1.使用新的网络层做高层contextual aggregation
《RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation》
https://github.com/guosheng/refinenet
ResNet用于语义分割存在的问题是特征图是降采样的32倍,丢失了很多细节信息,得到的分割结果比较粗糙。这里将粗糙的高层语义特征和细粒度的低层特征融合。用ResNet按feature map的分辨率分成四个ResNet blocks,并作为四个path通过RefineNet进行融合,最终实现了高精度的语义分割。这里使用了较多Resisual模块,
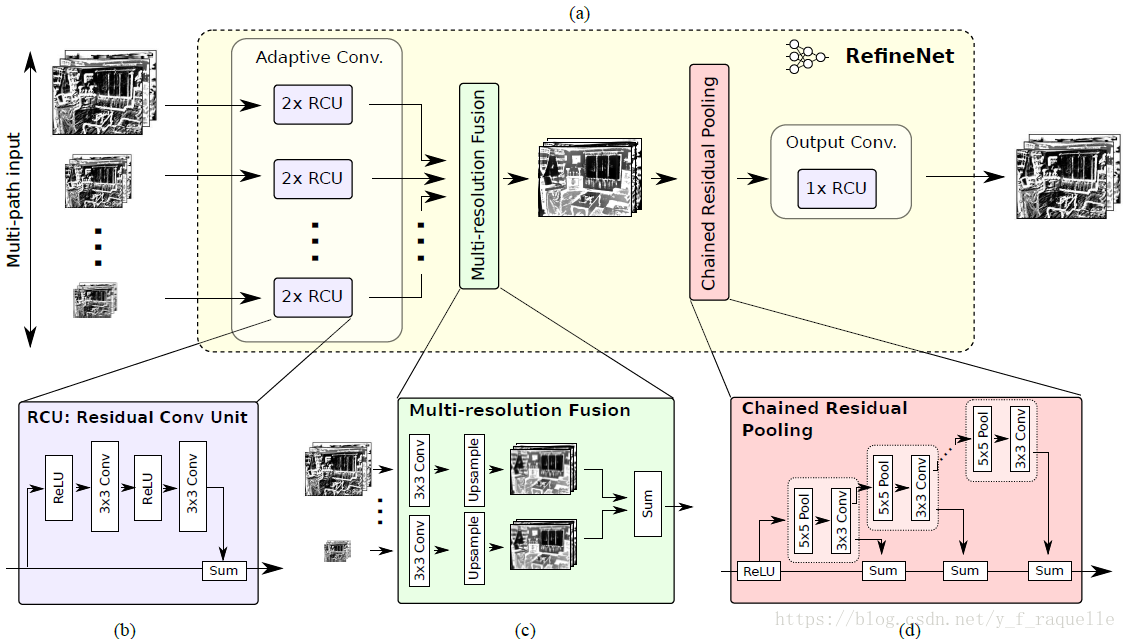
不同尺度的特征输入分别通过两个Residual模块抽取低层特征;然后将不同尺度的特征进行融合,所有特征上采样到最小的尺寸再进行加和获得中间层特征;之后通过一个链式残差池化层获得高层特征,将不同尺度特征卷积加权得到背景上下文;最后再通过一个Residual模块。
《Pyramid Scene Parsing Network》
https://github.com/hszhao/PSPNet
引入了不同尺度上下文信息做像素级别的标注,结合local和global的信息,减少了关系不匹配、类别混淆、相似外形颜色物体的误识别。Pyramid池化模块通过全局平均池化获取全局上下文信息。
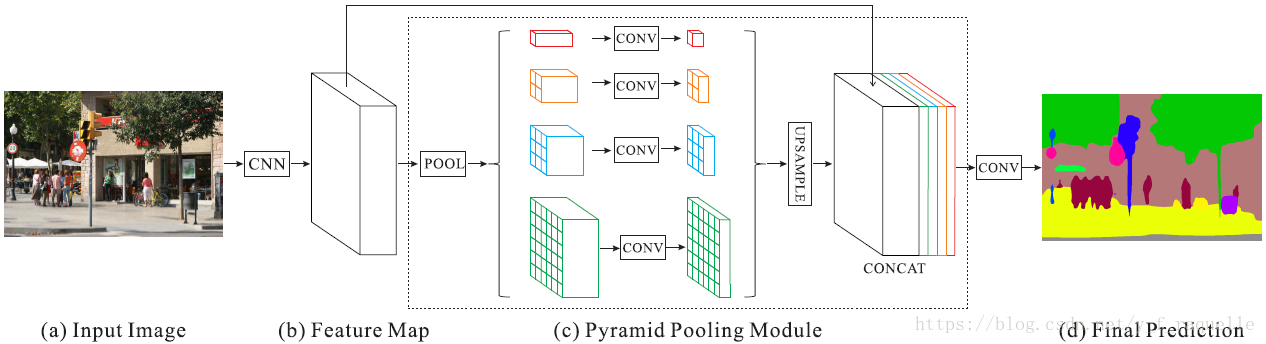
pyramid level将通过ResNet提取的feature map(原图的1/8大小)分成不同的子区域,得到不同位置的池化特征表示,不同level的输出包含了不同尺寸的feature map。各pyramid level后用1x1的卷积层对上下文特征降维,保持全局特征的权重。对低维feature maps进行双线性差值的upsampling,得到与原始feature maps一样的尺寸大小。连接不同level的features得到最终全局特征。

《Multi-scale Context Aggregation by Dilated Convolutions》
https://github.com/fyu/dilation
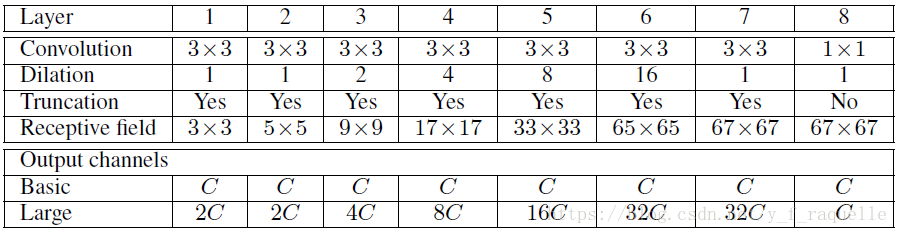
使用了空洞卷积,能够增大感受野,融合多尺度的上下文信息,同时不会降低feature map的大小。文中通过简化的VGG16、上下文模块(多尺度内容信息聚合)和CRF进行分割。上下文模块的输入是C个feature maps,输出也是C个feature maps,各层具有C个通道。
《ReSeg: A Recurrent Neural Network-based Model for Semantic Segmentation》
https://github.com/Wizaron/reseg-pytorch
输入图片通过VGG16的第一层,得到的feature map输入到一个或多个循环层扫描图片,再用一个或多个上采样层得到和原图大小一样的图片,用一个softmax来预测每个像素的分布概率。

每个循环层有4个RNN来获取局部和全局空间结构,先从上到下/从下到上垂直扫描,然后从左到右/从右到左水平扫描获得图片特征。
《Scene Segmentation with DAG-Recurrent Neural Networks》
使用了DAG-RNN来对局部feature maps做context aggregation,获得图片区域的上下文依赖。首先通过一个CNN输出像素的compact and discriminative表示,导出特征;然后通过上下文聚合模块得到局部特征的额外上下文;特征图的上采样用于恢复降采样过程中的细节。

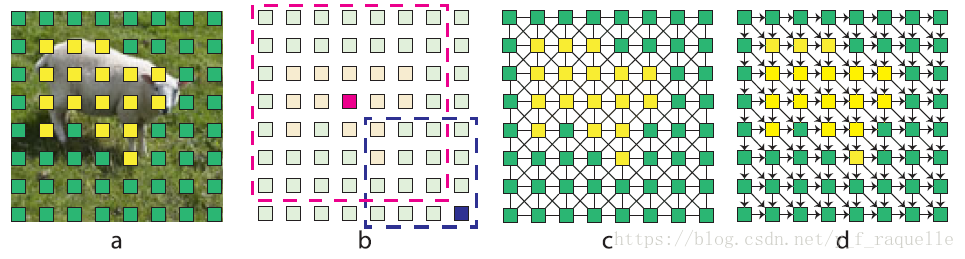
上图每一个小方块表示一个特征张量,b中的卷积核用于聚合局部特征的上下文,局部特征用一个八邻域UCG连接,每对特征都互相可达,d图表示东南方向的导向有向无环图。上下文聚合就是在DAG拓扑上通过传播局部上下文来实现的。
2.使用CRF对score map做类别标注
《Conditional Random Fields as Recurrent Neural Networks》
传统的用于Object Recognition的CNN很难转换为用于segmentation的像素级标注:感受野过大以及池化操作使得feature map很粗糙,缺少smooth机制,导致物体轮廓不准确和假区问题。
概率图模型常常被用于提高像素级标注的精确度,主要是MRF和CRF。CRF预测的主要思想是: 把像素的标签标注问题转化为概率预测问题,其中包含了类似像素之间的标签一致等假设。CRF预测能够提取弱的、粗糙的预测来产生锐利边缘和精密细纹的分割。
本文的原理是利用平均场近似CRFs的过程转化为RNN,并把CRF-RNN嵌入到CNNs中,进行forwardpropogation和backpropogation来训练模型。
构造一个类RNN单元:

将从CNN得到的prediction map经过initialization,每次迭代经过五个步骤:
1.信息传递,即使用m个滤波器分别对每一个类别l的概率图Qi(l)进行滤波。
2.滤波结果加权相加,对每一个类别l的m个滤波结果根据权重ω(m)相加。
3.类别兼容性转换,对每一个类别l的概率图根据不同类别之间的兼容性矩阵μ(l,l’)进行更新。
4.加上数据项(一元项 Unary Potential)。
5.归一化,对各像素所属不同类别l的概率归一化,实际上是一个softmax的过程。
《Scene Labeling with LSTM Recurrent Neural Networks》
采用二维LSTM-RNN来做场景标注。输入图片被分为多个nxn、3通道的非重叠的窗口网格,导入四个分开的LSTM memory blocks。LSTM block的当前窗口与周围x、y方向相连接,传播到周围的上下文。每个LSTM block的输出传递到用于综合所有方向的Feedforward层,并使用tanh对其做squash。最后一一层中最终LSTM blocks的输出都加起来并发送到softmax层。最终,网络输出每个输入窗口的类别概率。

《Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials》
在多类别图像分割和标记领域表现最优的技术采用的都是定义在像素或者图像域之上的条件随机场。CRF势函数合并了在相似像素中最大化标签一致性的平滑项,并且可以整合建模各类别间上下文关系的更加复杂的项。这篇论文中,提出选择使用一张图像中的完全像素集的全连接CRFs模型,但是这种结果图边太多,传统的判别算法不再合适,本文提出一种全连接CRF模型的近似判别算法,其中二元的边缘势函数被定义为两个高斯核的线性组合。
1.平均场近似
这种近似法产生了一个迭代的消息传递,使用特征空间的高斯滤波进行。使用高有效的近似法来进行高斯滤波,减少从二次到线性的消息传递的复杂性,由此得出了全连接CRFs的一个近似推算算法,这个算法在变量N中是线性的并且在模型的边缘数中是亚线性的。平均场算法近似计算了一个分布Q。

2.高维滤波的有效信息传递
算法1中的每次迭代都执行了一个消息传递步骤、一个兼容性转换和一个局部更新。消息传递可以表达为一个在特征空间中使用高斯核的卷积过程。

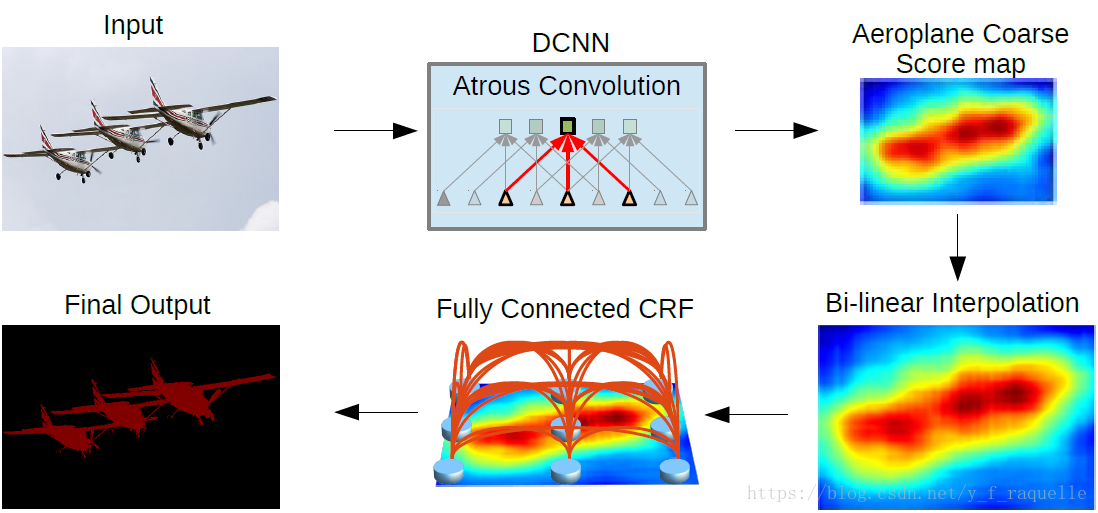
《DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs》
http://liangchiehchen.com/projects/DeepLab.html
DCNN把VGG-16的全连接层改成卷积层,池化的4、5步长改为1,尺寸变为1/8,感受野发生变化,本文提出hole算法,pool4之后三个卷积层hole size为2,pool5之后的全卷积层hole size为4并且卷积核直接降采样。
越深的网络分类越精确,但是因为不变性和大感受野导致定位不精确,在升采样之后加入CRF精细化边缘信息。能量函数为:

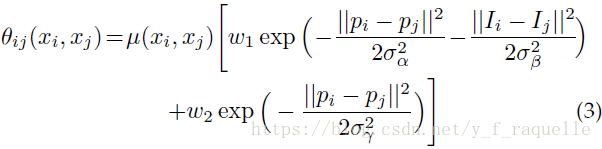
前一项代表像素的内聚程度(P(xi)表示DCNN输出的score map在i这个像素上真实标签的概率),后一项代表相邻结点的相关程度(二元能量项描述像素点与像素点之间的关系,鼓励相似像素分配相同的标签,相差较大的像素分配不同标签,这个距离的定义与颜色值和实际相对距离有关,二元势函数描述的是每个像素与其他所有像素的关系,所以叫“全连接”)。对每一个类求解E(x),当取到最小时像素值最稳定。
《Semantic Image Segmentation via Deep Parsing Network》
https://liuziwei7.github.io/projects/DPN.html
结合CNN和MRF(Deep Parsing Network),包括了高层关系和标签上下文的混合。MRF的公式定义和CRF类似,但是对二元势函数进行了修改:



DPN扩展了CNN架构来建模unary term,额外的层设计为适合pairwise term的平均场算法。DPN能够通过联合domain knowledge对MRF中的结点动态链接。

《Efficient Piecewise Training of Deep Structured Models for Semantic Segmentation》
使用上下文信息提高语义分割,本文使用图片区域的‘patch-patch’和‘patch-background’的上下文。在从‘patch-patch’的学习过程中,本文使用基于CNN的成对势能函数传递CRFs来捕获相邻块中的语义相关性,和其他使用CRFs来勾勒区域边界不同,本文的CNN成对势能主要是为了提高coarse-level的预测。为了捕获‘patch-background’上下文,本文使用了传统的多尺度图片输入和滑动金字塔池化的网络来捕获背景信息。由于成对势能在预测阶段耗时较多,本文为了高效学习,使用pecewise的方法训练CRF。

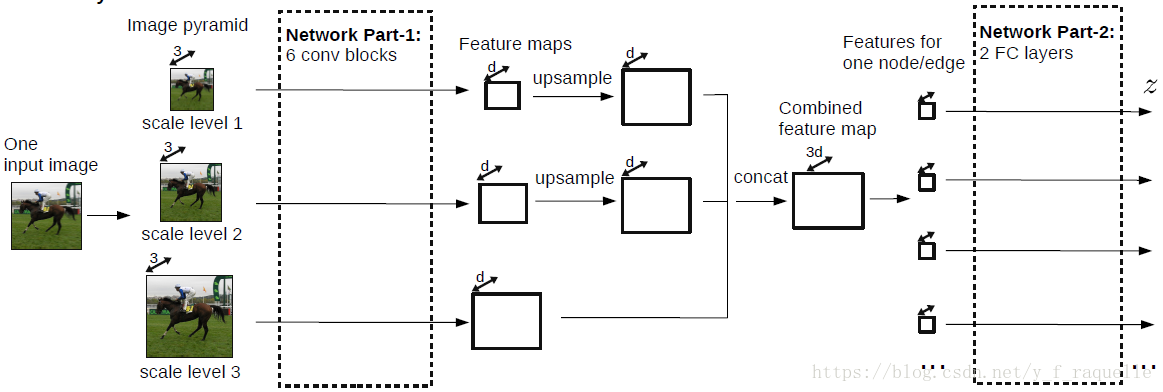

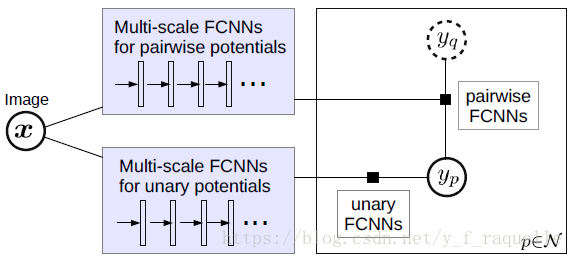
输入图片首先resize成3种尺度,然后每个图片经过6个卷积blocks,输出3个feature maps。然后构造一个CRF,其中结点和边的特征都从feature maps种获得。结点和边特征通过一个网络来生成unary/pairwise potential network输出。最后,训练状态下网络输出导入一个CRF loss function,预测状态下导入MAP inference objective。
参考链接:
https://blog.csdn.net/Suan2014/article/details/79669184
https://blog.csdn.net/qq_36165459/article/details/78345269
https://blog.csdn.net/melpancake/article/details/54143319
http://www.cnblogs.com/everyday-haoguo/p/Note-PSPNet.html
https://blog.csdn.net/zziahgf/article/details/73294753
https://blog.csdn.net/zziahgf/article/details/77947565
https://www.zhihu.com/question/54149221
https://blog.csdn.net/zhangjunhit/article/details/70157920
https://www.jianshu.com/p/2f30c59cc17e
https://blog.csdn.net/u014451076/article/details/71189885
https://blog.csdn.net/taigw/article/details/51794283
https://blog.csdn.net/meanme/article/details/50838769
https://blog.csdn.net/ahnu120705097/article/details/78913675
https://blog.csdn.net/chenyj92/article/details/53448161
https://blog.csdn.net/yxq5997/article/details/53693869
https://blog.csdn.net/u014451076/article/details/70666636
https://zhuanlan.zhihu.com/p/22308032
http://www.voidcn.com/article/p-donnjuta-bgd.html
更多semantic segmentation:
https://blog.csdn.net/Julialove102123/article/details/80493066
https://zhuanlan.zhihu.com/p/27794982