Spark Streaming可以整合多种输入数据源,如Kafka、Flume、HDFS甚至是普通的TCP套接字。经处理后的数据可存储至文件系统、数据库、或显示在仪表盘。
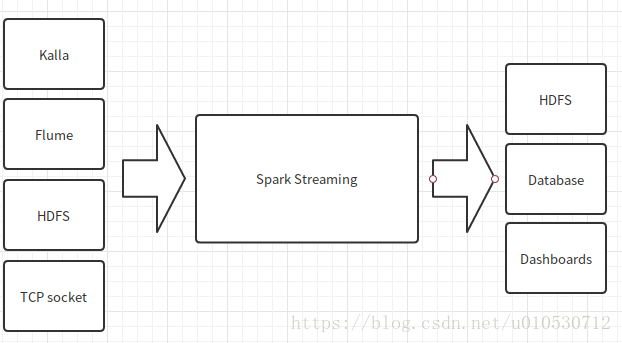
Spark Streaming执行流程
Spark Streaming的基本原理是将实时输入数据流以时间片(秒级)为单位进行拆分,然后经Spark引擎以类拟批处理的方式处理每个时间片数据

DStream操作示意图
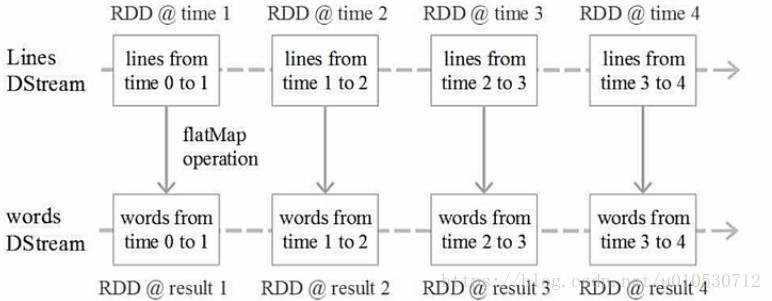
Spark Streaming最主要的抽象是DStream(Discretized Stream,离散化数据流),表示连续不断的数据流。在内部实现上,Spark Streaming的输入数据按照时间片(如1秒)。一个DStream,就是一堆的RDD,即RDD集合,所以多DStream的操作就是对RDD的操作
Spark输入源
DStream无状态转换操作
一个DStream,就是一堆的RDD,即RDD集合,所以多DStream的操作就是对RDD的操作
map(func):对DStream的每个元素,采用func函数进行转换,得到一个新的DStream
flatMap(func):与map相似,但是每个输入项可用被映射为0个或者多个输出项
repartition(numPartitions):通过创建更多或更少的分区改变DStream的并行程度
count():统计源DStream中每个RDD的元素数量
filter(func):返回一个新的DStream,仅包含源DStream中满足函数func的项
reduce(func):利用函数func聚集源DStream中每个RDD的元素,返回一个包含单元素RDDs的新DStream
union(otherStream):返回一个新的DStream,包含源DStream和其他DStream的元素
countByValue():应用于元素类型为K的DStream上,返回一个(K,V)键值对类型的新DStream,每个键的值是在原DStream的每个RDD中的出现次数
reduceByKey(func,[numTasks]):当一个由(K,V)键值对组成的DStream上执行该操作时,返回一个新的由(K,V)键值对组成的DStream,每一个key的值均由给定的reduce函数聚集起来