提取微信公众号文章
在上文中,我们已经将微信公众号文章的标题和链接存入了一个 txt 文件,每个一行。 接下来我们要做的就是从链接中提取文章正文,以便之后的分析。
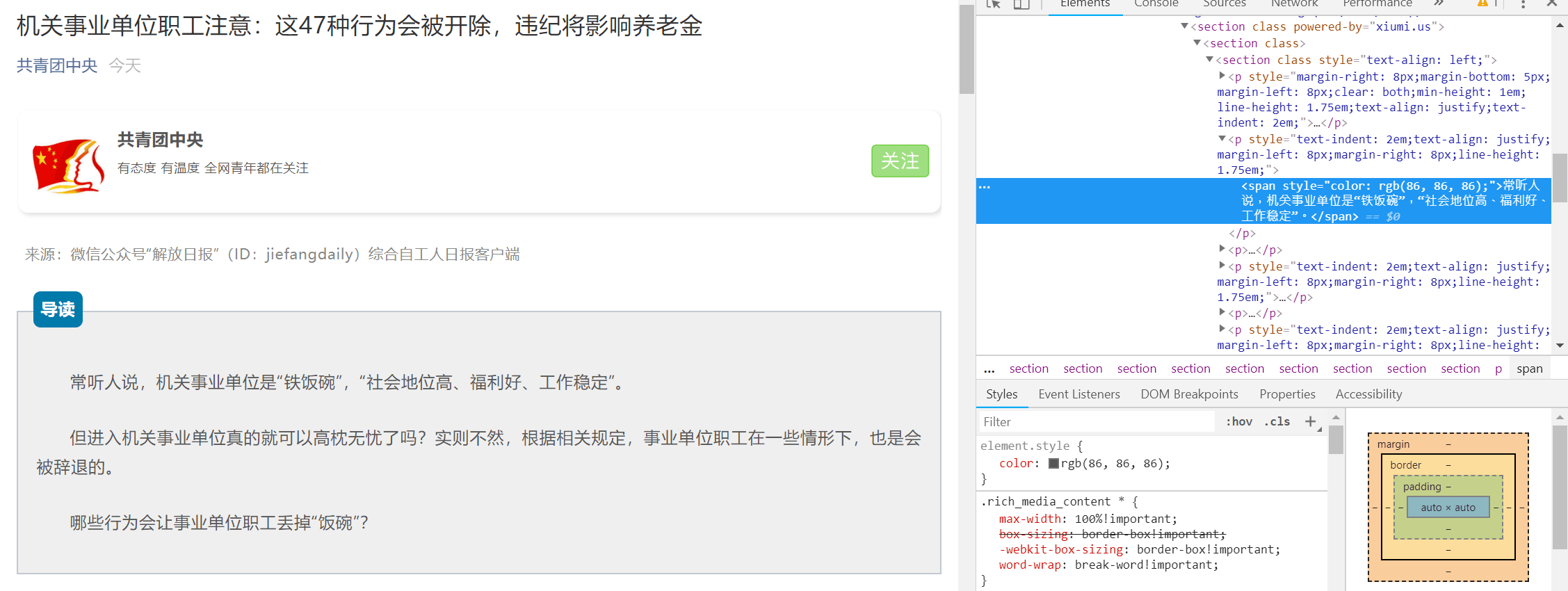
首先我们打开一篇文章,以这篇文章为例 机关事业单位职工注意:这47种行为会被开除,违纪将影响养老金,我们右击文章正文文字,检查元素所在位置,发现文章正文部分所在标签为 p。
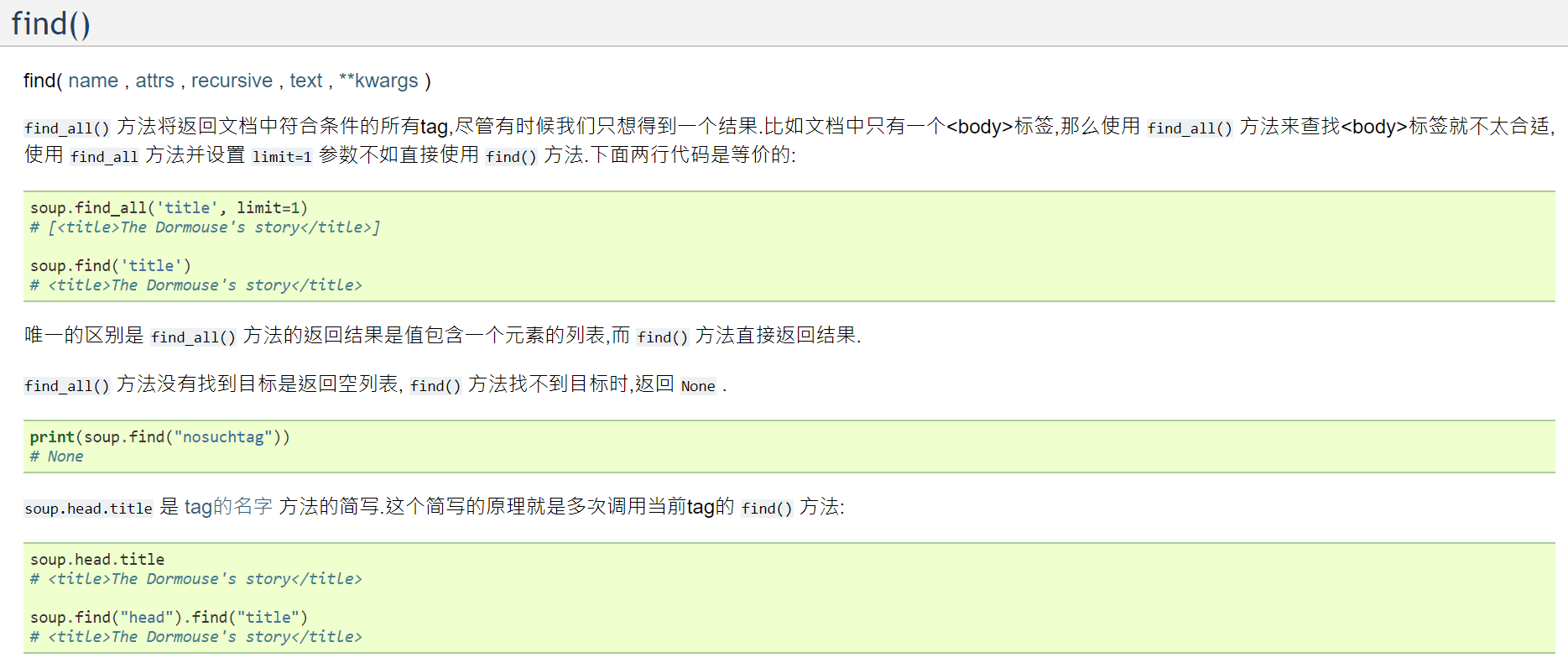
检查网页源代码也可以发现,正文文字都在 p 标签下,知识每部分文字的格式、字号等有所不同,那么我们可以使用 BeautifulSoup 中的 findall 函数来获取所有的 p 标签,这样就可以获得文章的全部正文部分。
代码如下:
def extractData(file):
titles = [row for row in file[::3]] // 列表解析
links = [row for row in file[1::3]]
for title,link in zip(titles,links):
path = os.getcwd() + "/共青团中央/" + title + ".txt"
web_data = requests.get(link)
soup = BeautifulSoup(web_data.text, 'lxml')
with open(path, 'a', encoding='utf-8') as fh:
for content in soup.find_all("p"):
fh.write(content.text)
fh.close()
print(title + " end")
if __name__=='__main__':
filename = open("共青团中央.txt", 'r', encoding='utf-8').readlines()
extractData(filename)
在上面的代码中,我们首先从之前存入的 txt 文件读取 title 和 link,因为我们是按行存储,所以我们用 readline 按行读取,得到数据的列表,之后用列表解析的方式得到 title 列表和 link 列表,获取正文后存入新的 txt 文件。