常考的数据结构
二叉树
首先说说什么是二叉树?在计算机科学中,二叉树(英语:Binary tree)是每个节点最多只有两个分支(即不存在分支度大于2的节点)的树结构。通常分支被称作“左子树”或“右子树”。二叉树的分支具有左右次序,不能随意颠倒。
那么什么是树?
一棵树(tree)是由n(n>0)个元素组成的有限集合,其中:
(1)每个元素称为结点(node);
(2)有一个特定的结点,称为根结点或根(root);
(3)除根结点外,其余结点被分成m(m>=0)个互不相交的有限集合,而每个子集又都是一棵树(称为原树的子树)
他的每一个节点可以有零个或多个后继节点,单有且只有一个前驱节点(根节点除外);这些数据节点按分支关系组织起来,清晰地反映了数据元素间的层次关系,
二叉树的遍历
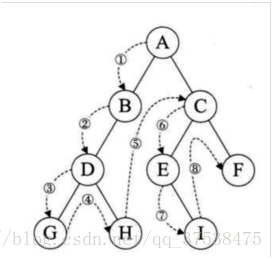
1.先(根)序遍历的递归算法定义:
若二叉树非空,则依次执行如下操作:
(1)访问根结点;
(2)先序遍历左子树;
(3)先序遍历右子树。
ABDGHCEIF
2.中(根)序遍历的递归算法定义:
若二叉树非空,则依次执行如下操作:
- 中序遍历左子树;
- 访问根结点;
- 中序遍历右子树。
GDHBAEICF
3.后(根)序遍历得递归算法定义:
若二叉树非空,则依次执行如下操作:
- 后序遍历左子树;
- 后序遍历右子树;
- 访问根结点。
GHDBIEFCA
二叉排序树
二叉排序或者是一棵空树,或者是具有下列性质的二叉树:
(1)若左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(2)若右子树不空,则右子树上所有结点的值均大于它的根结点的值;
(3)左、右子树也分别为二叉排序树;
(4)没有键值相等的节点。
插入:
若二叉排序树为空,则创建一个key域为k的节点,将他作为根节点,否则将k和根节点的关键字比较,若两者相等,则说明树中已有k,无需插入,直接返回。若k>T 则插入右子树,<则插入左子树。
查找:
查找的平均查找长度和二叉排序树的形态有关,最差情况为(n+1)/2和单链表的顺序查找相同。最好情况为树的形态比较匀称,平均查找长度为log2n。
删除:先进行查找,找到待删除的节点和其父节点,p指向待删除的节点,q指向p的父节点
- 若待删除的是叶子节点,则直接删除该节点
- 若只有左子树没有右子树,则将左子树的根节点放在p的位置上。同理只有右子树没有左子树。
- 若同时有左子树和右子树,则可以将左子树中最大的节点或右子树中最小的节点放在被删除的节点位置。
平衡二叉树
平衡二叉树(Self-balancing binary search tree)又被称为AVL树(有别于AVL算法),且具有以下性质:它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。平衡二叉树的常用实现方法有红黑树、AVL、替罪羊树、Treap、伸展树等。 最小二叉平衡树的节点的公式如下 F(n)=F(n-1)+F(n-2)+1 这个类似于一个递归的数列,可以参考Fibonacci(斐波那契)数列,1是根节点,F(n-1)是左子树的节点数量,F(n-2)是右子树的节点数量。
完全二叉树
完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。
堆
堆是一种经过排序的完全二叉树或满二叉树,n个元素的序列{k1,k2,…,kn},当且仅当满足如下关系时被成为堆(1)Ki <= k2i 且 ki <= k2i-1或 (2) Ki >= k2i 且 ki >= k2i-1(i = 1,2,…[n/2])当满足(1)时,为最小堆,当满足(2)时,为最大堆。

插入:最大堆的插入的思想就是先在最后的结点添加一个元素,然后沿着树上升。跟最大堆的初始化大致相同。

删除:
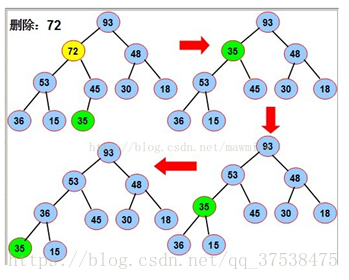
操作原理是:当删除节点的数值时,原来的位置就会出现一个孔,填充这个孔的方法就是,
把最后的叶子的值赋给该孔并下调到合适位置,最后把该叶子删除。
如图中要删除72,先用堆中最后一个元素来35替换72,再将35下沉到合适位置,最后将叶子节点删除。
“结点下沉”
常考的排序算法
冒泡排序
原理如下:
-
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
-
对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
-
针对所有的元素重复以上的步骤,除了最后一个。
-
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
//升序
void sort(int num[]){
for(int i=0;i<num.length;i++){
for(int j=0;j<num.length-i-1;j++){
if(num[j]>num[j+1]){
int tamp = num[j];
num[j] = num[j+1];
num[j+1] = tamp;
}
}
}
}时间复杂度 
快速排序
1)设置两个变量i、j,排序开始的时候:i=0,j=N-1;
2)以第一个数组元素作为关键数据,赋值给key,即key=A[0];
3)从j开始向前搜索,即由后开始向前搜索(j--),找到第一个小于key的值A[j],将A[j]和A[i]互换;
4)从i开始向后搜索,即由前开始向后搜索(i++),找到第一个大于key的A[i],将A[i]和A[j]互换;
5)重复第3、4步,直到i=j; (3,4步中,没找到符合条件的值,即3中A[j]不小于key,4中A[i]不大于key的时候改变j、i的值,使得j=j-1,i=i+1,直至找到为止。找到符合条件的值,进行交换的时候i, j指针位置不变。另外,i==j这一过程一定正好是i+或j-完成的时候,此时令循环结束)。
void qsort(int num[],int s,int t){
int i=s ,j=t;
int tamp;
if(s<t){
tamp = num[s];
while(i!=j){
while(j>i&&num[j]>=tamp)
j--;
num[i] = num[j];
while(j>i&&num[i]<=tamp)
i++;
num[j] = num[i];
}
num[i] = tamp;
qsort(num,s,i-1);
qsort(num,i+1,t);
}
}时间复杂度
最坏情况:每次选取的基准都为最小或最大时间复杂度为
最好情况:O(nlog2n)
堆排序
简单的来说就是构建一个最大堆,然后将他的顶输出,将尾部放置顶,然后进行下沉操作
时间复杂度:O(nlog2n)