计算能力一般通过两个参数表征:
- Peak GOPs峰值性能
- Real GOPs实测性能(针对特定网络)
FPGA在推理过程,可以做到高的Real GOPs/Peak GOPs,而训练过程,他的结构与算法并不完全匹配。希望后面出的器件可以克服。
- FPGA的算力优势
- 推理时的低延迟,特别时batch size为1时,这个在微软Brainwave Project项目中中反复提到。
GPU的优势是块处理,批量数据进,批量计算,这样可以利用他的海量计算单元,以及外部存储。但推理时batch size为1的运算,FPGA的流水线设计优势明显。
- 定制化计算引擎
阵列式、可重构的数据流引擎(权重、数据流入、计算合理配合),配合大量分布式RAM的设计,可以让FPGA适配特定的神经网络,针对应用场景的Real GOPs/Peak GOPs比率高。
这个我想就是FPGA宣称功耗比GPU做的更低的原因。
另外在优化做到极致情况下,某些神经网络中FPGA的Real Gops确实有可能超过GPU
- 持续演进的软硬件融合
通过算法优化压缩网络、压缩权重、配合适配的NPU结构,更小的计算量达到接近的精度。
- FPGA算力缺点
FPGA不适合做训练,这个主要是训练过程反向传播的算法特点导致,主要表现在3个方面:
- 不适合浮点运算,而训练过程,基本上都是浮点运算。
我们以反向传播过程的计算为例,流行的梯度优化算法ADAM公式如下:

从上面公式可知,收敛过程,需要无数次的迭代计算,这一过程这些参数的改变量是极小的,而FPGA内部的运算单元主要是DSP(没有浮点单元),适合定点计算,迭代计算过程如果对精度进行截取,在反向传播过程中,计算误差是逐层叠加的,深度越深,误差累积越大,传播后的权重参数要不趋向于0,要不趋向于饱和,从而导致训练失败。
而推理过程权重已经训练完成,这时是针对每个参数做精度压缩,不存在误差逐级传播,只要最后计算结果与原始精度相比下降程度在可接受范围内就可以。
- 训练过程需要计算种类多,FPGA实现某些运算代价大。
训练过程中间节点的normalize,ADAM中的开根号运算等。
如果仅把正向传播的乘加运算放在FPGA中,反向梯度计算放在CPU中,每次迭代时将导致大量的参数以及中间计算结果Activation在CPU和FPGA之间反复传递,从而抵消硬件加速获得的好处。
- 算法的反向传播过程的中间结果以及权重相对正向过程需要转置。
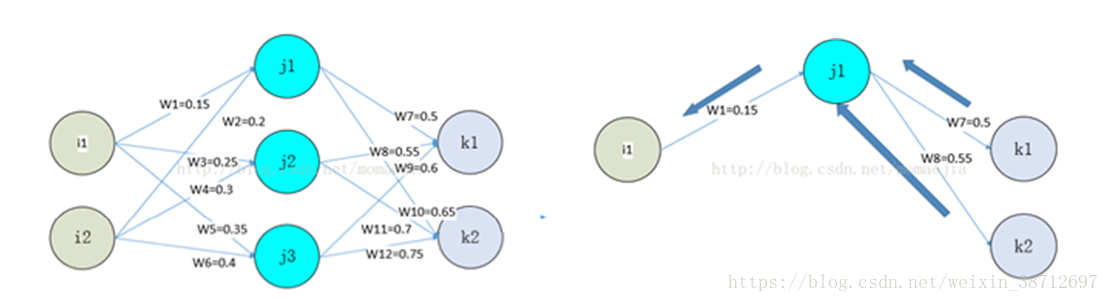
正向传播与反向传播的计算对比如下:
以最简单的反向传播计算公式来看:
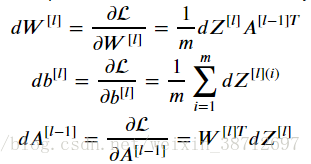
A对应途中j1,j2,j3的中间计算结果,在反向计算dW时,需要对正向计算的A做一次转置,计算dA(l-1)时,需要对权重W做一次转置。
多层神经网络时我们把权重缓存和中间的activation缓存看作一个二维阵列,正向时相当于按行读取,反向时因为转置,需要按列读取。
对应的RAM操作:正向过程利用了FPGA分布式RAM优点,一次读取出大量数据进行计算,而反向时的每次运算,由于转置,参数和中间结果集中到某几片RAM上。从而无法利用FPGA分布式RAM的高带宽优点,而FPGA的主频与CPU、GPU相比有差距,因此训练上RAM反而成为劣势,示意图如下:

因此,反向传播想做到高性能,要不需要在原生算法上做改进,要不硬件上需要找到一种二维阵列的快速访问方法。