


selenium是可以通过pycharm自动导入模块的
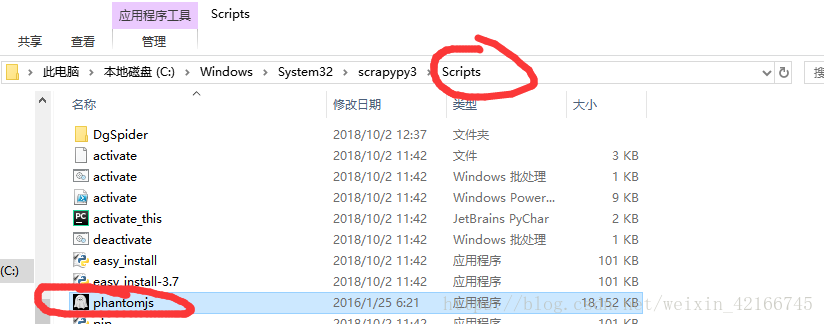
而PhantomJS则需要去官网下载http://phantomjs.org/download.html
然后把文件复制到scripts目录下,在把下载的路径设置成环境变量就可以使用了
面试的时候直接说自己会自动化测试工具、无头浏览器去爬取动态加载页面、js分页技术、ajax记载技术。Great
下面介绍用法(可能不全,可自行百度)以及附上代码:
当你出现ResourceWarning:unclosed<socket.socketfd=632,family=AddressFamily.AF_INETtype=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 54123), raddr=('127.0.0.1', 53477)>return self._request(command_info[0], url, body=data)
这种报错的时候没事,只是使用版本不同,程序还是照样执行




# #导入webdeiver APT,可以调用浏览器和操作页面
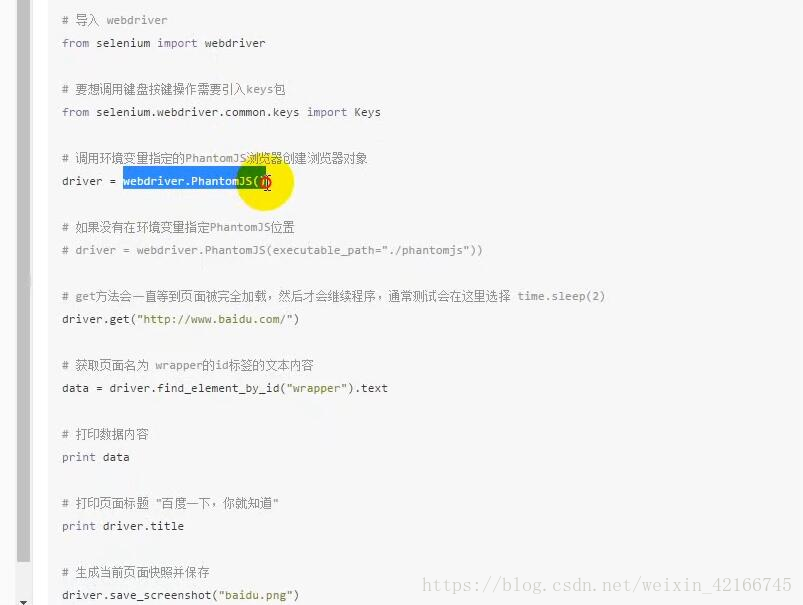
# from selenium import webdriver
# #导入keys,可以使用操作键盘、标签、鼠标
# from selenium.webdriver.common.keys import Keys
# #调用浏览器 selenium是不带浏览器的
# driver=webdriver.PhantomJS()
#
# driver.get('http://www.baidu.com/')
# #页面截图
# driver.save_screenshot('baidu.png')
#
# driver.find_element_by_id('kw').send_keys(u'美女')
#
# driver.save_screenshot('baidu.png')
#
# #获取百度源码:dirver.page_source
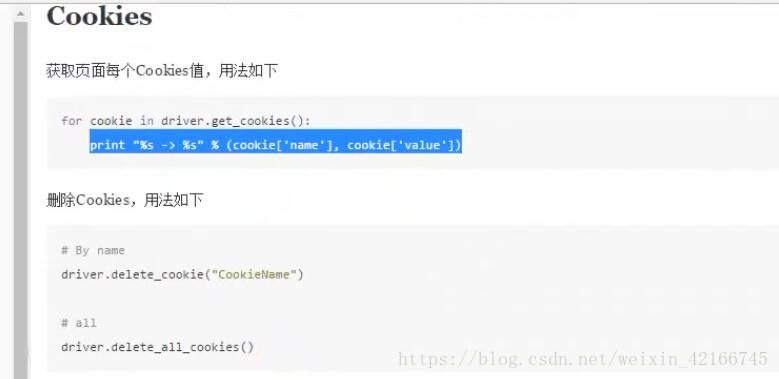
# #获取cookie值:dirver.get_cookies()
# #driver.find_element_by_id('kw').send_keys(Keys.RETURN)斗鱼为例,这里用到了测试模块,成功执行的话会返回一个OK,斗鱼是js分页技术:
#无头浏览器去爬取动态加载页面
#调用测试化模块,参数值是固定的
import unittest
#导入webdeiver APT,可以调用浏览器和操作页面
from selenium import webdriver
#用BeautifulSoup解析模块
from bs4 import BeautifulSoup as bs
class douyu(unittest.TestCase):
# 初始化方法,必须是setUp()
def setUp(self):
# 调用浏览器 selenium是不带浏览器的
self.driver = webdriver.PhantomJS()
self.num = 0
self.count = 0
# 测试方法必须有test字样开头
def testDouyu(self):
self.driver.get("https://www.douyu.com/directory/all")
while True:
soup = bs(self.driver.page_source, "lxml")
# 房间名, 返回列表
names = soup.find_all("h3", {"class" : "ellipsis"})
# 观众人数, 返回列表
numbers = soup.find_all("span", {"class" :"dy-num fr"})
#主播ID,返回列表
ids=soup.find_all('span',{'class':'dy-name ellipsis fl'})
# zip(names, numbers) 将name和number这两个列表合并为一个元组 : [(1, 2), (3, 4)...]
for name, number,id in zip(names, numbers,ids):
print(u"主播: -" + id.get_text().strip()+u"-\t观众人数: -" + number.get_text().strip() + u"-\t房间名: " + name.get_text().strip())
x=number.get_text().strip()
y=x.replace('万','').strip()
self.num += 1
self.count += int(float(y))*10000
# 如果在页面源码里找到"下一页"为隐藏的标签,就退出循环
if self.driver.page_source.find("shark-pager-disable-next") != -1:
break
# 一直点击下一页
self.driver.find_element_by_class_name("shark-pager-next").click()
# 测试结束执行的方法
def tearDown(self):
# 退出PhantomJS()浏览器
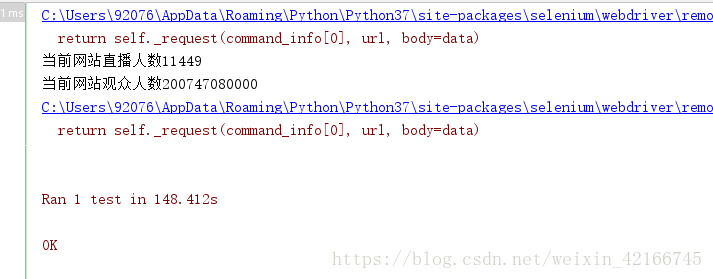
print ("当前网站直播人数" + str(self.num))
print ("当前网站观众人数" + str(self.count))
self.driver.quit()
if __name__ == "__main__":
# 启动测试模块
unittest.main()
爬取结果如下:

豆瓣的ajax加载技术:
from selenium import webdriver
import time
driver = webdriver.PhantomJS()
driver.get("https://movie.douban.com/typerank?type_name=剧情&type=11&interval_id=100:90&action=")
time.sleep(3)
# 向下滚动10000像素
js = "document.body.scrollTop=10000"
#js="var q=document.documentElement.scrollTop=10000"
#查看页面快照
driver.save_screenshot("douban.png")
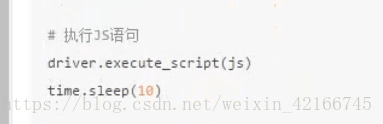
# 执行JS语句
driver.execute_script(js)
time.sleep(10)
#查看页面快照
driver.save_screenshot("newdouban.png")
driver.quit()