知道验证码识别的原理,只是想寻找方法去识别验证码从而使用脚本登录网站或者爆破网站的密码。
这几天我把我之前的代码重写了一下(之前写的真的很乱,一般人都看不下去),现在只需要改一下配置文件,你就可以定制自己的目标网站的验证码识别。
1. 运行环境为python3
2. 适用于验证码是通过get请求图片的和噪声为点,线的网站

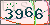
3. 网站验证码是+-*运算的暂不支持,但是逻辑是一样的,可以通过改我的源代码来实现这个功能
下载了代码后,代码目录为
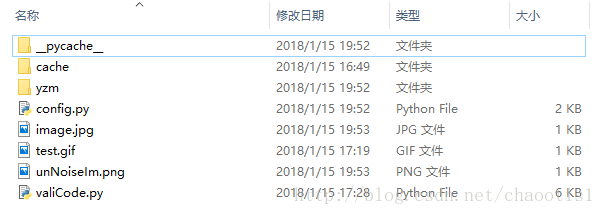
- pycache是python运行产生的运行文件,删了也可以在运行的时候自己生成
yzm文件夹是存放识别样本的目录,如果文件里没有自行建立,目录结构为
里面的文件夹以要识别的元素命名,比如我实验的网站验证码是由 0-9数字组成,因此我的文件夹以0-9命名,如果目标网站有a-z,大家也要建立对应的文件夹。文件夹下面放用以识别的样本。如 0文件夹下面
(如何得到样本我将在后面写出,使用这个代码不需要图片识别方面的知识)config.py是程序的配置文件,定制图像识别只需要更改这个文件即可,不需要改源码。代码如下。


class Config:
#验证码的url
valiCodeUrl = ''
#验证码提交地址url
postUrl = ''
#登录页面的url
hostUrl = ''
#搜索噪声的范围,如以3*3的大小来搜索整张图
noiseRange = 3
#消除噪声的标准,如在3*3大小内,若非白色的点小于2个就清除
noiseClear = 2 #去噪后的图像保存地址,观察图片调整上面参数
unNoiseIm = './unNoiseIm.png'
#获取到的验证码图片,便于比对正确性
valiCodeIm = './image.jpg'
#验证码包含的字符
iconset = ['0','1','2','3','4','5','6','7','8','9']
#需要识别的验证码的每个内容的横坐标,使用画图工具判断
letters = [(4,13),(14,22),(23,33),(34,44)]
#[(7,15),(16,24),(25,33),(35,43)]
#是否训练样本
isTrain = False
#相似度需要达到多少才算合格
qualified = 0.94
#训练集是否初始化
initCode = Falseimage.jpg是每一次程序运行时获取的验证码图片,方便增加样本时比对是否正确识别,由代码自动生成
unNoiseIm.png 是去除噪声并且变成黑白后的验证码(噪声是验证码上面的与验证码内容无关的点,线之类的用以干扰验证码识别的东西)
- valiCode.py 是程序的主文件,识别样本准备好了之后大家可以把自己的代码放在这个目录下,然后
from valiCode import ValiCode,再实例化对象a = ValiCode()
yzm=a.compare()
a.compare()返回的是验证码的识别结果
这样验证码就得到了。
在使用过程中可能会遇到报错,提示缺少某库,这时候大家把相应的库pip一下就好了,可能python3会遇到PIL库pip不了的情况,如果是python3.6的话大家可以使用我代码文件夹里的Pillow-5.0.0-cp36….whl,其他版本可以自己到网上下载。
介绍完目录,现在来介绍使用方法
- 下载好代码之后,解压到一个地方
然后打开文件夹
进入valiCode-ocr下的valiCode文件夹


在此目录下新建一个文件夹,名字叫 yzm,再yzm文件夹里新建 以你要识别的验证码元素名 命名的文件夹,如我要识别的验证码只有0-9,如果有a-z,可以自行建立,配置文件里的iconset = [‘0’,’1’,’2’,’3’,’4’,’5’,’6’,’7’,’8’,’9’]也要随之改变
2. 建立好目录之后打开 config.py文件
class Config:
#验证码的url
valiCodeUrl = ''
#验证码提交地址url
postUrl = ''
#登录页面的url
hostUrl = ''
#搜索噪声的范围,如以3*3的大小来搜索整张图
noiseRange = 3
#消除噪声的标准,如在3*3大小内,若非白色的点小于2个就清除
noiseClear = 2 #去噪后的图像保存地址,观察图片调整上面参数
unNoiseIm = './unNoiseIm.png'
#获取到的验证码图片,便于比对正确性
valiCodeIm = './image.jpg'
#验证码包含的字符
iconset = ['0','1','2','3','4','5','6','7','8','9']
#需要识别的验证码的每个内容的横坐标,使用画图工具判断
letters = [(4,13),(14,22),(23,33),(34,44)]
#[(7,15),(16,24),(25,33),(35,43)]
#是否训练样本
isTrain = False
#相似度需要达到多少才算合格
qualified = 0.94
#训练集是否初始化
initCode = False填入你想识别验证码网站的url(用开发者工具抓取)
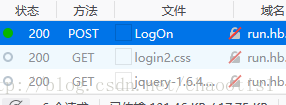
- valiCodeUrl,打开开发者工具,切换到网络选项,刷新一下验证码,会出现一个验证证码的url,把它填在这里即可
- postUrl ,随便填入用户名,密码和验证码然后点击登录,出现在开发者工具里的 标有post的就是url
hostUrl ,就是浏览器上的url
下载一张验证码图片,用画图工具打开
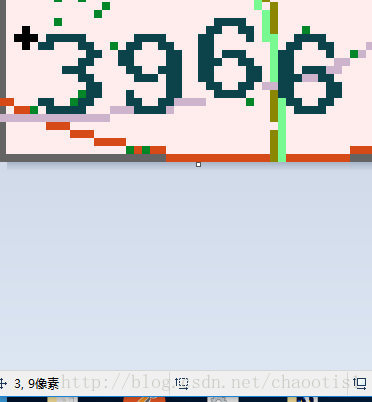
确定验证码里每个元素的横坐标区间,
如上图第一个元素的横坐标区间为3,13,以此测出所有元素的横坐标区间然后填入letters
格式 letters = [(3,13),(14,22),(23,33),(34,44)]其他的先不变,让isTrain = True,initCode = True
- 运行valiCode.py,
这时候程序主目录下就会出现,一些以时间戳命名的gif文件
人工识别它 并把它放在yzm目录下对应的文件夹里,如果识别不清楚,看看程序主目录下的验证码源图片image.jpg和去噪后的图片unNoiseIm.png是否清楚,不清楚的话,就去改config.py里的noiseRange = 3,noiseClear = 2的值(noiseRange/noiseClear的值越小,清楚效果越强,太小了,图片可能都看不见了),再运行程序直到生成的unNoiseIm满意。
反复执行上面的操作直到yzm文件下的每个文件夹都至少有一张图片,
然后把initCode = False,再执行程序



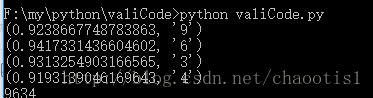
左边的数字代表相似度,右边代表识别出来的数字,相似度>qualified 的就会跳过,可以手动修改qualified
产生的图片会出现在yzm目录下
人工判断识别是否正确,然后把对应的图片放入对应的文件夹中
反复执行这个操作,知道所有识别都大于qualified ,或者你觉得识别出来的结果差不多都是对的(如果验证码的噪声比较复杂可能需要的时间比较长),样本准备就完成了
- 最后把isTrain=False,就可以在自己的程序中调用这个程序了。
我的实验结果(为了证明代码的通用性 这个网站,并不是我最初写代码时的目标网站)
原来的验证码

去噪后的
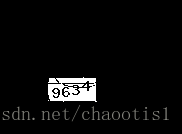
识别结果
大家如果有什么好的建议和想法,可以和我交流一下,让我能改进代码