从上一篇中我们学习了二叉树,接下来介绍我们常用的二叉查找树(BST)的一些基本操作插入删除查找及二叉树的遍历
1. 二叉搜索树定义
二叉搜索树(Binary Search Tree),又名二叉排序树(Binary Sort Tree)。
二叉搜索树是具有有以下性质的二叉树:
(1)若左子树不为空,则左子树上所有节点的值均小于或等于它的根节点的值。
(2)若右子树不为空,则右子树上所有节点的值均大于或等于它的根节点的值。
(3)左、右子树也分别为二叉搜索树。

2. 二叉搜索树的相关操作
通过不断插入操作,我们可以创建一个二叉查找树
2.1 插入操作
若当前的二叉查找树为空,则插入的元素为根结点,
从根节点开始,若插入的值比根节点的值小,则将其插入根节点的左子树;
若比根节点的值大,则将其插入根节点的右子树。
递归以上操作,直到找到插入点为叶子结点。
def insert(self, root, val):
'''二叉搜索树插入操作'''
if root == None:
root = TreeNode(val)
elif val < root.val:
root.left = self.insert(root.left, val)
elif val > root.val:
root.right = self.insert(root.right, val)
return root
2.2 查询操作
将当前结点cur赋值为根结点root;

从根节点开始查找,待查找的值是否与根节点的值相同,若相同则返回True;
否则,判断待寻找的值是否比根节点的值小,若是则进入根节点左子树进行查找,
否则进入右子树进行查找。递归上述过程,直到cur的值等于p的值或者cur为空;
程序代码:
def query(self, root, val):
'''二叉搜索树查询操作'''
if root == None:
return False
if root.val == val:
return True
elif val < root.val:
return self.query(root.left, val)
elif val > root.val:
return self.query(root.right, val)
2.3 查找二叉搜索树中的最大(小值)
(1)查找最小值:从根节点开始,沿着左子树一直往下,直到找到最后一个左子树节点,按照定义可知,该节点一定是该二叉搜索树中的最小值节点。
程序代码:
def findMin(self, root):
'''查找二叉搜索树中最小值点'''
if root.left:
return self.findMin(root.left)
else:
return root
(2)查找最大值:从根节点开始,沿着右子树一直往下,直到找到最后一个右子树节点,按照定义可知,该节点一定是该二叉搜索树中的最大值节点。
程序代码:
def findMax(self, root):
'''查找二叉搜索树中最大值点'''
if root.right:
return self.findMax(root.right)
else:
return root
2.4 删除节点操作
对二叉搜索树节点的删除操作分为以下三种情况:
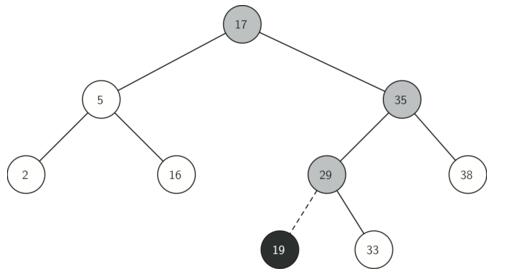
(1)删除叶子结点:待删除节点既无左子树也无右子树:直接删除该节点即可
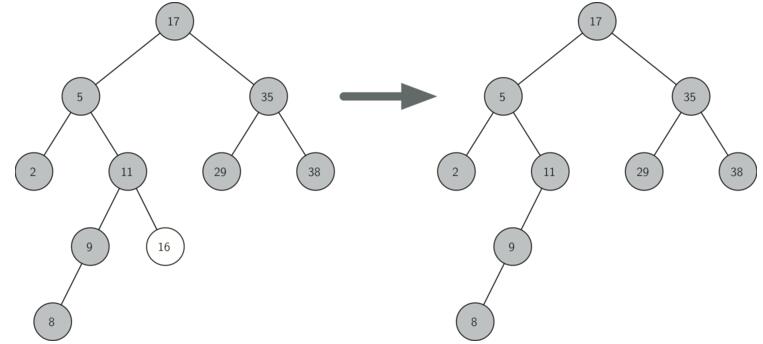
(2)删除单支结点:待删除节点只有左子树或者只有右子树:将其左子树或右子树根节点代替待删除节点
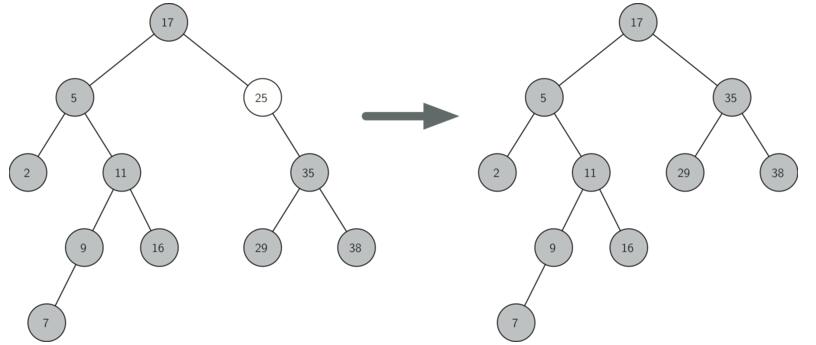
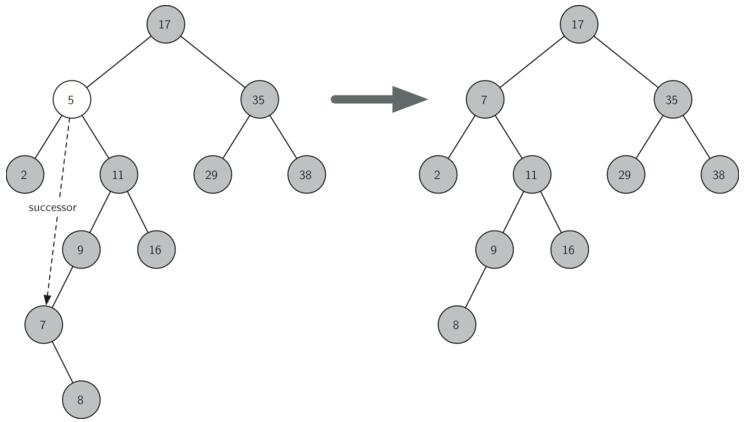
(3)待删除节点既有左子树也有右子树:找到该节点右子树中最小值节点,使用该节点代替待删除节点,然后在右子树中删除最小值节点。
若p的左子树和右子树均不空,则找到p的直接后继d(p的右孩子的最左子孙),因为d一定没有左子树,所以使用删除单支结点的方 法:
删除d,并让d的父亲结点dp成为d的右子树的父亲结点;同时,用d的值代替p的值;
也就是两步:1将p的直接后继d的值拷贝到p处 2 删除p的直接后继d
程序代码:
def delNode(self, root, val):
'''删除二叉搜索树中值为val的点'''
if root == None:
return
if val < root.val:
root.left = self.delNode(root.left, val)
elif val > root.val:
root.right = self.delNode(root.right, val)
# 当val == root.val时,分为三种情况:只有左子树或者只有右子树、有左右子树、即无左子树又无右子树
else:
if root.left and root.right:
# 既有左子树又有右子树,则需找到右子树中最小值节点
temp = self.findMin(root.right)
root.val = temp.val
# 再把右子树中最小值节点删除
root.right = self.delNode(root.right, temp.val)
elif root.right == None and root.left == None:
# 左右子树都为空
root = None
elif root.right == None:
# 只有左子树
root = root.left
elif root.left == None:
# 只有右子树
root = root.right
return root
2.5 打印操作
实现二叉搜索树的中序遍历,并打印出来。该方法打印出来的数列将是按照递增顺序排列。
程序代码:
def printTree(self, root):
# 打印二叉搜索树(中序打印,有序数列)
if root == None:
return
self.printTree(root.left)
print(root.val, end = ' ')
self.printTree(root.right)#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
二叉查找树的基本操作实现 插入 查找 删除
"""
class TreeNode:
"""二叉查找树的定义"""
def __init__(self, val):
self.val = val
self.left = None
self.right = None
class OperationTree:
def insert(self, root, val):
'''二叉搜索树插入操作'''
if root == None:
root = TreeNode(val)
elif val < root.val:
root.left = self.insert(root.left, val)
elif val > root.val:
root.right = self.insert(root.right, val)
return root
def query(self, root, val):
'''二叉搜索树查询操作'''
if root == None:
return False
if root.val == val:
return True
elif val < root.val:
return self.query(root.left, val)
elif val > root.val:
return self.query(root.right, val)
def findMin(self, root):
'''查找二叉搜索树中最小值点'''
if root.left:
return self.findMin(root.left)
else:
return root
def findMax(self, root):
'''查找二叉搜索树中最大值点'''
if root.right:
return self.findMax(root.right)
else:
return root
def delNode(self, root, val):
'''删除二叉搜索树中值为val的点'''
if root == None:
return
if val < root.val:
root.left = self.delNode(root.left, val)
elif val > root.val:
root.right = self.delNode(root.right, val)
# 当val == root.val时,分为三种情况:只有左子树或者只有右子树、有左右子树、即无左子树又无右子树
else:
if root.left and root.right:
# 既有左子树又有右子树,则需找到右子树中最小值节点
temp = self.findMin(root.right) # temp就是val的直接后继
root.val = temp.val
# 再把右子树中最小值节点删除
root.right = self.delNode(root.right, temp.val)
elif root.right == None and root.left == None:
# 左右子树都为空
root = None
elif root.right == None:
# 只有左子树
root = root.left
elif root.left == None:
# 只有右子树
root = root.right
return root
def printTree(self, root):
# 打印二叉搜索树(中序打印,有序数列)
if root == None:
return
self.printTree(root.left)
print(root.val, end=' ')
self.printTree(root.right)
if __name__ == '__main__':
List = [17, 5, 35, 2, 11, 29, 38, 9, 16, 8]
root = None # 定义根结点
op = OperationTree()
for val in List:
root = op.insert(root, val)
print('中序打印二叉搜索树:', end=' ')
op.printTree(root)
print('')
print('根节点的值为:', root.val)
print('树中最大值为:', op.findMax(root).val)
print('树中最小值为:', op.findMin(root).val)
print('查询树中值为5的节点:', op.query(root, 5))
print('查询树中值为100的节点:', op.query(root, 100))
print('删除树中值为16的节点:', end=' ')
root = op.delNode(root, 16)
op.printTree(root)
print('')
print('删除树中值为5的节点:', end=' ')
root = op.delNode(root, 5)
op.printTree(root)
print('')
3、二叉树的遍历

3.1、前序遍历
递归实现思路:先处理当前节点的值,然后将左子节点递归处理,最后将右子节点递归处理。
//先序遍历(递归)
def PreOrder(self, root):
'''打印二叉树(先序)'''
if root == None:
return
print(root.val, end=' ')
self.PreOrder(root.left)
self.PreOrder(root.right)
非递归实现思路:使用栈来保存需要返回后处理的节点。
- 如果当前节点存在,则处理当前节点的value(先处理根节点的值),然后将当前节点入栈,当前节点指向leftChild,并对leftChild(此时的当前节点)进行相同处理。重复1
- (当前节点不存在)当前节点指向栈顶元素,栈顶元素出栈,当前节点指向rightChild,并对rightChild(此时的当前节点)进行相同处理。重复1
//先序遍历(非递归)
void pre_visit(BTree* root){
std::stack<BTree*> stack_tree; //使用栈来保存需要返回再处理的元素
BTree* cur_node = root; //定义一个指针用来指向当前节点
while(cur_node != NULL || !stack_tree.empty()){
if(cur_node != NULL){
std::cout << cur_node->value.c_str() << "\t"; //处理当前节点的值
stack_tree.push(cur_node); //当前节点入栈
cur_node = cur_node->leftChild; //指向左子节点,进行相同处理
}
else{
cur_node = stack_tree.top(); //指向栈顶元素,这里不会将栈顶元素出出栈
stack_tree.pop(); //栈顶元素出栈
cur_node = cur_node->rightChild; //指向右子节点,进行相同处理
}
}
}def pre_deep_func2(root):
a = []
while a or root:
while root:
print root.value
a.append(root)
root = root.left
h = a.pop()
root = h.right3.2、中序遍历
遍历顺序:左子节点 - 根节点 - 右子节点
递归实现思路:先将左子节点进行递归处理,然后处理当前节点的值,最后将右子节点进行递归处理。
//中序遍历(递归)
def InOrder(self, root):
'''中序打印'''
if root == None:
return
self.InOrder(root.left)
print(root.val, end=' ')
self.InOrder(root.right)非递归实现思路:只用栈来保存需要返回处理的节点。与先序遍历类似。
- 如果当前节点存在,则当前节点入栈,指向leftChild,并leftChild(此时的当前节点)进行相同处理。重复1
- (当前节点不存在)当前指向栈顶元素,栈顶元素出栈,处理当前节点值(因为左子节点不存在或者已经处理完了),指向rightChild,并对rightChild(此时的当前节点)进行相同处理。重复1
//中序遍历(非递归)
void mid_visit(BTree* root){
std::stack<BTree*> stack_tree;
BTree* cur_node = root;
while(cur_node != NULL || !stack_tree.empty()){
if(cur_node != NULL) {
stack_tree.push(cur_node); //当前节点入栈
cur_node = cur_node->leftChild; //指向左子节点,进行相同处理
}
else{
cur_node = stack_tree.top(); //指向栈顶节点
stack_tree.pop(); //栈顶节点出栈
std::cout << cur_node->value.c_str() << "\t"; //处理当前节点的值
cur_node = cur_node->rightChild; //指向右子节点,进行相同处理
}
}
}
def mid_deep_func2(root):
a = []
while a or root:
while root:
a.append(root)
root = root.left
h = a.pop()
print h.value
root = h.right3.3、后序遍历
遍历顺序:左子节点 - 右子节点 - 根节点
递归实现思路:先将左子节点进行递归处理,再将右子节点进行递归处理,最后处理当前节点的值。
//后序遍历(递归)
def BacOrder(self, root):
'''后序打印'''
if root == None:
return
self.BacOrder(root.left)
self.BacOrder(root.right)
print(root.val, end=' ')非递归实现思路:使用栈来保存需要返回处理的节点。这里用到了两个栈,一个用于存放二叉树节点,一个用于存放标志位,0表示处理了左子节点,1表示处理了右子节点。
后序遍历与前两者不同,前两者在代码逻辑上区分处理了左、右子节点(即压栈时,就已经处理过了左子节点,出栈后直接指向右子节点即可),但是后续遍历存在着需要区分是否处理过左子节点的问题(压栈时左右子节点都没有先处理过,需要等待左右子节点均处理完后才能处理根节点的值),所以需要添加标识来判断当前是否已经处理过左右子节点。
- 如果当前节点存在,则当前节点入栈,指向leftChild,标识0入栈,并对leftChild(此时的当前节点)进行相同处理。重复1
- (当前节点不存在)指向栈顶元素,栈顶元素出栈,标志位出栈。如果标志位为0,则当前节点入栈,指向rightChild,标识1入栈,并对rightChild(此时的当前节点)进行步骤1的处理,重复1;如果标志位为1,则说明处理过了左右子节点,此时处理当前节点的value,继续对栈顶元素进行相同处理(当前节点置空,重复步骤2,重复2)。
//后序遍历(非递归)
void post_visit(BTree* root)
{
std::stack<BTree*> stack_tree; //保存需要返回处理的节点
std::stack<int> stack_flag; //保存返回的路径标识
BTree* cur_node = root;
while(cur_node != NULL || !stack_tree.empty())
{
if(cur_node != NULL)
{
stack_tree.push(cur_node); //当前节点入栈
stack_flag.push(0); //下一步处理leftChild,返回时从leftChild返回,保存标识为0
cur_node = cur_node->leftChild; //指向leftChild,进行步骤1处理
}
else
{
cur_node = stack_tree.top(); //指向栈顶元素
stack_tree.pop(); //节点出栈
int flag = stack_flag.top(); //获取返回路径
stack_flag.pop(); //标识出栈
if(flag == 0)
{
//从leftChild返回,此时应该处理rightChild
stack_tree.push(cur_node); //当前节点入栈
stack_flag.push(1); //下一步处理rightChild,保存标识1
cur_node = cur_node->rightChild; //指向rightChild,进行步骤1处理
}
else
{
//从rightChild返回,此时应该处理根节点的值
std::cout << cur_node->value.c_str() << "\t"; //处理根节点的值
cur_node = NULL; //为了进行步骤2,根据循环逻辑,这里要将cur_node置空
}
}
}
}
def after_deep_func2(root):
a = []
b = []
while a or root:
while root:
b.append(root.value)
a.append(root)
root = root.right
h = a.pop()
root = h.left
print b[::-1]后续遍历中,root节点最后才能被访问到,因此,栈能记录每一个节点的路径,包括叶子节点。这一点性质可用于求解和树的路径有关的问题。
3.4、层序遍历
层序遍历的思想和之前三种遍历方式不同,需要借助queue来对节点进行缓存,先进队列的节点需要先离开。
def BFS(self, root):
'''广度优先'''
if root == None:
return
# queue队列,保存节点
queue = []
# res保存节点值,作为结果
# vals = []
queue.append(root)
while queue:
# 拿出队首节点
currentNode = queue.pop(0)
# vals.append(currentNode.val)
print(currentNode.val, end=' ')
if currentNode.left:
queue.append(currentNode.left)
if currentNode.right:
queue.append(currentNode.right)
# return vals层序遍历思想简单,利用queue来一层一层输出。因此,可用于求解树的宽度和高度。
#求树的深度
#利用广度优先遍历
def get_level_func1(root):
a = []
b = []
a.append(root)
b.append(1)
while a:
head = a.pop(0)
p = b.pop(0)
if head.left:
a.append(head.left)
b.append(p+1)
if head.right:
b.append(p+1)
a.append(head.right)
return p
#递归方法
def get_level_func2(root):
if not root:
return 0
left = right = 0
left = get_level_func2(root.left)
right = get_level_func2(root.right)
return max(left, right) + 1最后测试用的代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
二叉树的前序中序后序,深度广度遍历
"""
# 二叉树的实现
class TreeNode:
'''二叉树节点的定义'''
def __init__(self, val):
self.val = val
self.left = None
self.right = None
class OperationTree:
'''二叉树操作'''
def create(self, List):
'''二叉树插入操作'''
root = TreeNode(List[0])
lens = len(List)
if lens >= 2:
root.left = self.create(List[1])
if lens >= 3:
root.right = self.create(List[2])
return root
def query(self, root, data):
'''二叉树查找操作'''
if root == None:
return False
if root.val == data:
return True
elif root.left:
return self.query(root.left, data)
elif root.right:
return self.query(root.right, data)
def PreOrder(self, root):
'''打印二叉树(先序)'''
if root == None:
return
print(root.val, end=' ')
self.PreOrder(root.left)
self.PreOrder(root.right)
def InOrder(self, root):
'''中序打印'''
if root == None:
return
self.InOrder(root.left)
print(root.val, end=' ')
self.InOrder(root.right)
def BacOrder(self, root):
'''后序打印'''
if root == None:
return
self.BacOrder(root.left)
self.BacOrder(root.right)
print(root.val, end=' ')
def BFS(self, root):
'''广度优先'''
if root == None:
return
# queue队列,保存节点
queue = []
# res保存节点值,作为结果
# vals = []
queue.append(root)
while queue:
# 拿出队首节点
currentNode = queue.pop(0)
# vals.append(currentNode.val)
print(currentNode.val, end=' ')
if currentNode.left:
queue.append(currentNode.left)
if currentNode.right:
queue.append(currentNode.right)
# return vals
def DFS(self, root):
'''深度优先'''
if root == None:
return
# 栈用来保存未访问节点
stack = []
# vals保存节点值,作为结果
# vals = []
stack.append(root)
while stack:
# 拿出栈顶节点
currentNode = stack.pop()
# vals.append(currentNode.val)
print(currentNode.val, end=' ')
if currentNode.right:
stack.append(currentNode.right)
if currentNode.left:
stack.append(currentNode.left)
# return vals
if __name__ == '__main__':
List1 = [1, [2, [4, [8], [9]], [5]], [3, [6], [7]]]
op = OperationTree()
tree1 = op.create(List1)
print('先序打印:', end='')
op.PreOrder(tree1)
print("")
print('中序打印:', end='')
op.InOrder(tree1)
print("")
print('后序打印:', end='')
op.BacOrder(tree1)
print("")
print('BFS打印 :', end='')
bfs = op.BFS(tree1)
# print(bfs)
print("")
print('DFS打印 :', end='')
dfs = op.DFS(tree1)
# print(dfs)
print("")
4、树的遍历问题
4.1、已知前序、中序遍历,求后序遍历

画树求法:
第一步,根据前序遍历的特点,我们知道根结点为G
第二步,观察中序遍历ADEFGHMZ。其中root节点G左侧的ADEF必然是root的左子树,G右侧的HMZ必然是root的右子树。
第三步,观察左子树ADEF,左子树的中的根节点必然是大树的root的leftchild。在前序遍历中,大树的root的leftchild位于root之后,所以左子树的根节点为D。
第四步,同样的道理,root的右子树节点HMZ中的根节点也可以通过前序遍历求得。在前序遍历中,一定是先把root和root的所有左子树节点遍历完之后才会遍历右子树,并且遍历的左子树的第一个节点就是左子树的根节点。同理,遍历的右子树的第一个节点就是右子树的根节点。
第五步,观察发现,上面的过程是递归的。先找到当前树的根节点,然后划分为左子树,右子树,然后进入左子树重复上面的过程,然后进入右子树重复上面的过程。最后就可以还原一棵树了。
我们可以画出这个二叉树的形状:
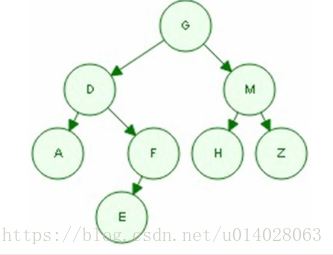
那么,根据后序的遍历规则,我们可以知道,后序遍历顺序为:AEFDHZMG
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
'''
根据二叉树的前序 中序遍历 求其后序遍历
'''
class Node(object):
def __init__(self, value=None, left=None, right=None):
self.value = value
self.left = left
self.right = right
def get_tree(pre, mid):
if len(pre) == 0:
return None
if len(pre) == 1:
return Node(pre[0])
root = Node(pre[0])
root_index = mid.index(pre[0])
root.left = get_tree(pre[1:root_index + 1], mid[:root_index])
root.right = get_tree(pre[root_index + 1:], mid[root_index + 1:])
return root
def get_after_deep(pre, mid, a):
if len(pre) == 1:
a.append(pre[0])
return
if len(pre) == 0:
return
root = pre[0]
root_index = mid.index(root)
get_after_deep(pre[1:root_index+1], mid[:root_index], a)
get_after_deep(pre[root_index+1:], mid[root_index+1:], a)
a.append(root)
return a
# 前序遍历(递归)
def pre_deep_func(root):
if root is None:
return
print(root.value,end =' ') # print 放到下一行 就是中序遍历,放到最后 就是后序遍历
pre_deep_func(root.left)
pre_deep_func(root.right)
def after_deep_func2(root):
a = []
b = []
while a or root:
while root:
b.append(root.value)
a.append(root)
root = root.right
h = a.pop()
root = h.left
print(b[::-1])
if __name__ == '__main__':
# 已知的树的前序与中序遍历
# pre = [1, 2, 4, 5, 8, 9, 11, 3, 6, 7, 10]
# mid = [4, 2, 8, 5, 11, 9, 1, 6, 3, 10, 7]
pre = ['G','D','A','F','E','M','H','Z']
mid = ['A','D','E','F','G','H','M','Z']
# 方法一:通过前序中序而画出树,然后后序遍历该树
head = get_tree(pre, mid)
print ("方法一:通过前序中序而画出树,然后后序遍历该树:")
after_deep_func2(head)
# 方法二:通过前序中序直接递归得到其后序遍历
print("方法二:通过前序中序直接递归得到其后序遍历")
res = get_after_deep(pre, mid, [])
print(res)#res = [4, 8, 11, 9, 5, 2, 6, 10, 7, 3, 1]
输出的结果为:AEFDHZMG
方法二:通过前序中序直接递归得到其后序遍历
['A', 'E', 'F', 'D', 'H', 'Z', 'M', 'G']4.2、已知中序和后序遍历,求前序遍历
中序遍历: ADEFGHMZ
后序遍历: AEFDHZMG
画树求法:
第一步,根据后序遍历的特点,我们知道后序遍历最后一个结点即为根结点,即根结点为G。
第二步,观察中序遍历ADEFGHMZ。其中root节点G左侧的ADEF必然是root的左子树,G右侧的HMZ必然是root的右子树。
第三步,观察左子树ADEF,左子树的中的根节点必然是大树的root的leftchild。在前序遍历中,大树的root的leftchild位于root之后,所以左子树的根节点为D。
第四步,同样的道理,root的右子树节点HMZ中的根节点也可以通过前序遍历求得。在前后序遍历中,一定是先把root和root的所有左子树节点遍历完之后才会遍历右子树,并且遍历的左子树的第一个节点就是左子树的根节点。同理,遍历的右子树的第一个节点就是右子树的根节点。
第五步,观察发现,上面的过程是递归的。先找到当前树的根节点,然后划分为左子树,右子树,然后进入左子树重复上面的过程,然后进入右子树重复上面的过程。最后就可以还原一棵树了。
可以画出二叉树的形状
#通过中序后序求前序遍历
def get_pre_deep(post, mid, a):
if len(post) == 0 or len(mid) == 0:
return
a = [post[-1],]
root = post[-1]
root_index = mid.index(root)
# 遍历左子树
root_left = get_pre_deep(post[0:root_index], mid[0:root_index], a)
# 遍历右子树
root_right = get_pre_deep(post[root_index:-1], mid[root_index+1:], a)
# 把所得到的结点连接,把返回结果为空的情况剔除
if root_left is not None and root_right is not None:
# 注意这两个值的连接顺序(和已知前序和中序相反)
a.extend(root_left)
a.extend(root_right)
elif root_left is not None:
a.extend(root_left)
elif root_right is not None:
a.extend(root_right)
# a.append(root)
return a
if __name__ == '__main__':
print("问题二:通过后序中序直接递归得到其前序遍历为:")
post = ['A', 'E', 'F', 'D', 'H', 'Z', 'M', 'G']
mid = ['A', 'D', 'E', 'F', 'G', 'H', 'M', 'Z']
pre = get_pre_deep(post, mid, [])
print(pre)输出结果:GDAFEMHZ
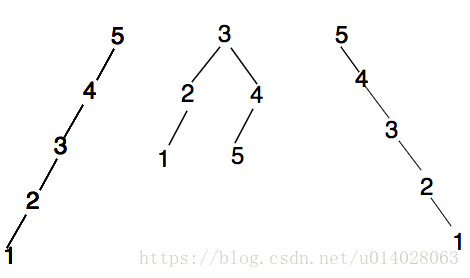
4.3、思考

题中说明是二叉查找树说明其中序是一个升序的排列,隐含告知了中序情况,根据中序后序看是否可以画出一个树,1,3,4构造的树如下,2不可以
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
判断该序列是否是二叉查找树的后序遍历 如1,2,5,4,3
由于后序遍历的最后一个元素为根结点,根据该结点,将数组分成前后两段,使得前半段都小于根结点,后半段都大于根结点;
如果不存在这样的划分,则不可能是后序遍历的结果。
递归判断前后半段是否满足同样的要求。
"""
def IsPostOrder(a, n):
if n <=0:
return False
root = a[-1]
nleft = 0 #在二叉搜索树中的左子树的节点小于根节点
for nleft in range(0,n):
if a[nleft] > root:
break
nRight = nleft #在二叉搜索树中的右子树的节点大于根节点
for nRight in range(nleft,n):
if a[nRight] < root:
return False
left = True #判断左子树是不是二叉搜索树
if nleft > 0:
left = IsPostOrder(a[0:nleft],nleft)
right = True #判断右子树是不是二叉搜索树
if nRight < n-1:
right = IsPostOrder(a[nleft:],n- nleft-1)
return left and right
if __name__ == '__main__':
# post = [1,2,3,4,5]
# post = [5,4,3,2,1]
# post = [3,5,1,4,2]
# post = [1,2,5,4,3]
post = [5,6,4,10,12,7,8]
# post = [5,6,4,10,14,12,8]
is_postOrder = IsPostOrder(post, len(post))
print(is_postOrder)
4.4、已知前序后序,无法唯一确定中序
给定一棵二叉树的前序和后序,无法确定其中序遍历序列,考虑如下图中的几棵二叉树:

所有这些二叉树都有着相同的前序遍历abc和后序遍历cba,但中序遍历却不相同。
一般会遇到这样的问题,求中序遍历可能出现的情况
如:输入文件共2行,第一行表示该树的前序遍历结果,第二行表示该树的后序遍历结果。输入的字符集合为{a-z},长度不超过26。abc和cba
求解: 输出文件只包含一个不超过长整型的整数,表示可能的中序遍历序列的总数。4
解题思路:
在求解这题之前得先了解一些基础知识:
前序遍历:根结点 ---> 左子树 ---> 右子树
中序遍历:左子树---> 根结点 ---> 右子树
后序遍历:左子树 ---> 右子树 ---> 根结点
由以上的前中后遍历顺序可以看出在已知前序遍历和后序遍历的情况下,中序遍历不是唯一确定的。而且中序遍历的不确定性是由一个节点(只有一边子树)的左右子树的不确定性决定的。例如前序遍历ab,后序遍历ba,a为根,b为子树,在中序遍历中如果b为左子树,则中序遍历为ba;如果b为右子树,则中序遍历为ab。所以当这种节点有n个时,中序遍历的可能性就有2^n;
那么问题就转变为如果确定这种节点的数量。可以总结出一个规律,如上例。前序遍历为ab,后序遍历为ba,此时无法确定b是为左子树还是右子树,那么就产生了一个特殊节点。所以规律就是(此时a,b分别为前序遍历和后序遍历的字符串):
a[i]==b[j]时,a[i+1]==b[j-1]则产生一个特殊节点
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
已知前序后序,求中序可能出现的次数
前序遍历为ab,后序遍历为ba,此时无法确定b是为左子树还是右子树,那么就产生了一个特殊节点。当这种节点有n个时,中序遍历的可能性就有2^n
a[i]==b[j]时,a[i+1]==b[j-1]则产生一个特殊节点
"""
def CountMidOrder(pre,post):
res,count = 0, 0
if len(pre) == 0 or len(post) == 0:
return
if len(pre) == 1 or len(post) == 1:
res = 1
for i in range(len(pre)):
for j in range(1, len(post)):
if pre[i] == post[j] and pre[i+1] == post[j-1]:
count += 1
res = pow(2,count)
return res
if __name__ == '__main__':
pre = ['a', 'b', 'c']
post = ['c', 'b', 'a']
res = CountMidOrder(pre,post)
print('该前序后序遍历下,中序遍历可能出现的情况个数为:',res)题目:大整数845678992357836701转化成16进制表示,最后两位字符是?
解析:16进制就是4位二进制,所以将大整数化为2进制以后取后八位即可。大整数的倒数第四位为6,说明这之前的数均能被2整除,所以只需要将后三位701化成二进制,取二进制数的后8位组成两位16进制即可。答案是9D。