- 在文章开头给出结对同学的博客链接、本作业博客的链接、你所Fork的同名仓库的Github项目地址【1'】
本次作业链接
我
队友
Github项目地址
- 给出具体分工【1'】
我:基本代码实现,爬虫
队友:单元测试,效能分析,编码规范
- 给出PSP表格【1'】
| Planning |
计划 |
10 |
10 |
| • Estimate |
• 估计这个任务需要多少时间 |
10 |
10 |
| Development |
开发 |
600 |
480 |
| • Analysis |
• 需求分析 (包括学习新技术) |
60 |
50 |
| • Design Spec |
• 生成设计文档 |
60 |
40 |
| • Design Review |
• 设计复审 |
50 |
20 |
| • Coding Standard |
• 代码规范 (为目前的开发制定合适的规范) |
10 |
10 |
| • Design |
• 具体设计 |
60 |
60 |
| • Coding |
• 具体编码 |
180 |
150 |
| • Code Review |
• 代码复审 |
60 |
60 |
| • Test |
• 测试(自我测试,修改代码,提交修改) |
120 |
90 |
| Reporting |
报告 |
90 |
110 |
| • Test Repor |
• 测试报告 |
30 |
60 |
| • Size Measurement |
• 计算工作量 |
30 |
20 |
| • Postmortem & Process Improvement Plan |
• 事后总结, 并提出过程改进计划 |
30 |
30 |
|
合计 |
700 |
600 |
- 解题思路描述与设计实现说明【15'】
- 爬虫使用【3'】
- Pycharm写pathon代码爬下来放在result.txt文件中 具体代码实现
import requests
from lxml import etree
from retrying import retry
@retry(stop_max_attempt_number=3) # 设置超时重新连接 次数3
def get( url ):
response = requests.get(url=url,timeout=3)
return response.content.decode()
response = get("http://openaccess.thecvf.com/CVPR2018.py")
selector = etree.HTML(response)
links=selector.xpath('//dt[@class = "ptitle"]/a/@href')
titles = selector.xpath('//dt[@class = "ptitle"]/a/text()')
fb = open('result.txt','w',encoding='utf-8')
for i in range(len(links)):
response2 = get("http://openaccess.thecvf.com/"+links[i])
selector2 = etree.HTML(response2)
abstract = selector2.xpath('//div[@id = "abstract"]/text()')[0]
fb.write('%s' % i + '\n' + 'Title: %s' % titles[i] + '\n' + 'Abstract: ' + abstract + '\n\n\n')
fb.close()
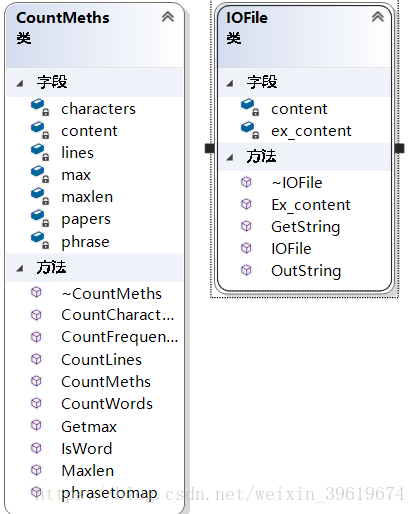
- 代码组织与内部实现设计(类图)【6'】
这次的相较于上次内部封装更加精细一点,文件读写分一个类,对读取的内容统计操作分一个类,对每个功能类中单独一个函数实现,
IOFile类封装了对文件读写的操作
GetString() 读取文件内容到content
Ex_content对ex_content赋值
OutString()将ex_content的内容写出文件
CountMeths封装了对论文的操作
功能同其名字
- 说明算法的关键与关键实现部分流程图【6'】
算法关键嘛,比较它与上一次的差别之后,
- 对行数,上一次的有效函数相较这次少了数字所在的那行所以原来的除于3乘2得到有效行数,行数除于2就得到论文篇数
- 对单词数,之前的单词数减去(论文篇数乘于2(title,abstract))得到
- 对字符数,利用论文的格式对行数标记,标记a,遇到\n加一,在1和2才计数,到5清零,标记b加一,标记b达到篇数时或读到‘\0’后停止,最后减去17(title: 和abstract:)
- 对词组数,模拟队列,利用词组数固定,单词字符单词...格式往里填充,到达一定长度合起来的词组加入map,第一个单词和分隔符弹出(一个单词的话就弹一个单词),然后接着往里填,遇到不匹配单词与\n清零
流程图:
- 关键代码解释【2'】
- 贴出你认为重要的/有价值的代码片段,并解释【2'】
对词组的筛选,这部分比较关键与重要,用时最长
.......
char onechar;
int i;
string aword = ""; //词组
string delimit = ""; //分隔符组
map<string, int> mymap;
vector<string> screen;
int cflag = 0; //碰到\n加一,加到5清零,1和2有效
int pflag = 0; //cflag清零时加一,到papers的数值使循环停下
content += '\n';//解决最后一篇没有换行不好处理
for (i = 0; content[i] != '\0'; i++)
{
onechar = content[i];
if (cflag == 1 || cflag == 2) //有效行
{
if ((onechar >= 48 && onechar <= 57) || (onechar >= 97 && onechar <= 122))
{
aword += onechar;
if (delimit != "")
{
if (screen.size() != 0)
{
screen.push_back(delimit);
}
}
delimit = "";
}
else
{
delimit += onechar;
if (IsWord(aword))
{
screen.push_back(aword);
if ((int)screen.size() >= 2 * m - 1)
{
phrasetomap(mymap, screen, cflag, m, w);
}
}
else
{
screen.clear();
}
aword = ""; //是不是单词都得清零
}
}
if (onechar == '\n')
{
screen.clear();
cflag++;
if (cflag == 1)
{
i += 7;
}
if (cflag == 2)
{
i += 10;
}
}
.......
- 性能分析与改进【6'】
- 描述你改进的思路【5'】
词组频统的从全部读取再分析到一边读取一边分析,一开始的思路是在换行和非匹配单词中间的全部读了然后在根据长度一个一个拿出来计数,可是不好实现和效率不高很明显,于是推翻重写改用队列的方式读到长度就弹出第一个就是上面写的思路。然后是怎么跳过title和abstract的问题,开始是写个标记加加忽略它,可是这样子太麻烦了而且不好记还多了变量多了判断,之后有突然想到可以直接在循环的时候i+=7跳过就好,于是直接删了重写少了很多冗余的代码。还有
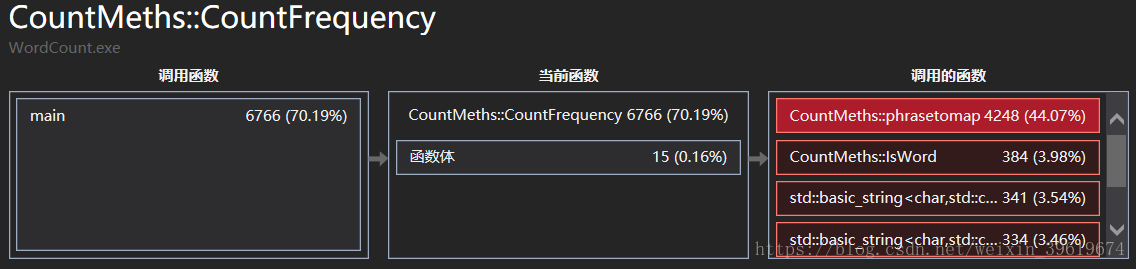
- 展示性能分析图和程序中消耗最大的函数【1'】
- 单元测试【5'】
展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路
跑一些小样例测试函数的正确性
TEST_METHOD(TestGetString)
{
IOFile test;
string f = "test.txt";
string real = "123456789";
string actual = test.GetString(f);
Assert::AreEqual(real,actual);
}
TEST_METHOD(TestIsWord)
{
CountMeths test("a");
bool actual = test.IsWord("ascdfv");
Assert::IsTrue(actual);
}
TEST_METHOD(TestCountLines)
{
string f = "0\ntitle: kkkkkaas===fffff\nabstract: rrrrrr\n\n";
CountMeths test(f);
int actual = test.CountLines();
Assert::AreEqual(2, actual);
}

- 贴出Github的代码签入记录【1'】
- 遇到的代码模块异常或结对困难及解决方法【5'】
- 问题描述
权重设置异常,超过两个分隔符出错,爬虫过程请求超时无响应,
- 做过哪些尝试
多测几次找到可以点在那个地方调试发现错误并修改
- 是否解决
解决了
- 有何收获
学习了爬虫的超时重新连接的方法,调试过后对自己思路更清晰了点
- 评价你的队友【2'】
- 值得学习的地方
代码规范,认真踏实
- 需要改进的地方
提高代码量
- 学习进度条【1'】
| 1 |
500 |
500 |
12 |
12 |
学习代码规范 |
| 2 |
300 |
800 |
6 |
18 |
学习原型设计 |
| 3 |
500 |
1300 |
12 |
30 |
学习python爬虫 |