Java集合简介:
集合(Collection)由一些元素(Element)组成。
在计算机中引入集合是为了处理一组数据。
一个Java对象可以在内部持有若干其他Java对象,并对外提供访问接口,我们把这种Java对象称为集合。
Java的数组可以看做是一种集合。
如:

由于数组初始化后大小不可变,且只能按索引顺序存取,故我们需要其他各种集合类来处理:
可变大小的顺序链表;
保证无重复元素的集合。
JDK自带的java.util包提供了集合类:
Collection:所有集合类的根接口;
List:一种有序列表;
Set:一种无重复元素集合;
Map:一种通过Key查找Value的映射表集合;
Java集合设计的特点:
接口和实现相分离:如List接口实现类有ArrayList和LinkedList等;
支持泛型:如List<Student> list=new ArrayList<>();
访问集合有统一的方法:迭代器(Iterator)。
遗留类:
JDK的部分集合类是遗留类,不应该继续使用。
Hashtable:一种线程安全的Map实现;
Vector:一种线程安全的List实现;
Stack:基于Vector实现的LIFO的栈;
遗留接口:
JDK的部分接口是遗留接口,不应该继续使用。
Enumeration<E>:已被Iterator<E>取代。
总结:
Java集合类定义在java.util包中;
常用的集合类包括List,Set,Map等;
Java集合使用同一的Iterator遍历集合;
尽量不要使用遗留接口。
List:
使用List:
List<E>是一种有序列表:
List内部按照放入元素的先后顺序存放;
每个元素都可以通过索引确定自己的位置;
类似数组,但大小可变。
List<E>常用方法:
void add(E e) 在末尾添加一个元素;
void add(int index, E e) 在指定索引添加一个元素;
int remove(int index) 删除指定索引的元素;
int remove(Object e) 删除某个元素;
E get(int index) 获取指定索引的元素;
int size() 获取链表大小(包含元素的个数)。
数组也是有序结构,但大小固定,且删除元素时需要移动后续元素。
如:
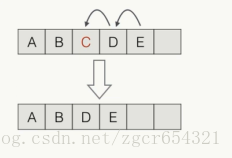
ArrayList<E>内部使用数组存储所有元素。
如:

添加一个元素:

如果内部数组已经满了,ArrayList先创建一个更大的数组,然后把旧数组的所有元素复制到新数组。然后用新数组取代旧数组。
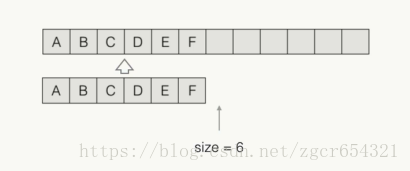
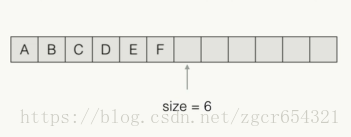
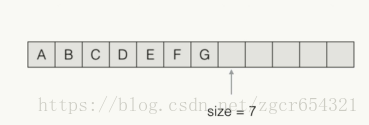
LinkedList<E>内部每个元素都指向下一个元素。
如:

添加一个元素:

ArrayList和LinkedList对比:

List元素可以重复;
List元素可以是null。
如:

如何遍历一个List<E>?
通过get(int index):这种方法对ArrayList效率较高;
如:
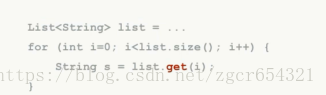
使用Iterator<E>;
如:

使用foreach循环;
如:
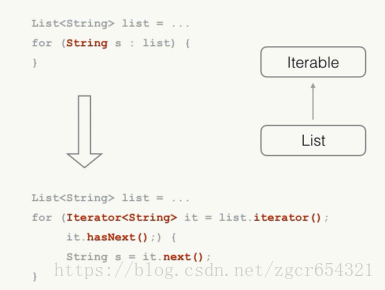
除了数组外,所有实现Iterable接口的类都可以用foreach来遍历。
编译器帮我们把foreach循环翻译成了Iterator循环。
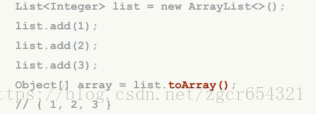
List<E>变为Array:
Object[] toArray();
如:
<T> T[] toArray(T[] a):这里的T不是泛型参数的T,所以可以传入其他类型的数组;
如:

Array变为List<E>:
<T> List<T> Arrays.asList(T... a);
如:

注意得到的List是只读的。
我们还可以进一步把得到的List变为arrayList。

整理代码,得:

总结:
List的特点:
按索引顺序访问的长度可变的链表;
优先使用ArrayList而不是LinkedList;
可以直接用for...each遍历;
可以和Array相互转换。
编写equals方法:
List<E>是一种有序链表:
List内部按照元素的先后顺序存放;
每个元素都可以通过索引确定自己的位置;
boolean contains(Object o)是否包含某个元素;
int indexOf(Object o)查找某个元素的索引,不存在则返回-1;
如:

在List内部使用equals()方法判断两个元素是否相等:

要正确调用contains / indexOf方法,放入的实例就要正确实现equals()方法。
总结:
如果要在List中查找元素:
List的实现类通过元素的equals方法比较两个元素;
放入的元素必须正确覆写equals方法:JDK提供的String、Integer等已经覆写了equals方法;
编写equals方法可借助Objects.equals()判断。
如果不在List中查找元素:
不必覆写equals方法。
Map:
使用Map:
Map是一种键值映射表,可以通过Key快速查找Value。
如:

Map<K,V>常用方法:
V put(K key, V value):把Key-Value放入Map;
V get(K key):通过Key获取Value;
boolean containsKey(K key):判断Key是否存在。
遍历Map:
遍历Key可以用for...each循环遍历keySet();
如:

同时遍历Key和Value可以使用for...each循环遍历entrySet();
如:

最常用的实现类是HashMap,HashMap内部存储不保证有序:遍历时的顺序不一定是put放入的顺序,也不一定是Key的排序顺序。
SortedMap可以保证遍历时按Key的顺序排序,SortedMap的实现类是TreeMap:

如:

我们还可以自定义其排序的算法:
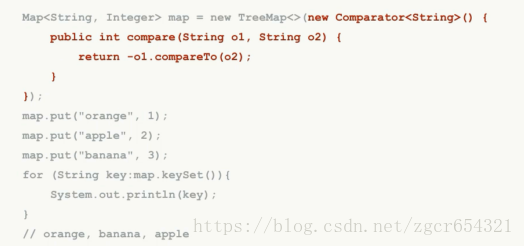
注意排序只能作用于Key,和Value没有任何关系。
总结:
Map<K,V>是一种映射表,可以通过Key快速查找Value;
可以通过for...each遍历keySet();
可以通过for...each遍历entrySet();
需要对Key排序时使用TreeMap;
通常使用HashMap。
编写equals和hashCode:
Map可以通过Key快速查找Value(元素)。
如:

当我们使用Key存储Value时会有一个问题:
我们使用get方法传入的Key对象不一定就是Map中的Key对象(尽管内容相同)。

正确使用Map必须保证:
作为Key的对象必须正确覆写equals()方法:如String、Integer、Long...
HashMap通过计算Key的hashCode()定位Key的存储位置,继而获取Value。
如:

任何对象都有hashCode()方法,这是从Object对象继承下来的。
作为Key的对象必须正确覆写hashCode()方法:
如果两个对象相等,则两个对象的hashCode()必须相等;
如果两个对象不相等,则两个对象的hashCode()不需要相等。
如果一个对象覆写了equals()方法,就必须正确覆写hashCode()方法:
如果a.equals(b)==true,则a.hashCode()==b.hashCode();
如果a.equals(b)==false,则a和b的hashCode()尽量不要相等。
总结:
作为Key的对象必须正确覆写equals和hashCode;
一个类如果覆写了equals,就必须覆写hashCode;
hashCode可以通过Objects.hashCode()辅助方法实现。
使用Properties:
Properties用于读取配置。
如:

.properties文件只能使用ASCII编码;
可以从文件系统和ClassPath读取.properties文件;
如:


我们可以读取多个.properties文件,但是后读取的Key-Value会覆盖已读取的Key-Value;
这个特性可以让我们把默认的配置文件放到classpath中,然后根据环境编写另一个配置文件,就可以覆盖某些默认的配置。
如:
Properties实际上是从Hashtable派生:

String get Property(String key);
void setProperty(String key,String value);
Object get(Object key);
void put(Object key,Object value)。
总结:
Properties用于读写配置文件XXX.Properties;
.Properties文件只能使用ASCII编码;
可以从ClassPath或文件系统读取.Properties文件;
读写Properties时:
仅使用getProperty()/setProperty()方法;
不要调用继承而来的get()/put()等方法。
Set:
Set<E>用于存储不重复的元素集合:
boolean add(E e);
boolean remove(Object o);
boolean contains(Object o);
int size()。
如:

Set实际上相当于不存储Value的Map;
Set用于去除重复元素;
放入Set的元素要正确实现equals()和hashCode()。
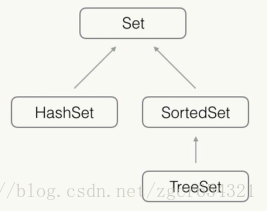
Set不保证有序:
HashSet是无序的;
TreeSet是有序的;
实现了SortedSet接口的是有序Set;
如:
HshSet不保证有序:

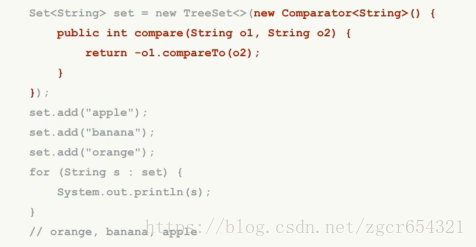
TreeSet按元素顺序排序(字符串就是按字母排序注意不是添加时的顺序):

TreeSet也可以自定义排序算法:
总结:
Set用于存储不重复的元素结合;
放入Set的元素与作为Map的Key要求相同:要正确实现equals()和hashCode();
利用Set可以去除重复元素;
遍历SortedSet按照元素的排序顺序遍历,也可以自定义排序算法。
Queue:
使用Queue:
Queue<E>实现一个先进先出(FIFO,First In First Out)的队列。
在Java中,LinkedList实现了Queue<E>接口。
Queue<E>实现一个先进先出(FIFO)的队列:
获取队列长度:size();
添加元素到队尾:boolean add(E e)/boolean offer(E e);
获取队列头部元素并删除:E remove()/E poll();
获取队列头部元素但不删除:E element()/E peek()。
当添加或获取元素失败时:

之所以有两种方法是因为操作失败时一种是抛出异常,一种是返回false或null。
如:
添加元素到队列:

获取队首元素并删除:

获取队首元素但不删除:

总结:
Queue<E>实现一个先进先出(FIFO)的队列;
add/offer将元素添加到队尾;
remove/poll从队首获取元素并删除;
element/peek从队首获取元素但不删除;
避免把null添加到队列。
使用PriorityQueue:
PriorityQueue的出队顺序与元素的优先级有关:remove()/poll()总是取优先级最高的元素。
PriorityQueue<E>具有Queue<E>接口:
添加元素到队尾:boolean add(E e)/boolean offer(E e);
获取队列头部元素并删除:E remove()/E poll();
获取队列头部元素但不删除:E element()/E peek();
PriorityQueue从队首获取元素时,总是获取优先级最高的元素。
放入PriorityQueue的元素必须实现Comparable接口。或者我们也可以不实现Comparable接口,而是给PriorityQueue添加一个Comparator实现自定义排序算法算法。
总结:
PriorityQueue<E>实现一个优先队列;
从队首获取元素时,总是获取优先级最高的元素;
默认按元素比较的顺序排序(必须实现Comparable接口);
可以通过Comparator自定义排序算法(不必实现Comparable接口)。
使用Deque:
Deque实现一个双端队列(Double Ended Queue)。
如:

Queue和Deque的方法的区别:

Deque还有一些自己独特的方法:

使用Deque<E>的时候总是调用xxxFirst()/xxxLast()方法。
如:

Deque的实现类:ArrayDeque,LinkedList。
如:

尽量持有接口,而不是实现类。
总结:
Deque实现一个双端队列(Double Ended Queue);
添加元素到队首/队尾:addLast/ offerLast/addFirst/offerFirst;
从队首/队尾获取元素并删除:removeFirst/ pollFirst/removeLast/pollLast;
从队首/队尾获取元素但不删除:getFirst/peekFirst/getLast/peekLast;
总是调用xxxFirst / xxxLast以便与Queue的方法区分开;
避免把null添加到队列。
Stack:
栈(Stack)是一种后进先出(LIFO,Last In First Out)的数据结构。
操作栈的元素的方法:
push(E e):压栈
pop():出栈*
peek():取栈顶元素但不出栈
用Deque可以实现Stack的功能:
push(E e):addFirst(E e)
pop():removeFirst()
peek():peekFirst()
为什么Java的集合类没有单独的Stack接口?
这是因为已有的class中有名称为Stack的,出于兼容性考虑,就没有Stack接口了。
Stack的作用:
方法(函数)的嵌套调用;
如:

又如:

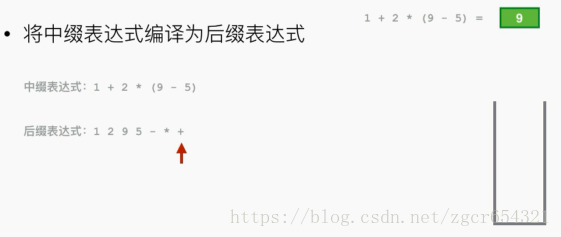
计算后缀表达式的值:

遇到减号,弹出两个数。计算得4。

把结果4重新压入栈。

遇到乘号也做类似处理。

遇到加号也做类似处理。

然后把9压栈。计算结束时,弹出栈中唯一元素即9就是结果。
总结:
栈(Stack)是一种后进先出(LIFO)的数据结构;
操作栈的元素的方法:
push(E e):压栈;
pop():出栈;
peek():取栈顶元素但不出栈;
Java使用Deque实现栈的功能,注意只调用push/pop/peek,避免调用Deque的其他方法;
不要使用遗留类Stack。
Iterator:
Java的集合类都可以使用for...each循环:List、Set、Queue、Deque。
如:

编译器把for...each循环改写为Iterator循环。
如何让自己编写的集合类使用for...each循环?
实现Iterable接口;
返回Iterator对象;
用Iterator对象迭代。集合类返回的Iterator对象知道如何迭代。

内部类可以直接访问对应外部类的字段和方法:

总结:
使用Iterator模式进行迭代的好处:
对任何集合都采用同一种访问模型;
调用者对集合内部结构一无所知;
集合类返回的Iterator对象知道如何迭代;
Iterator是一种抽象的数据访问模型。
Collections:
Collections是JDK提供的集合工具类:
boolean addAll(Collection<? super T> c,T...elements)
创建空集合(不可变):
List<T>emptyList();
Map<K,V>emptyMap();
Set<T>emptySet();
创建单元素集合(不可变):
Set<T>singleton(T o);
List<T>singletonList(T o);
Map<K,V>singletonMap(K key,V value);
对List排序(必须传入可变List):
void sort(List<T> list);
void sort(List <T> list,Comparator<? super T> c);
随机重置List的元素:
void shuffle(List<?> list);//相当于随机打乱元素顺序
把可变集合变为不可变集合:
List<T>unmodifiableList(List<? extends T> list);
Set<T>unmodifiableSet(Set<? extends T> set);
Map<K,V>unmodifiableMap(Map<? extends K,? extends V> m);
把线程不安全的集合变为线程安全的集合:
List<T>synchronizedList(List<T> list);
Set<T>synchronizedSet(Set<T> s);
Map<K,V>synchronizedMap(Map<K,V> m);
现在这几个线程不安全变为线程安全的方法已经不推荐使用。
总结:
Collections类提供了一组工具方法来方便使用集合类:
创建空集合;
创建单元素集合;
创建不可变集合;
排序/洗牌。