分布式系统详解--框架(Hadoop-单机版搭建)
前面讲了这么多的理论知识,也有一些基础的小知识点,很简单的概括了一下。从这篇文章开始,就会进入到一个理论实践相结合中,这篇文章主要是讲的Hadoop,讲解它的基础认识、安装、常用命令、还有就是代码实现。让我们开始跟着小象走一遭~~

一、hadoop是什么?
Apache Hadoop软件库是一个框架,允许使用简单的编程模型跨计算机集群分布式处理大型数据集。它旨在从单个服务器扩展到数千台计算机,每台计算机都提供本地计算和存储。库本身不是依靠硬件来提供高可用性,而是设计用于检测和处理应用程序层的故障,从而在计算机集群之上提供高可用性服务,每个计算机都可能容易出现故障。
好专业的样子(点击这个连接,这是 Hadoop的官网)。
二、hadoop安装教程--单机版
2.1 下载hadoop
登录Apache Hadoop的官网。下载适合的版本,文章下载的是 2.7.5版本。当然现在已经到了3.x版本了~
2.2 解压hadoop
解压hadoop到指定目录,比如说放在 /opt 目录下面。

2.3 配置hadoop的安装环境变量
修改系统配置文件 /etc/profile文件。 操作命令 :vi /etc/profile 添加上HADOOP_HOME

2.4 修改hadoop的配置文件
因为hadoop依赖于jdk,所以需要告诉hadoop JDK 的位置
找到hadoop的安装目录。 我自己的目录是 /opt/hadoop-2.7.5/etc/hadoop 找到一个文件是hadoop-env.sh。

2.5 测试 which hadoop或者 hadoop version

2.6 根据官网给出的测试实例,我们自己做一个简单单机版的使用测试

进行上面官网的四部操作。不过这里需要有一些注意 。
第一步中新建了一个文件夹,要记住input文件夹放在了哪一个位置。
第二步就是将在etc/hadoop/下面所有的xml文件 放在上面建立的input文件夹中。
第三步就是运行 hadoop中的jar包 运行的是input 文件夹,运行完的结果放在了output文件夹下(output文件夹不要提前建立)。
第四步就是查看output文件夹。(下面用的命令是 more output part-r-00000)
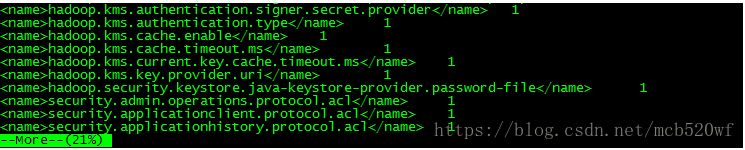
注:后面数字乃是input文件夹下面的8个文件出现的次数。
三、HDFS--原理
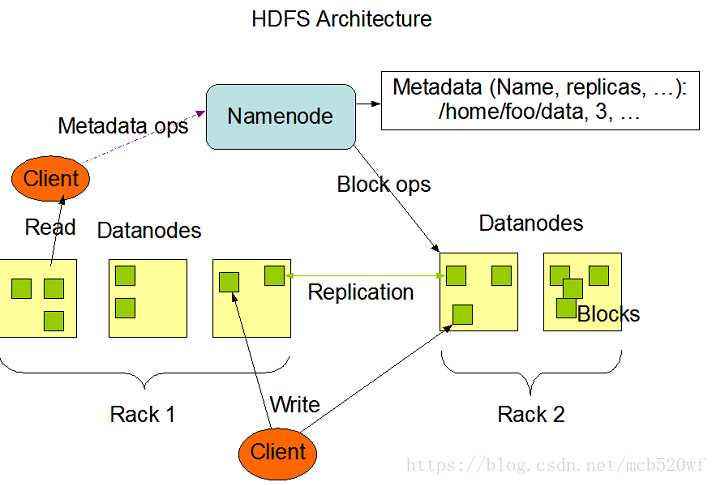
(1)HDFS原理图
(2)HDFS读写流程
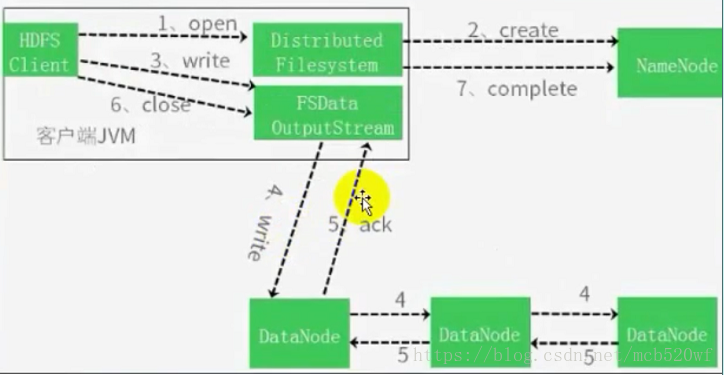
使劲看(要仔细)就行了~~
欢迎订阅公众号(JAVA和人工智能)
获取更过免费书籍资源视频资料

知识点超级链接: