一、监督学习(Supervised Learning)
- 监督学习:给学习算法一个数据集,这个数据集中包含“正确答案”。
- 回归(Regression):试着推出一系列连续值的属性。举例:房价问题。给定一系列房子的数据(房子大小以及它的实际售价),然后通过运用学习算法,算出我们需要得到的正确答案。
- 分类(Classification):试着推测出离散值的输出值。
举例:用一个软件来检验每一个用户的账户,判断它们是否被盗过(0代表未被盗过,1代表曾被盗过)。
二、无监督学习(Unsupervised Learning)
1.在无监督学习中我们已知的数据集没有标签或者它们具有相同的标签。无监督学习将这些数据分成不同的簇。(聚类算法)
2.应用于基因学的理解应用、社交网络的分析、新闻事件分类、天文数据分析等。
3.鸡尾酒算法(鸡尾酒会问题):
在宴会房间中,有2个人同时说话,有2个麦克风在房间中,这2个麦克风放在不同的地方,离说话人的距离不同,每个麦克风记录下不同的声音。这样,虽然是同样的两个人说话,但是听起来像是两份份录音叠加在一起,产生现在的录音。这个算法会区分出2个说话人的各自的声音。
代码: [W,s,v] = svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');
注:svd:奇异值分解。
三、模型表示(Model Representation)
1.监督学习算法的工作方式:
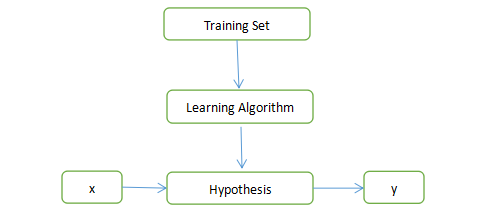
注:
Training Set:训练集;
Learning Algorithm:学习算法;
Hypothesis:假设函数;
x : 输入值;
y : 输出值。
2.单变量线性回归/线性回归:只含有一个特征(输入变量)。
四、代价函数(Cost Function)
- 代价函数也被称为平方误差函数或平方误差代价函数。
- 代价函数适合解决回归问题。
- 函数:
 注:代表训练样本的数量。
注:代表训练样本的数量。
五、梯度下降(Gradient Descent)
- 梯度下降:批量梯度下降是一个用来求函数的最小值的算法,参数更新的过程就是一个不断迭代的过程,每次更新参数得到的函数都会使误差损失越来越小,直到收敛到局部极小值。
- 批量梯度下降算法(BGD,batch gradient descent)
(1)用到了历遍整个训练集的样本,在梯度下降的过程中,当计算偏导数时,计算总和。在每一个单独的梯度下降中,最终计算m个训练样本的总和。
(2)公式表示:
注:
:=表示赋值;
α表示学习率;
(3)特点:
能达到全局最优解,易于并行实现。
每一次迭代使用全部的样本,当样本数目很多时,训练过程缓慢。
3.随机梯度下降(SGD,stochastic gradient descent algorithm)
(1)随机梯度下降每次更新参数都只使用一个样本,进行多次更新。
(2)特点:
训练速度快;
准确度下降,并不是最优解,不易于并行实现。
注:此学习笔记根据《吴恩达机器学习》课程记录,并加入了自己的理解,如果有需要改正的地方,恳请指正!