版权声明:转载请注明出处,谢谢。 https://blog.csdn.net/weixin_40413816/article/details/82965949
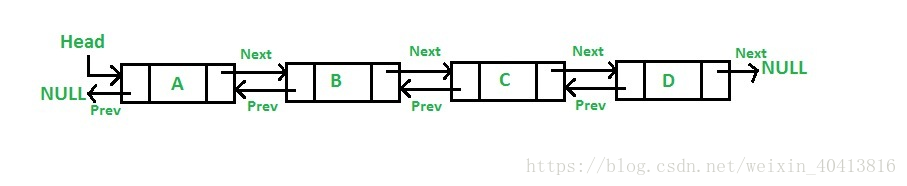
如图所示 LinkedList 底层是基于双向链表实现的,也是实现了 List 接口,所以也拥有 List 的一些特点(JDK1.7/8 之后取消了循环,修改为双向链表)。
新增方法
public boolean add(E e) {
linkLast(e);
return true;
}
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
可见每次插入都是移动指针,和 ArrayList 的拷贝数组来说效率要高上不少。
查询方法
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
上述代码,利用了双向链表的特性,如果index离链表头比较近,就从节点头部遍历。否则就从节点尾部开始遍历。使用空间(双向链表)来换取时间。
-
node()会以O(n/2)的性能去获取一个结点。
-
如果索引值大于链表大小的一半,那么将从尾结点开始遍历。
这样的效率是非常低的,特别是当 index 越接近 size 的中间值时。
总结:
- LinkedList 插入,删除都是移动指针效率很高。
- 查找需要进行遍历查询,效率较低。