版权声明:转载请注明出处 https://blog.csdn.net/sixkery/article/details/82989005
需求分析
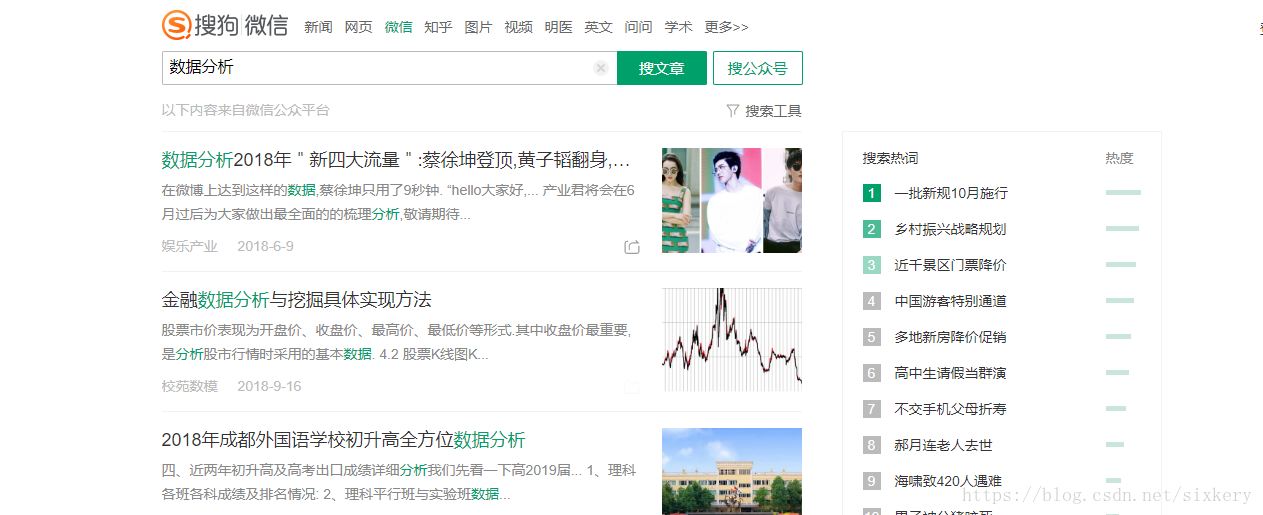
先来看一下目标网站。
这次爬取的内容是通过搜狗微信的接口获取微信文章的 url 然后提取目标文章的内容及公众号信息。
可以指定内容进行爬取
那这次需要解决的问题有哪些呢?
需要解决的问题
搜狗微信在没有登录的情况下可以爬取十页信息,我们想要获取更多的信息只能登录。在登录的情况下,爬取数据量太大会被封 IP 。这里给出的解决方案是使用代理池的方法。我这里是自己搭建了一个小的IP代理池,在我以前的文章里有详细的描述,可以 点这里 查看。
代码演示
proxy = None # 声明代理为 None 也就是开始的时候用本机的ip爬取
count_max = 5 # 设置一个连接错误,如果连接超过五次都出错就停止爬取,要不然程序陷入死循环。
# 请求头的设置要加上cookie
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
}
# 获取代理
def get_proxy():
proxy = GetIP()
return proxy.get_random_ip()
# 请求页面,这里主要使用了代理,一开始使用的是本机代理,被封之后换个ip来爬。
def get_request(url,count=1):
global proxy
if count >= count_max:
print('请求太多次了,这个方法不行啦,换换吧')
try:
if proxy:
proxies = {'http': 'http://' + proxy}
r = requests.get(url, headers=headers,proxies=proxies, allow_redirects=False)
else:
print('第一次请求,使用本机的ip')
r = requests.get(url,headers=headers,allow_redirects=False)
if r.status_code == 200:
print('第一页')
return r.text
if r.status_code == 302:
print('状态码302了,快换代理吧')
proxy = get_proxy()
if proxy:
print('正在使用代理爬取', proxy)
return get_request(url)
else:
print('获取代理出错')
return None
except ConnectionError as e:
count += 1
proxy = get_proxy()
return get_request(url,count)
解释
这里是整个代码的核心,我们先用本机的 ip 来爬取数据,如果爬取的量大起来,会封 ip ,然后 url 会重定向到输入验证码的页面,我们可以根据状态码是 302 来判断这一情况,然后使用代理。并递归调用函数本身用ip来爬。
有些时候状态码不是302,也不是200 ,这时候就是连接的问题,我们也使用代理来解决这一问题。并计数,连接出现问题的次数超过五次就停止,这样的情况下是别的问题,不要让在自己调用自己死循环,退出重新检查代码逻辑。
我的代码里面没有加 cookie ,使用的时候加上cookie 才能爬取十页以后的内容。
# 解析页面得到微信文章的详情url
def parse_page(html):
data = etree.HTML(html)
li = data.xpath('//ul[@class="news-list"]/li')
for i in li:
url = i.xpath('./div[2]/h3[1]/a/@href')[0]
parse_detial(url)
break
# 解析详情页获取微信公众号标题,作者,内容。
def parse_detial(url):
response = requests.get(url,headers=headers)
if response.status_code == 200:
html = etree.HTML(response.text)
title = html.xpath('//h2[@id="activity-name"]/text()')
if title:
title = title[0].strip()
wechat_name = html.xpath('//a[@id="js_name"]/text()')
if wechat_name:
wechat_name = wechat_name[0].strip()
wechatid = html.xpath('//span[@class="profile_meta_value"]/text()')[0]
# 获取内容,xpath 虽然好用,但是这一时半会也没找到怎么获取文章内容的方法,就用 pyquery 吧,其实就是css选择器
doc = pq(response.text)
content = doc('.rich_media_content').text()
result = {'title':title,
'wechat_name':wechat_name,
'wechatid':wechatid,
'content':content}
print(result)
#
# 不适合导出CSV格式,应该导出json格式
# ws = [title,wechat_name,wechatid,content]
# print(ws)
# with open('weixin_article.csv','a',newline='') as f:
# writer = csv.writer(f)
# writer.writerow(ws)
def main():
# 处理翻页
for page in range(1):
KEYWORD = '数据分析' # 这里可以更改关键字
url = 'https://weixin.sogou.com/weixin?query='+ KEYWORD + '&type=2&page={}'.format(page)
html = get_request(url)
parse_page(html)
if __name__ == '__main__':
main()
这之后的代码就是常规的爬虫写法,并没有什么说道。
这里我用 xpath 没有获取到文章的内容,用了 pyquery 这个解析库,其实就是css 选择器。应该用xpath 也是可以获取到内容的,可能是没有想到怎么写,技术还是要在锻炼呀。
这里存储爬取下来的数据就没有再写下去了,跟之前的一样就好了,存到mongodb 。我主要是复习一下代理 ip 的使用。
本文完!