神经网络
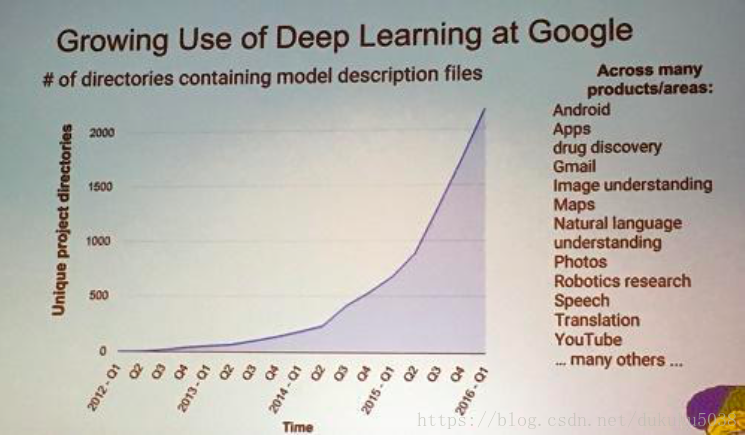
自2012年CNN的imagenet 上的突破,以神经网络网络为基础的深度学习开始风靡学界和工业界。我们来看一张图片,关于google 内部深度学习项目的数量。而且应用领域极广,从Android 到 药品发现,到youtube。
我们从一起回顾下神经网络的额前世今生:
• 1958: Perceptron (linear model)
• 1969: Perceptron has limitation
• 1980s: Multi-layer perceptron
• Do not have significant difference from DNN today
• 1986: Backpropagation
• Usually more than 3 hidden layers is not helpful
• 1989: 1 hidden layer is “good enough”, why deep? • 2006: RBM initialization (breakthrough)
• 2009: GPU
• 2011: Start to be popular in speech recognition
• 2012: win ILSVRC image competition
深度学习是机器学习的一个分支,目前讲是最重要的一个分支。 怎么学好深度学些呢? 其实还是关键的三步:
- 选择神经网络
- 定义神经网络的好坏
- 选择最好的参数集合
以下是神经网络的示意图:
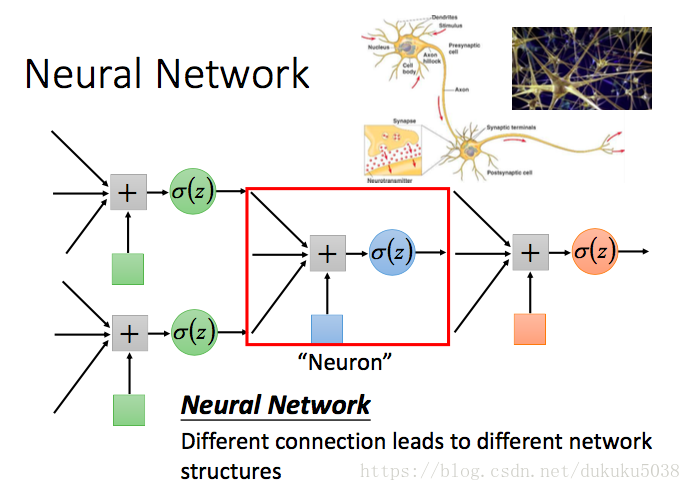
所有的 和 b 都在神经元内
1 全连接网络(Fully Connection)
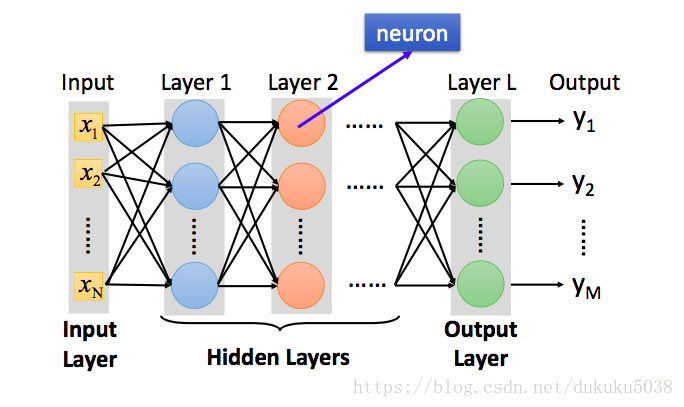
2 深度网络 DEEP
深度 = 很多层
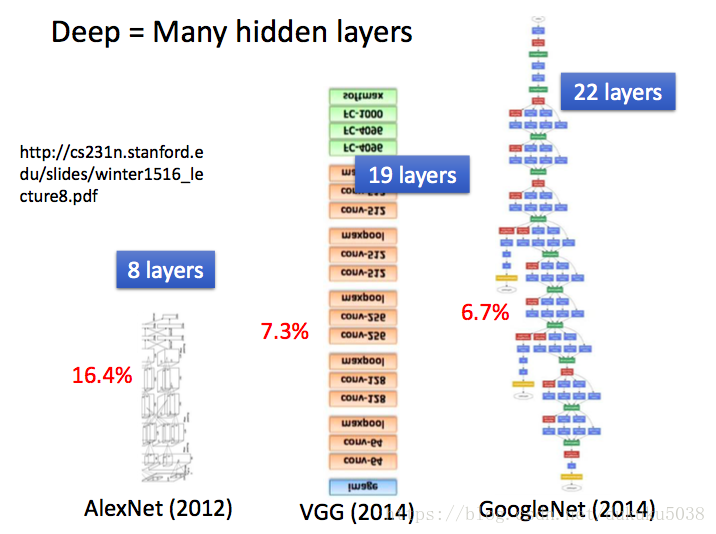
那么有人就会问:
- 到底多少层深度合适?每层多个神经元?
答:这个看经验和实验的结果,不断调整。 - 结构能被自动设定吗?
答:可以通过进化网络实现。 - 我们能自己设计网络结构吗?
答: CNN 就是设计出来的网络结构。
3 定义神经网络的好坏Loss
我们以minist 数字识别为例,一组数字识别为例
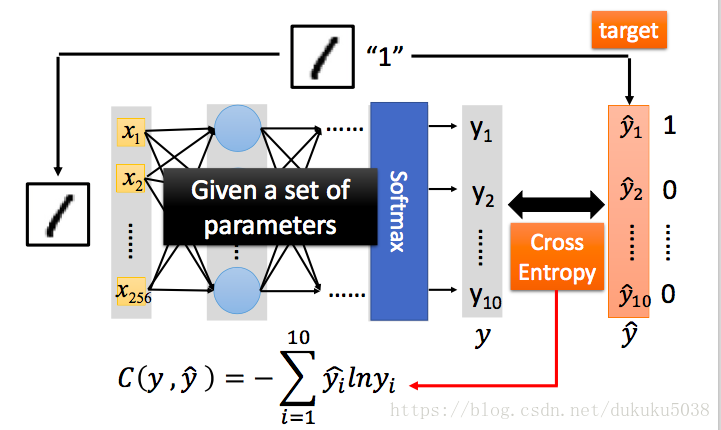
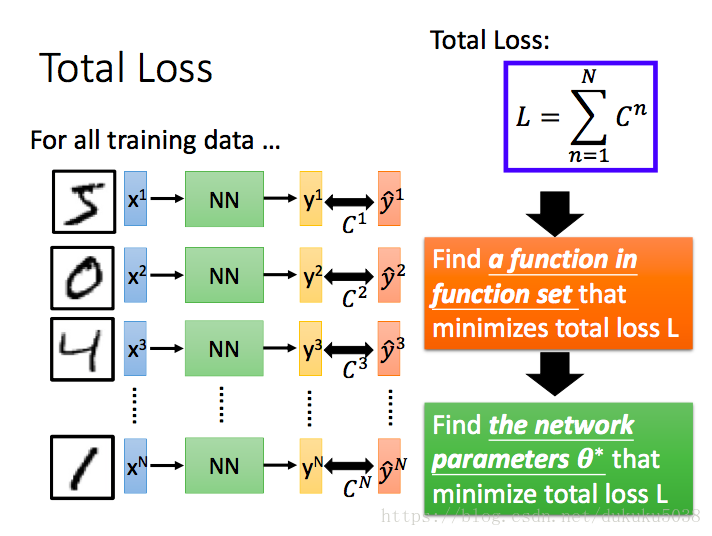
4 选择最好的神经网络(找到参数集)
核心方法:
- Gradient Descent
- BackPropagation


深度学习基本知识点了解到了,但是为什么越Deep,效果会越好? 以前都是做类比思考,比如电路模型,但是近期的lpaper上在理论上有严格的证明,我们后续博客会介绍