00.前言:
- 本次作业链接
- 队友博客链接
- github仓库链接
- 结对成员:031602605 陈浩 and 031602634 吴志鸿
01.分工:
- 031602605 陈浩:负责词频分析部分,在原WordCount的基础上进行升级,添加新的命令行参数支持更多的功能包括自定义输入输出文件,权重词频统计,词组统计等新功能的设计。
- 031602634 吴志鸿:负责关于爬虫部分的所有设计,从CVPR2018官网爬取今年的论文列表,以及其他拓展功能的设计。
02.PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 25 |
| Estimate | 估计这个任务需要多少时间 | 30 | 25 |
| Development | 开发 | 480 | 600 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 120 |
| Design Spec | 生成设计文档 | 35 | 30 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 25 |
| Design | 具体设计 | 120 | 150 |
| Coding | 具体编码 | 120 | 120 |
| Code Review | 代码复审 | 120 | 150 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 90 | 120 |
| Test Repor | 测试报告 | 30 | 45 |
| Size Measurement | 计算工作量 | 10 | 15 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 35 |
| 合计 | 1225 | 1600 |
03.解题思路描述与设计实现说明:
解题思路简述:
- 本次作业主要分成两个步骤,先是根据题目需要,按照格式要求爬取论文列表;之后在对爬取的论文列表进行词频分析。实现对WordCount的升级。
- 爬虫使用
- 工具:Python
- 思路:
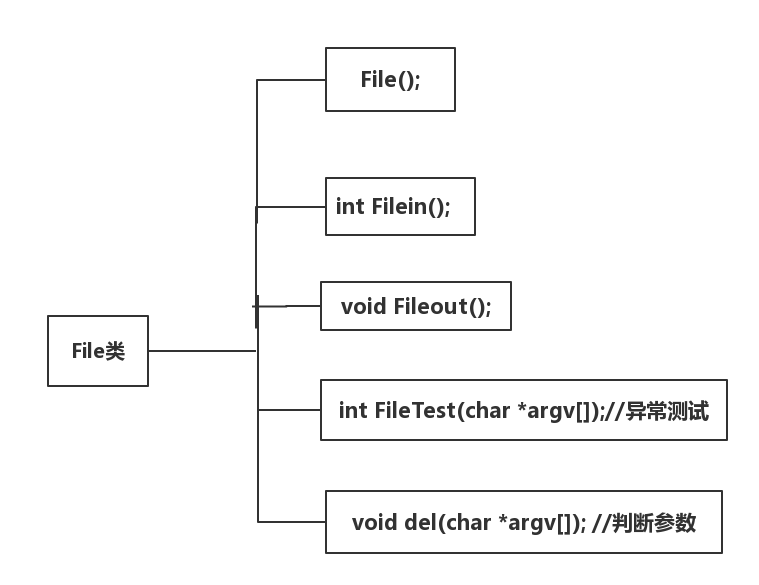
- 代码组织与内部实现设计(类图)
- 主要由两个类组成
- Word类用于实现词频分析的功能

- FIle类用于实现对命令行参数的解析,实现对文本的输入输出
- 说明算法的关键与关键实现部分流程图
- 主要说明新加三个功能
- 1.解析命令行参数:
- 遍历*argv[]数组- 遇到 -i 时 读取后面的输入路径字符,并写入输入路径中
- 遇到 -o 时 读取后面的输出路径字符,并写入输出路径中
- 遇到 -m 时 读取后面的字符串,并利用函数转换成正整数,存储数值
- 遇到 -n 时 读取后面的字符串,并利用函数转换成正整数,存储数值
- 遇到 -w 时 读取后面的字符串,并利用函数转换成正整数,存储数值
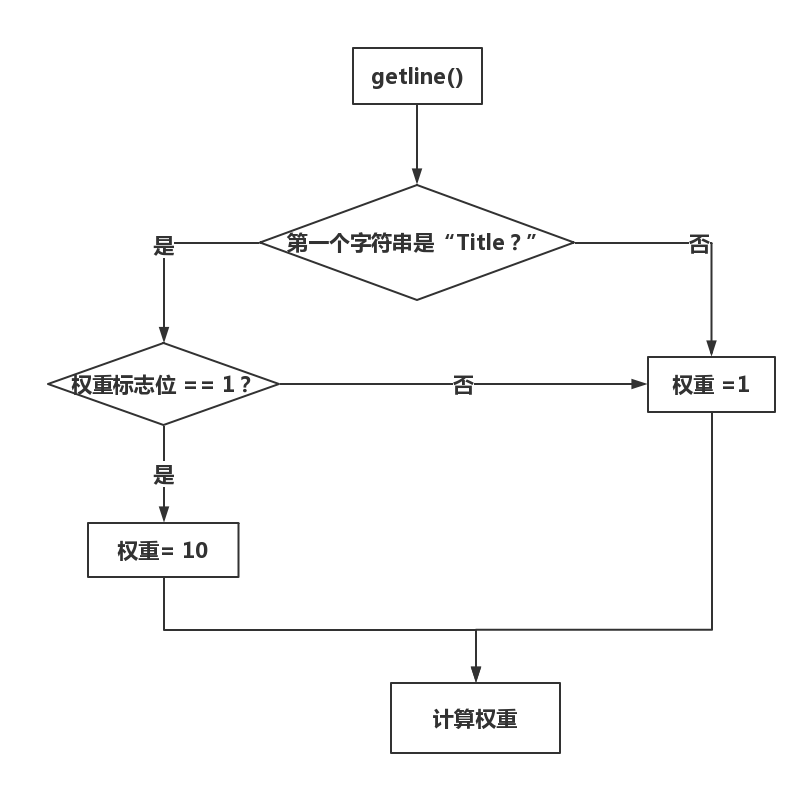
- 2.权重统计:
- 首先根据从-w参数后读出的数值是0和1分别选择两种权重模式。
- 每次利用getline函数读取一行,判断开头第一个单词是 “Title“” 还是“Absatra”,在根据权重模式来分别计算两种情况下单词的权重值。
- 流程图如下
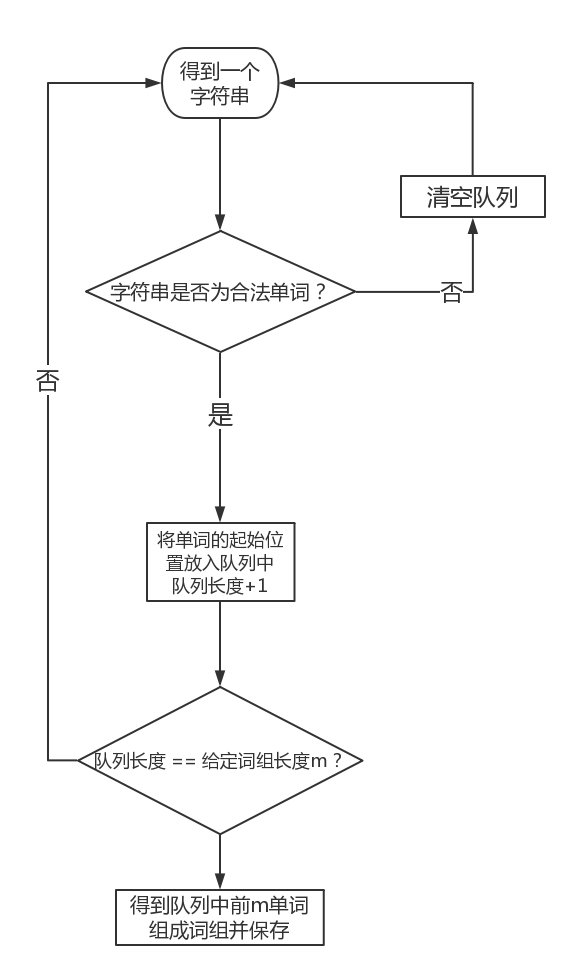
- 3.词组统计:
- 获取一个合法输入单词,将单词的起始加入队列,判断下一个单词是不是合法单词,如果不是,清空队列,重新获取单词;如果是,则循环上一次操作,队列长度+1,直到队列长度符合输入的指定词组长度,从队列中得到单词位置,记录词组。
- 流程图如下
04.附加题设计与展示:
设计的创意独到之处
实现思路
实现成果展示
05.关键代码解释:
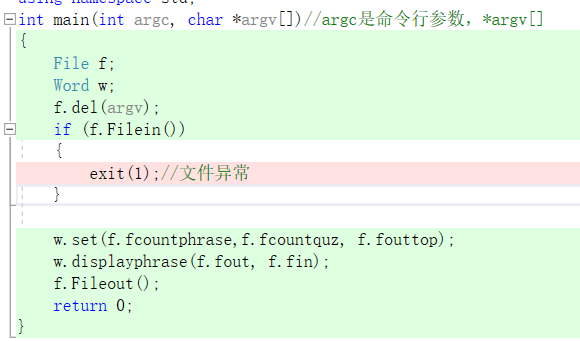
- 解析命令行参数
void File::del(char *argv[])
{
for (int i = 1; argv[i] != NULL; i = i + 2)
{
//遇到-i参数时,读入读取文件地址
if (strcmp(argv[i],"-i") == 0) {
input = argv[i + 1];
continue;
}
//遇到-o参数时,读入写入文件地址
else if (strcmp(argv[i], "-o") == 0) {
output = argv[i + 1];
continue;
}
//遇到-w参数时,判断权重
else if (strcmp(argv[i], "-w") == 0) {
fcountquz = atoi(argv[i + 1]);
//cout << countquz << "aaa" << endl;
}
//遇到-m参数时,得到词组大小
else if (strcmp(argv[i], "-m") == 0) {
fcountphrase = atoi(argv[i + 1]);
//cout << countphrase << "bbb" << endl;
}
//遇到-n参数时,得到输出前n个词组
else if (strcmp(argv[i], "-n") == 0) {
fouttop = atoi(argv[i + 1]);
//cout << outtop << "ccc" << endl;
}
}
return;
}06.性能分析与改进:
改进思路
本次代码是在原有的WordCount的基础上对代码进行改进,在对命令行参数进行解析时,我主要是用一个循环匹配命令行标志位,之后用atoi函数获得对应参数;在单词/词组的存储上,我还是使用unordered_map进行存储,在词组判断方面我主要是用双向队列deque存储每个单词的起始位置,当队列当中存储的标志位达到上限时,输出标志位,截取字符串,这样做法的好处在于无论是单个的单词,还是一个词组,这样都可以使用,原本我打算用指针对单词标识位进行存储,后面发现链表查找效率太低,所以用了deque。暂时没有更好的思路了。
- 测试代码时其中一个测试样例如下(命令行参数为-i ./result.txt -o output.txt -w 1 -m 3 )
0
Title: Embodied Question Answering
Abstract: We present a new AI task -- Embodied Question Answering (EmbodiedQA) -- where an agent is spawned at a random location in a 3D environment and asked a question ("What color is the car?"). In order to answer, the agent must first intelligently navigate to explore the environment, gather necessary visual information through first-person (egocentric) vision, and then answer the question ("orange"). EmbodiedQA requires a range of AI skills -- language understanding, visual recognition, active perception, goal-driven navigation, commonsense reasoning, long-term memory, and grounding language into actions. In this work, we develop a dataset of questions and answers in House3D environments, evaluation metrics, and a hierarchical model trained with imitation and reinforcement learning.- 样本输出结果:
characters: 817
words: 80
lines: 2
<embodied question answering>: 11
<active perception, goal>: 1
<agent must first>: 1
<answering (embodiedqa) -- where>: 1
<commonsense reasoning, long>: 1
<driven navigation, commonsense>: 1
<environment, gather necessary>: 1
<environments, evaluation metrics>: 1
<first intelligently navigate>: 1
<first-person (egocentric>: 1本次性能分析测试主要使用从CVPR2018官网爬取的979篇文章的标题和摘要来进行测试,性能分析图如下:
- 测试得到代码覆盖率如下所示

代码覆盖率达到了90%,没有更高的原因在于代码中有写入对文件的异常处理如下
07.单元测试:
- 本次一共做了10组单元测试如下,重要测试附有代码,具体如下:
- 1.测试空白输入文本(行数、字符数和单词数都应该为0,测试函数Countcharacters、Countlines、Countwords)
TEST_CLASS(EmptyTest)
{
public:
TEST_METHOD(TestMethod1)
{
//空白文本
File f;
Word w;
f.Filein();
int num = w.Countcharacters(f.fin);
int num1 = w.Countlines(f.fin);
int num2 = w.Countwords(f.fin);
Assert::IsTrue( (num==0) &&(num1==0) && (num2== 0) );
// TODO: 在此输入测试代码
}
};- 2.测试不存在输入文本文本输入(文本输入路径不存在,返回值为1,测试Filein函数)
TEST_CLASS(UnexistTest)
{
public:
TEST_METHOD(TestMethod1)
{
//错误文本
File f;
Word w;
f.input = "./unexist.txt";
int num=f.Filein();
Assert::IsTrue(num == 1);
// TODO: 在此输入测试代码
}
};
3.测试只含Title的输入文本(返回行数为1行,测试函数Countcharacters、Countlines、Countwords)
4.测试只含Abstract的文本输入(返回行数为1行,测试函数Countcharacters、Countlines、Countwords)
5.测试纯数字样本(返回字符数应该为0,测试函数Countwords)
TEST_CLASS(NumTest) { public: TEST_METHOD(TestMethod1) { //测试纯数字样本 File f; Word w; f.input = "./input2.txt"; f.Filein(); int num2 = w.Countwords(f.fin); Assert::IsTrue(num2 == 0); // TODO: 在此输入测试代码 } };6.测试基本案例(从爬取论文列表中选出其中一项,测试函数Countcharacters、Countlines、Countwords)
7.测试大型样本含权重样本输出词组(从爬取论文列表中选出其中多项,测试函数Countcharacters、Countlines、Countwords、Counttop10)
TEST_CLASS(TopTest1) { public: TEST_METHOD(TestMethod1) { //测试大型样本含权重样本输出词组 File f; Word w; w.set(3, 1, 20); f.input = "./top.txt"; f.Filein(); vector<pair<string, int>> v = w.Counttop10(f.fin, 20); int characters = w.Countcharacters(f.fin); int word = w.Countwords(f.fin); int line = w.Countlines(f.fin); vector<pair<string, int>>::iterator iter = v.begin(); Assert::IsTrue(characters == 2915 && word ==287 && line == 6 && iter->second == 11); // TODO: 在此输入测试代码 } };8.测试大型样本不含权重样本输出词组
9.测试含权重样本的输出词组(从爬取论文列表中选出其中多项,读取词组内容,测试函数Countcharacters、Countlines、Countwords、Counttop10)
TEST_CLASS(PhraseTest1)
{
public:
TEST_METHOD(TestMethod1)
{
//测试含权重样本的输出词组
File f;
Word w;
w.set(3, 1, 66);
f.input = "./P.txt";
f.Filein();
vector<pair<string, int>> v = w.Counttop10(f.fin,66);
int characters = w.Countcharacters(f.fin);
int word = w.Countwords(f.fin);
int line = w.Countlines(f.fin);
int num = v.size();
vector<pair<string, int>>::iterator iter = v.begin();
Assert::IsTrue(characters == 817 && word == 80 && line == 2 && num == 38 && iter->first == "embodied question answering" && iter->second==11);
// TODO: 在此输入测试代码
}
};- 10.测试不含权重样本的输出词组
08.Github的代码签入记录:

9.遇到的代码模块异常或结对困难及解决方法:
问题描述
做过哪些尝试
是否解决
有何收获
10.评价你的队友:
- 阿鸿小哥哥是一个很负责很有趣的人,做事态度认真负责,学习效率很快,我们一起讨论过怎么用c++实现爬虫,最后只讨论出一个思路,在实现的时候发现对c++的第三库不是很熟悉,我比较浮躁的时候,阿鸿都会很冷静的继续完成作业。需要改进的地方是阿鸿代码基础不是很好,还是需要尽快提高代码能力带带我。(毕竟我也是蒟蒻...orz)
11.学习进度条:
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 1200 | 1000 | 20 | 20 | VS初步学习,温习了c++ stl库 |
| 2 | 500 | 1700 | 12 | 32 | 学习了Axure RP,理解了NABCD模型 |
| 3 | 1000 | 2700 | 20 | 52 | 温习了Python,学习了一些Android开发的知识 |
| 4 | 500 | 3200 | 10 | 62 | 继续学习了一些Android开发的知识 |