一、程序分析,对程序中的四个函数做简要说明
1.1 读文件到缓冲区
def process_file(dst): # 读文件到缓冲区 try: # 打开文件 file = open(dst, 'r') # dst为文本的目录路径 except IOError as s: print (s) return None try: # 读文件到缓冲区 bvffer = file.read() except: print ("Read File Error!") return None file.close() return bvffer
1.2 处理缓冲区,统计每个单词的频率
def process_buffer(bvffer): if bvffer: word_freq = {} # 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq # 将文本内容都改为小写 bvffer = bvffer.lower() #去除文本中的中英文标点符号 for ch in '“‘!;,.?”': bvffer = bvffer.replace(ch, " ") # strip()删除空白符(包括'/n', '/r','/t');split()以空格分割字符串 words = bvffer.strip().split() for word in words: word_freq[word] = word_freq.get(word, 0) + 1 return word_freq
1.3 输出词频前十的单词
def output_result(word_freq): if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: # 输出 Top 10 的单词 print (item)
1.4 主函数,将前面的函数进行调用封装
if __name__ == "__main__": import argparse dst = "D:\work\wordcount\Gone_with_the_wind.txt" bvffer = process_file(dst) word_freq = process_buffer(bvffer) output_result(word_freq)
二、代码风格说明
1.格式错误解决
在编译时会出现这样的错误:IndentationError:expected an indented block。这说明此处需要缩进,需要要在出现错误的那一行,按空格键缩进。另外,还有一个错误是TabError: inconsistent use of tabs and spaces in indentation。这个错误是在缩进时婚姻了Tab和空额导致的,需要统一。
三、程序运行命令、运行结果截图
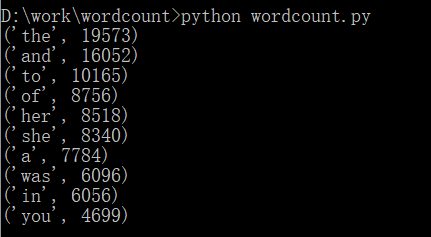
1.Gone_with_the_wind
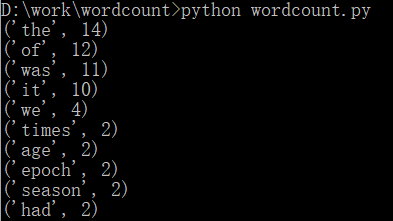
2.A_Tale_of_Two_Cities
四、性能分析结果及改进
ncalls:表示函数调用的次数;
tottime:表示指定函数的总的运行时间,除掉函数中调用子函数的运行时间;
percall:(第一个percall)等于 tottime/ncalls;
cumtime:表示该函数及其所有子函数的调用运行的时间,即函数开始调用到返回的时间;
percall:(第二个percall)即函数运行一次的平均时间,等于 cumtime/ncalls;
filename:lineno(function):每个函数调用的具体信息;