一 eclipse 上传文件到hdfs报错:
java.io.IOException: Could not get block locations. Source file "/1108/daxian/banzhang/kafka_2.12-2.0.0.tgz" - Aborting...
at org.apache.hadoop.hdfs.DataStreamer.setupPipelineForAppendOrRecovery(DataStreamer.java:1452)
at org.apache.hadoop.hdfs.DataStreamer.processDatanodeError(DataStreamer.java:1237)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:657)
解决:重新格式化hdfs
多次格式化hdfs会出现datanade无法启动的问题
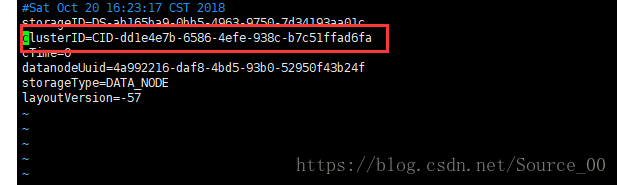
解决:修改clusterID
应该是由于namenode多次格式化造成了namenode和datanode的clusterID不一致!每次格式化时,namenode会更新clusterID,但是datanode只会在首次格式化时确定,因此就造成不一致现象。
进入/usr/local/hadoop/hadoop-2.8.5/hdfs/name/current目录下,查看VERSION文件中的clusterID
再进入/usr/local/hadoop/hadoop-2.8.5/hdfs/data/current,也是打开VERSION文件,将name中的clusterID的值复制过来,修改为一致。
重启hdfs
hdfs集群成功!
接下来继续运行上传文件的代码,如果还是失败,于是在集群上测试一下,
bin/hdfs dfs -put README.txt /
[root@master hadoop-2.8.5]# bin/hdfs dfs -put README.txt /
18/10/20 16:59:48 INFO hdfs.DataStreamer: Exception in createBlockOutputStream
java.io.IOException: Got error, status=ERROR, status message , ack with firstBadLink as 192.168.144.131:50010
at org.apache.hadoop.hdfs.protocol.datatransfer.DataTransferProtoUtil.checkBlockOpStatus(DataTransferProtoUtil.java:118)
at org.apache.hadoop.hdfs.DataStreamer.createBlockOutputStream(DataStreamer.java:1744)
at org.apache.hadoop.hdfs.DataStreamer.nextBlockOutputStream(DataStreamer.java:1648)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:704)
18/10/20 16:59:48 WARN hdfs.DataStreamer: Abandoning BP-412404355-192.168.144.130-1540022812837:blk_1073741837_1013
18/10/20 16:59:48 WARN hdfs.DataStreamer: Excluding datanode DatanodeInfoWithStorage[192.168.144.131:50010,DS-0c6f4180-1417-4dfd-9b8d-093a0236a3a0,DISK]
上传失败:提示貌似是slaver1的防火墙正在运行,所以关闭防火墙