版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_15014327/article/details/83033414
一.MapReduce WordCount
MapReduce将作业的整个运行过程分为两个阶段:Map阶段Reduce阶段。
Map阶段由一定数量的Map Task组成,例如:
- 输入数据格式解析:InputFormat
- 输入数据处理:Mapper
- 数据分组:Partitioner
- 数据按照key排序
- 本地规约:Combiner(相当于local reducer,可选)
- 将任务输出保存在本地
Reduce阶段由一定数量的Reduce Task组成,例如:
- 数据远程拷贝
- 数据按照key排序
- 数据处理:Reducer
- 数据输出格式:OutputFormat
通常我们把从Mapper输出数据到Reduce读取数据之间的过程称之为shuffle。在shuffle过程中,我们把各个Mapper的相同Partitioner的数据拷贝到同一个Reducer机器节点上,进行合并和排序。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
//自定义Mapper类
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
//每次输入一行就会调用一次map方法
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
//自定义reducer类
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
//每次输入一次就会调用一次reduce方法
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
//执行方法
public static void main(String[] args) throws Exception {
//集群配置环境
Configuration conf = new Configuration();
//实例化一个Job
Job job = Job.getInstance(conf, "word count");
//设置启动类
job.setJarByClass(WordCount.class);
//设置mapper类
job.setMapperClass(TokenizerMapper.class);
//设置combiner类,一般与reducer类相同,相当于map local reducer
job.setCombinerClass(IntSumReducer.class);
//设置reducer类
job.setReducerClass(IntSumReducer.class);
//输出key类型
job.setOutputKeyClass(Text.class);
//输出value类型
job.setOutputValueClass(IntWritable.class);
//输入文件路径
FileInputFormat.addInputPath(job, new Path(args[0]));
//输出文件路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//等待任务完成,客户端再退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}二.MapReduce之Shell命令
1.mapred job
| -status job-id | 提交工作 |
| -submit job-file | 打印地图并减少完成百分比和所有作业计数器 |
| -counter job-id group-name counter-name | 打印计数器值 |
| -kill job-id | 杀死job |
| -list [all] jobOutputDir | 显示尚未完成的job。-list all显示所有job |
| -kill-task task-id | 杀死task |
| -set-priority job-id priority | 更改job的优先级。优先级值为VERY_HIGH,HIGH,NORMAL,LOW,VERY_LOW |
2.mapred queue [-list] | [-info <job-queue-name> [-showJobs]] | [-showacls]
| -list | 获取系统中配置的job queue列表 |
| -info job-queue-name [-showJobs] | 显示指定job queue的信息和相关的调度信息 |
| -showacls | 显示当前用户允许的队列名称和相应的队列操作。该列表仅包含用户有权访问的队列。 |
3.mapred historyserver
启动JobHistoryServer服务。也可以使用sbin/mr-jobhistory-daemon.sh start|stop historyserver来启动/停止JobHistoryServer。
4. mapred hsadmin [-refreshUserToGroupsMappings] | [-refreshSuperUserGroupsConfiguration] | [-refreshAdminAcls] | [-refreshLoadedJobCache] | [-refreshLogRetentionSettings] | [-refreshJobRetentionSettings] | [-getGroups [username]] | [-help [cmd]]
| -refreshUserToGroupsMappings | 刷新用户-组的对应关系 |
| -refreshSuperUserGroupsConfiguration | 刷新超级用户代理组映射 |
| -refreshAdminAcls | 刷新JobHistoryServer管理的ACL |
| -refreshLoadedJobCache | 刷新JobHistoryServer加载JOB的缓存 |
| -refreshJobRetentionSettings | 刷新Job histroy保留的设置 |
| -refreshLogRetentionSettings | 刷新日志保留周期和日志保留的检查间隔 |
| -getGroups [username] | 获取这个用户名属于哪个组 |
| -help [cmd] | 帮助 |
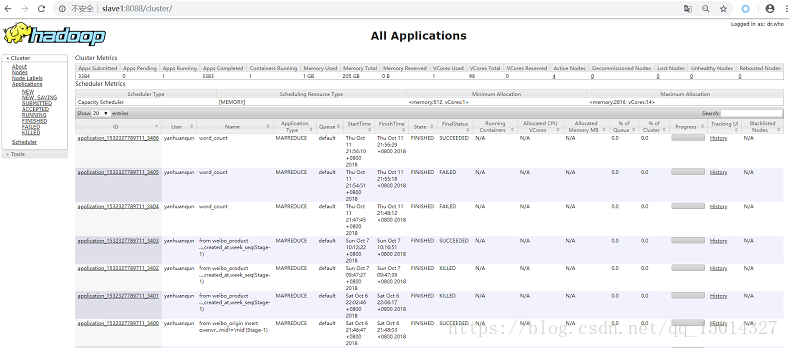
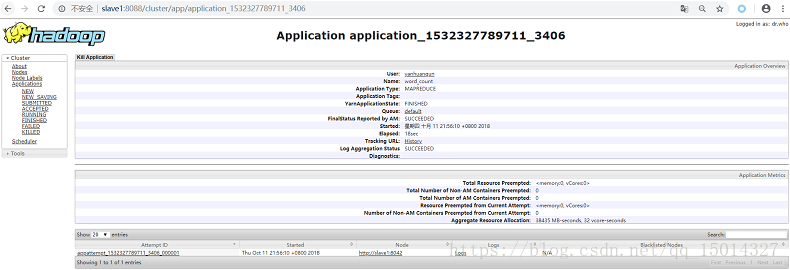
三.查看MapReduce执行日志